
Users Online
· Guests Online: 12
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
Forum Threads
Newest Threads
No Threads created
Hottest Threads
No Threads created
Latest Articles
FAQ: Big Data Ingestion and Streaming Patterns
| FAQ (Frequently Asked Questions) >Big Data Ingestion and Streaming Patterns |
3_1. What do you understand by Data Ingestion?
In typical ingestion scenarios, you have multiple data sources to process. As the number of data sources increases, the processing starts to become complicated. Also, in the case of big data, many times the source data structure itself is not known; hence, following the traditional data integration approaches creates difficulty in integrating data.
Common challenges encountered while ingesting several data sources include the following:
Prioritizing each data source load
Tagging and indexing ingested data
Validating and cleansing the ingested data
Transforming and compressing before ingestion
Top
In typical ingestion scenarios, you have multiple data sources to process. As the number of data sources increases, the processing starts to become complicated. Also, in the case of big data, many times the source data structure itself is not known; hence, following the traditional data integration approaches creates difficulty in integrating data.
Common challenges encountered while ingesting several data sources include the following:
Prioritizing each data source load
Tagging and indexing ingested data
Validating and cleansing the ingested data
Transforming and compressing before ingestion
Top
3_10. Can traditional ETL tools be used to ingest data into HDFS?
ETL Tools for Big Data
Traditional ETL tools like the open source Talend, Pentahho DI, or well-known products like Informatica can also be leveraged for data ingestion. Some of the traditional ETL tools can read and write multiple files in parallel from and to HDFS.
ETL tools help to get data from one data environment and put it into another data environment. ETL is generally used with batch processing in data warehouse environments. Data warehouses provide business users with a way to consolidate information across disparate sources to analyze and report on insights relevant to their specific business focus. ETL tools are used to transform the data into the format required by the data warehouse. The transformation is
actually done in an intermediate location before the data is loaded into the data warehouse.
In the big data world, ETL tools like Informatica have been used to enable a fast and flexible ingestion solution
(greater than 150 GBs/day) that can support ad hoc capability for data and insight discovery. Informatica can be used
in place of Sqoop and Flume solutions. Informatica PowerCenter can be utilized as a primary raw data ingestion engine.
Figure 3-7 depicts a scenario in which a traditional ETL tool has been used to ingest data into HDFS.
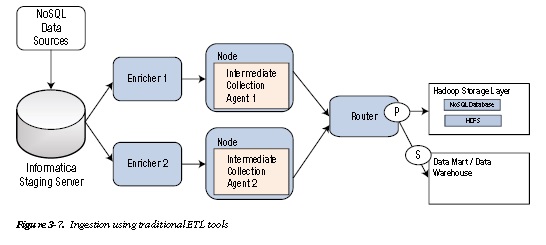
Top
ETL Tools for Big Data
Traditional ETL tools like the open source Talend, Pentahho DI, or well-known products like Informatica can also be leveraged for data ingestion. Some of the traditional ETL tools can read and write multiple files in parallel from and to HDFS.
ETL tools help to get data from one data environment and put it into another data environment. ETL is generally used with batch processing in data warehouse environments. Data warehouses provide business users with a way to consolidate information across disparate sources to analyze and report on insights relevant to their specific business focus. ETL tools are used to transform the data into the format required by the data warehouse. The transformation is
actually done in an intermediate location before the data is loaded into the data warehouse.
In the big data world, ETL tools like Informatica have been used to enable a fast and flexible ingestion solution
(greater than 150 GBs/day) that can support ad hoc capability for data and insight discovery. Informatica can be used
in place of Sqoop and Flume solutions. Informatica PowerCenter can be utilized as a primary raw data ingestion engine.
Figure 3-7 depicts a scenario in which a traditional ETL tool has been used to ingest data into HDFS.
Top
3_11. Are there message-transformation best practices in the ingestion layers that facilitate faster ingestion?
For the transformation of messages and location of the transformation process, these guidelines can be followed:
Perform the transformation as a part of the extraction process.
This allows selecting only the record of interest for loading and, ideally, that should be the data that has changed since the last extraction. Simple transformation, such as decoding an attribute and uppercase/lowercase conversions,
can be performed in the source system.
Perform the transformation as a separate layer.
Transformation can be performed in the staging area prior to loading in the HDFS system. When there are multiple data sources, the data needs to be consolidated and mapped to a different data structure. Such an intermediate data store is called staging. We can use Hadoop ETL tools like Hive and Pig in this area to do the transformation.
