
Users Online
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
Forum Threads
Latest Articles
Articles Hierarchy
Skill 2.7: Implement Azure Search
Skill 2.7: Implement Azure Search
Skill 2.7: Implement Azure Search
Azure Search is a Platform-as-a-Service (PAAS) offering that gives developers APIs needed to add search functionality in their applications. Primarily this mean full text search. The typical example is how Google and Bing search works. Bing doesn’t care what tense you use, it spell checks for you, and finds similar topics based on search terms. It also offers term highlighting and can ignore noise words, as well as many other search-related features. Applying these features inside your application can give your users a rich and comforting search experience.
This skill covers how to:
![]() Create a service index
Create a service index
![]() Add data
Add data
![]() Search an index
Search an index
![]() Handle Search results
Handle Search results
Create a service index
There are several types of Azure Search accounts: free, basic, standard, and high-density. The free tier only allows 50MB of data storage and 10,000 documents. As you increase from basic to high-density, you increase how many documents you can index as well as how quickly searches return. Compute resources for Azure Search are sold through Search Units (SUs). The basic level allows 3 search units. The high-density level goes up to 36 SUs. In addition, all of the paid pricing tiers offer load-balancing over three replicas or more replicas. To create an Azure Search service, follow these steps:
-
Log on to the Azure portal.
-
Add a new item. Look up Azure Search Service.
-
In the New Search Service pane, choose a unique URL, Subscription, Resource group, and Location.
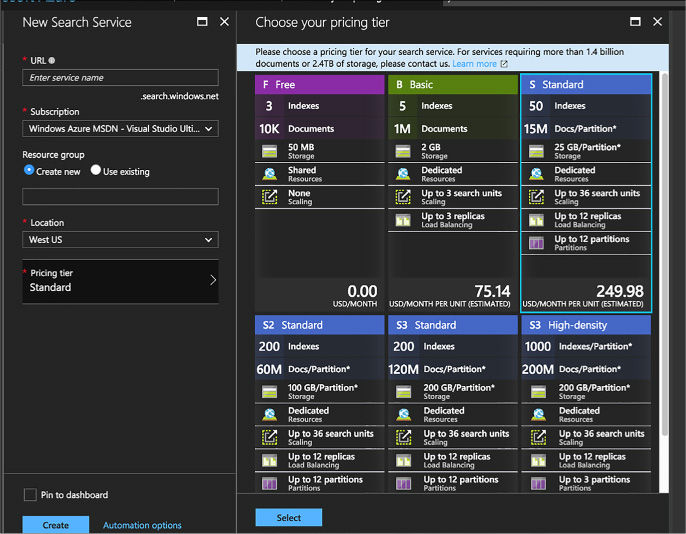
FIGURE 2-32 Azure Search pane
-
Carefully choose an Azure Search pricing tier. Make a note of the search URI (your search name).search.windows.net.
As you use Azure Search, you can scale it if you need more SUs or have more documents to search. On your Azure Search pane, click Scale. The Scale blade is supported in Standard level and above, not basic. From there you can choose how many replicas handle your workload and how many partitions you have. Replicas distribute workloads across multiple nodes. Partitions allow for scaling the document count as well as faster data ingestion by spanning your index over multiple Azure Search Units. Both of these are only offered in the paid service tiers.
Add data
You add data to Azure Search through creating an index. An index contains documents used by Azure Search. For instance, a hotel chain might have a document describing each hotel they own, a home builder might have a document for each house they have on the market. An index is similar to a SQL Server table and documents are similar to rows in those tables.
In our examples, we’ll use C# and the Microsoft .NET Framework to add data to an index and search it. To use the .NET SDK for Azure Search with our examples, you must meet the following requirements:
![]() Visual Studio 2017.
Visual Studio 2017.
![]() Create an Azure Search service with the Azure portal. The free version will work for these code samples.
Create an Azure Search service with the Azure portal. The free version will work for these code samples.
![]() Download the Azure Search SDK Nuget package.
Download the Azure Search SDK Nuget package.
Just like with our other services, we must first create a Search service client, like this:
string searchServiceName = "your search service name;
string accesskey = "your access key"
SearchServiceClient serviceClient = new SearchServiceClient(searchServiceName,
new SearchCredentials(accesskey));
Let’s assume we build homes and we have a POCO for the home class. That class would have properties like RetailPrice, SquareFootage, Description, and FlooringType.
The home class might look like this:
using System;
using Microsoft.Azure.Search;
using Microsoft.Azure.Search.Models;
using Microsoft.Spatial;
using Newtonsoft.Json;
// The SerializePropertyNamesAsCamelCase attribute is defined in the Azure
// Search .NET SDK.
// It ensures that Pascal-case property names in the model class are mapped to
// camel-case field names in the index.
[SerializePropertyNamesAsCamelCase]
public partial class Home
{
[System.ComponentModel.DataAnnotations.Key]
[IsFilterable]
public string HomeID { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public double? RetailPrice { get; set; }
[IsFilterable, IsSortable, IsFacetable]
public int? SquareFootage { get; set; }
[IsSearchable]
public string Description { get; set; }
[IsFilterable, IsSortable]
public GeographyPoint Location { get; set; }
}
The properties all have attributes on them that tell Azure Search how to construct field definitions for them in the index. Notice how these are all public properties. Azure Search will only create definitions for public properties.
First, we create an index with the following code:
var definition = new Index()
{
Name = "homes",
Fields = FieldBuilder.BuildForType<Home>()
};
serviceClient.Indexes.Create(definition);
This will create an index object with field objects that define the correct schema based on our POCO. The FieldBuilder class iterates over the properties of the Home POCO using reflection.
First, create a batch of homes to upload.
var homes = new Home[]
{
new Home()
{
RetailPrice = Convert.ToDouble("459999.00"),
SquareFootage = 3200,
Description = "Single floor, ranch style on 1 acre of property. 4 bedroom,
large living room with open kitchen, dining area.",
Location = GeographyPoint.Create(47.678581, -122.131577)
};
Then create a batch object, declaring that you intend to upload a document:
ISearchIndexClient indexClient = serviceClient.Indexes.GetClient("homes");
var batch = IndexBatch.Upload(homes);
Then upload the document:
indexClient.Documents.Index(batch);
Search an index
In order to search documents, we must first declare a SearchParameters object and DocumentSearchResult object of type Home in our example.
SearchParameters parameters;
DocumentSearchResult<Home> searchResults;
Now we look for any home that has the word ranch in the document. We return only the HomeID field. We save the results.
parameters =
new SearchParameters()
{
Select = new[] { "SquareFootage" }
};
searchResults = indexClient.Documents.Search<Home>("3200", parameters);
Handle Search results
After we have the search results saved in the results variable, we can iterate through them like this:
foreach (SearchResult<Home> result in searchResults.Results)
{
Console.WriteLine(result.Document);
}
We have covered many different areas that data can be stored in Microsoft Azure. These different storage products can be overwhelming and make choosing correctly difficult.
It is important to note that the same data can be stored in any of these solutions just fine, and your application will likely succeed no matter which storage product you use. You can store data in a key-value store, a document store, a graph database, a relational store, or any combination of these products. Functionally, they are very similar with similar features. There is also no specific set of problems that can only be stored in a graph database or only be stored in a relational engine. Understanding the different features, problems, advantages, and query languages will help you choose the correct data store for your application, but you will always feel uncertain that you chose the right one.
Anyone who looks at your problem and definitely knows the perfect storage product is likely either trying to sell you something, only knows that product and therefore has a vested interest in choosing it, has bought in to a specific buzz word or new trend, or is underinformed about the drawbacks of their preferred product. This author’s advice is to inform yourself the best you can and make a decision while accepting the fact that every product has trade-offs.
Thought experiment
In this thought experiment, apply what you’ve learned about this skill. You can find answers to these questions in the next section.
Contoso Limited creates lasers that etch patterns for processors and memory. Their customers include large chip manufacturers around the world
Contoso is in the process of moving several applications to Azure. You are the data architect contracted by Contoso to help them make the good decisions for these applications regarding storage products and features. Contoso has a mobile application their sales people use to create quotes to email to their customers. The product catalog is in several languages and contains detailed product images. You are localizing a mobile application for multiple languages.
-
How will you structure the files in Blob storage so that you can retrieve them easily?
-
What can you do to make access to these images quick for users around the world?
On a regular interval, a Contoso laser sends the shot count of how many times the laser fired to your application. The shot count is cumulative by day. Contoso built more than 500 of these lasers and distributed them around the world. Each laser has its own machine identifier. Each time the shot count is sent, it includes a time stamp. The analysts are mostly concerned with the most recent shot count sent. It’s been decided to store the shot count in Azure Table Storage.
-
What should you use for the partition key? How many partitions should you create?
-
How should you create the row key?
-
How many tables should you build? What’s in each table?
Contoso also wants to write a third application, a web application, that executives can use to show the relationship between customers of your company. Contoso knows that some of their customers purchase chips from other Contoso customers. Your company feels like it’s in a perfect position to examine global business relationships since it has all of the laser records that occur in the global enterprise. Your company uses a variety of relational databases, like Oracle and Microsoft SQL Server. You have heard a lot about JSON Document storage engines, like Azure Cosmos DB, and feel like it would be a perfect fit for this project. Contoso is concerned that this application will have a significant load considering the amount of data that will be processed for each laser. You’ve decided to help them by implementing Redis Cache.
-
What are some advantages that Azure Cosmos DB has over traditional relational data stores?
-
What are disadvantages your enterprise will face in implementing a store like this?
-
How will your organization’s data analyst query data from Azure Cosmos DB?
-
Where do you think Redis Cache can help them?
-
How will Redis Cache lessen the load on their database server?
-
What are some considerations when implementing Redis Cache?
Thought experiment answers
This section contains the solution to the thought experiment.
-
You would consider structuring the blob hierarchy so that one of the portions of the path represented the language or region.
-
You would consider creating a CDN on a publicly available container to cache those files locally around the world.
-
Machine ID seems like a logical candidate for PartitionKey.
-
Shot count time stamp, ordered descending.
-
There might be two tables, one for the machine metadata and one for the shots. You could also make an argument for consolidating both pieces of data into one table for speed in querying.
-
Cosmos DB will be easier to maintain because the schema is declared inside the application. As the application matures, the schema can mature. This will keep the schema fresh and new and changeable. Cosmos DB doesn’t really need a complicated data layer or an ORM, thus saving hours of development as we write and release. CosmosDB keeps the data in the same structure as the object model, keeping the data easy for developers to learn and navigate.
-
There is a learning curve for document stores and graph stores. Traditional relational developers might have a difficult time keeping up with it.
-
Business analysts and data analysts might need to learn a new query language in order to gain access to the data in Cosmos DB. ETL processes might need to be written to pipe document data into a traditional data store for reporting and visualizations. Otherwise the reporting burden of the application will rest on the original developers, which also may be an acceptable solution.
-
They can cache their entire product catalog. They can cache each session so that the session can be saved before it’s committed to the database. They can cache location information, shipping information, etc.
-
All of the above items will greatly alleviate the load of their applications. Basically, you are stopping the relational database read locks from blocking the writing transactions. Also, by caching the reads, you are stopping them from competing for I/O with the writes.
-
Caching is memory intensive, so make sure you are using memory effectively. Caching rarely used things is not effective. Caching needs data management. Knowing when to expire cache, refresh cache, and populate cache are all things that should be thought of ahead of time.
Chapter summary
![]() A blob container has several options for access permissions. When set to Private, all access requires credentials. When set to Public Container, no credentials are required to access the container and its blobs. When set to Public Blob, only blobs can be accessed without credentials if the full URL is known.
A blob container has several options for access permissions. When set to Private, all access requires credentials. When set to Public Container, no credentials are required to access the container and its blobs. When set to Public Blob, only blobs can be accessed without credentials if the full URL is known.
![]() To access secure containers and blobs, you can use the storage account key or shared access signatures.
To access secure containers and blobs, you can use the storage account key or shared access signatures.
![]() Block blobs allow you to upload, store, and download large blobs in blocks up to 4 MB each. The size of the blob can be up to 200 GB.
Block blobs allow you to upload, store, and download large blobs in blocks up to 4 MB each. The size of the blob can be up to 200 GB.
![]() You can use a blob naming convention akin to folder paths to create a logical hierarchy for blobs, which is useful for query operations.
You can use a blob naming convention akin to folder paths to create a logical hierarchy for blobs, which is useful for query operations.
![]() All file copies with Azure Storage blobs are done asynchronously.
All file copies with Azure Storage blobs are done asynchronously.
![]() Table storage is a non-relational database implementation (NoSQL) following the key-value database pattern.
Table storage is a non-relational database implementation (NoSQL) following the key-value database pattern.
![]() Table entries each have a partition key and row key. The partition key is used to logically group rows that are related; the row key is a unique entry for the row.
Table entries each have a partition key and row key. The partition key is used to logically group rows that are related; the row key is a unique entry for the row.
![]() The Table service uses the partition key for distributing collections of rows across physical partitions in Azure to automatically scale out the database as needed.
The Table service uses the partition key for distributing collections of rows across physical partitions in Azure to automatically scale out the database as needed.
![]() A Table storage query returns up to 1,000 records per request, and will time out after five seconds.
A Table storage query returns up to 1,000 records per request, and will time out after five seconds.
![]() Querying Table storage with both the partition and row key results in fast queries. A table scan is required for queries that do not use these keys.
Querying Table storage with both the partition and row key results in fast queries. A table scan is required for queries that do not use these keys.
![]() Applications can add messages to a queue programmatically using the .NET Storage Client Library or equivalent for other languages, or you can directly call the Storage API.
Applications can add messages to a queue programmatically using the .NET Storage Client Library or equivalent for other languages, or you can directly call the Storage API.
![]() Messages are stored in a storage queue for up to seven days based on the expiry setting for the message. Message expiry can be modified while the message is in the queue.
Messages are stored in a storage queue for up to seven days based on the expiry setting for the message. Message expiry can be modified while the message is in the queue.
![]() An application can retrieve messages from a queue in batch to increase throughput and process messages in parallel.
An application can retrieve messages from a queue in batch to increase throughput and process messages in parallel.
![]() Each queue has a target of approximately 2,000 messages per second. You can increase this throughput by partitioning messages across multiple queues.
Each queue has a target of approximately 2,000 messages per second. You can increase this throughput by partitioning messages across multiple queues.
![]() You can use SAS tokens to delegate access to storage account resources without sharing the account key.
You can use SAS tokens to delegate access to storage account resources without sharing the account key.
![]() With SAS tokens, you can generate a link to a container, blob, table, table entity, or queue. You can control the permissions granted to the resource.
With SAS tokens, you can generate a link to a container, blob, table, table entity, or queue. You can control the permissions granted to the resource.
![]() Using Shared Access Policies, you can remotely control the lifetime of a SAS token grant to one or more resources. You can extend the lifetime of the policy or cause it to expire.
Using Shared Access Policies, you can remotely control the lifetime of a SAS token grant to one or more resources. You can extend the lifetime of the policy or cause it to expire.
![]() Storage Analytics metrics provide the equivalent of Windows Performance Monitor counters for storage services.
Storage Analytics metrics provide the equivalent of Windows Performance Monitor counters for storage services.
![]() You can determine which services to collect metrics for (Blob, Table, or Queue), whether to collect metrics for the service or API level, and whether to collect metrics by the minute or hour.
You can determine which services to collect metrics for (Blob, Table, or Queue), whether to collect metrics for the service or API level, and whether to collect metrics by the minute or hour.
![]() Capacity metrics are only applicable to the Blob service.
Capacity metrics are only applicable to the Blob service.
![]() Storage Analytics Logging provides details about the success or failure of requests to storage services.
Storage Analytics Logging provides details about the success or failure of requests to storage services.
![]() Storage logs are stored in blob services for the account, in the $logs container for the service.
Storage logs are stored in blob services for the account, in the $logs container for the service.
![]() You can specify up to 365 days for retention of storage metrics or logs, or you can set retention to 0 to retain metrics indefinitely. Metrics and logs are removed automatically from storage when the retention period expires.
You can specify up to 365 days for retention of storage metrics or logs, or you can set retention to 0 to retain metrics indefinitely. Metrics and logs are removed automatically from storage when the retention period expires.
![]() Storage metrics can be viewed in the management portal. Storage logs can be downloaded and viewed in a reporting tool such as Excel.
Storage metrics can be viewed in the management portal. Storage logs can be downloaded and viewed in a reporting tool such as Excel.
![]() The different editions of Azure SQL Database affect performance, SLAs, backup/restore policies, pricing, geo-replication options, and database size.
The different editions of Azure SQL Database affect performance, SLAs, backup/restore policies, pricing, geo-replication options, and database size.
![]() The edition of Azure SQL Database determines the retention period for point in time restores. This should factor into your backup and restore policies.
The edition of Azure SQL Database determines the retention period for point in time restores. This should factor into your backup and restore policies.
![]() It is possible to create an online secondary when you configure Azure SQL Database geo-replication. It requires the Premium Edition.
It is possible to create an online secondary when you configure Azure SQL Database geo-replication. It requires the Premium Edition.
![]() If you are migrating an existing database to the cloud, you can use the BACPACs to move schema and data into your Azure SQL database.
If you are migrating an existing database to the cloud, you can use the BACPACs to move schema and data into your Azure SQL database.
![]() Elastic pools will help you share DTUs with multiple databases on the same server.
Elastic pools will help you share DTUs with multiple databases on the same server.
![]() Sharding and scale-out can be easier to manage by using the Elastic Tools from Microsoft.
Sharding and scale-out can be easier to manage by using the Elastic Tools from Microsoft.
![]() Azure SQL Database introduces new graph features and graph query syntax.
Azure SQL Database introduces new graph features and graph query syntax.
![]() The different types of APIs available in Azure Cosmos DB, including table, graph, and document.
The different types of APIs available in Azure Cosmos DB, including table, graph, and document.
![]() Why developers find document storage easy to use in web, mobile, and IoT applications because saving and retrieving data does not require a complex data layer or an ORM.
Why developers find document storage easy to use in web, mobile, and IoT applications because saving and retrieving data does not require a complex data layer or an ORM.
![]() The different ways to query Azure Cosmos DB, including LINQ lambda, LINQ query, and SQL.
The different ways to query Azure Cosmos DB, including LINQ lambda, LINQ query, and SQL.
![]() Why graph databases are a great solution for certain problems, particularly showing relationships between entities.
Why graph databases are a great solution for certain problems, particularly showing relationships between entities.
![]() Cosmos DB scaling is in large part automatic and requires little to no management. The most important thing is to correctly choose which documents will go in which collections and which partition key to use with them.
Cosmos DB scaling is in large part automatic and requires little to no management. The most important thing is to correctly choose which documents will go in which collections and which partition key to use with them.
![]() Cosmos DB supports multiple regions for disaster recovery and to keep the data close to the users for improved network latency.
Cosmos DB supports multiple regions for disaster recovery and to keep the data close to the users for improved network latency.
![]() Cosmos DB has several different security mechanisms, including encryption at rest, network firewalls, and users and permissions.
Cosmos DB has several different security mechanisms, including encryption at rest, network firewalls, and users and permissions.
![]() What Redis Cache is and how it can help speed up applications.
What Redis Cache is and how it can help speed up applications.
![]() How to choose between the different tiers of Azure Redis Cache
How to choose between the different tiers of Azure Redis Cache
![]() The importance of data persistence in maintaining state in case of power or hardware failure.
The importance of data persistence in maintaining state in case of power or hardware failure.
![]() How to scale Azure Redis Cache for better performance or larger data sets.
How to scale Azure Redis Cache for better performance or larger data sets.
![]() Create an Azure Search Service using the Azure portal.
Create an Azure Search Service using the Azure portal.
![]() Create an Azure Search index and populate it with documents using C# and the .NET SDK.
Create an Azure Search index and populate it with documents using C# and the .NET SDK.
![]() Search the index for a keyword and handle the results.
Search the index for a keyword and handle the results.