Perform the transformation as a part of the loading process. Some simple transformation can be done during the loading process itself.
Perform the transformation in memory.
Transformation of data in memory is considered to be a better option for large and complex transformations with no latency between the extraction and loading processes. But this involves large amounts of memory. This is useful for near real-time system analytics (for example, SAP HANA), where transformation and loading is done with very low latency.
Top
For the transformation of messages and location of the transformation process, these guidelines can be followed:
Perform the transformation as a part of the extraction process.
This allows selecting only the record of interest for loading and, ideally, that should be the data that has changed since the last extraction. Simple transformation, such as decoding an attribute and uppercase/lowercase conversions,
can be performed in the source system.
Perform the transformation as a separate layer.
Transformation can be performed in the staging area prior to loading in the HDFS system. When there are multiple data sources, the data needs to be consolidated and mapped to a different data structure. Such an intermediate data store is called staging. We can use Hadoop ETL tools like Hive and Pig in this area to do the transformation.
Perform the transformation as a part of the loading process. Some simple transformation can be done during the loading process itself.
Perform the transformation in memory.
Transformation of data in memory is considered to be a better option for large and complex transformations with no latency between the extraction and loading processes. But this involves large amounts of memory. This is useful for near real-time system analytics (for example, SAP HANA), where transformation and loading is done with very low latency.
Top
3_12. Are there any hardware appliances available in the market to ingest big data workloads?
Many vendors like IBM, Oracle, EMC, and others have come out with hardware appliances that promise end-to-end systems that optimize the big data ingestion, processing, and storage functions. The next section gives you a brief idea about the capabilities of such appliances.
Oracle has a big data appliance that handles data to the tune of 600 TBs. It utilizes Apache CDH for big data management. It also has an inherent 10 GbE high speed network between the nodes for rapid real time ingestion and replication.
EMC comes with a similar appliance called Greenplum with similar features to facilitate high speed low cost data processing using Hadoop.
Top
Many vendors like IBM, Oracle, EMC, and others have come out with hardware appliances that promise end-to-end systems that optimize the big data ingestion, processing, and storage functions. The next section gives you a brief idea about the capabilities of such appliances.
Oracle has a big data appliance that handles data to the tune of 600 TBs. It utilizes Apache CDH for big data management. It also has an inherent 10 GbE high speed network between the nodes for rapid real time ingestion and replication.
EMC comes with a similar appliance called Greenplum with similar features to facilitate high speed low cost data processing using Hadoop.
Top
3_13. How do I ingest data onto third-party public cloud options like Google BigQuery?
BigQuery is Googles cloud-based big data analytics service. You can upload your big data set to BigQuery for analysis.
However, depending on your datas structure, you might need to prepare the data before loading it into BigQuery. For example, you might need to export your data into a different format or transform the data. BigQuery supports two data formats: CSV and JSON.
BigQuery can load uncompressed files significantly faster than compressed files due to parallel load operations,
but because uncompressed files are larger in size, using them can lead to bandwidth limitations and higher Google
Cloud Storage costs. For example, uncompressed files that live on third-party services can consume considerable
bandwidth and time if uploaded to Google Cloud Storage for loading.
With BigQuery, processing is faster if you denormalize the data structure to enable super-fast querying.
Large datasets are often represented using XML. BigQuery doesnt support directly loading XML files, but XML files can be easily converted to an equivalent JSON format or flat CSV structure and then uploaded to continue processing.
Top
BigQuery is Googles cloud-based big data analytics service. You can upload your big data set to BigQuery for analysis.
However, depending on your datas structure, you might need to prepare the data before loading it into BigQuery. For example, you might need to export your data into a different format or transform the data. BigQuery supports two data formats: CSV and JSON.
BigQuery can load uncompressed files significantly faster than compressed files due to parallel load operations,
but because uncompressed files are larger in size, using them can lead to bandwidth limitations and higher Google
Cloud Storage costs. For example, uncompressed files that live on third-party services can consume considerable
bandwidth and time if uploaded to Google Cloud Storage for loading.
With BigQuery, processing is faster if you denormalize the data structure to enable super-fast querying.
Large datasets are often represented using XML. BigQuery doesnt support directly loading XML files, but XML files can be easily converted to an equivalent JSON format or flat CSV structure and then uploaded to continue processing.
Top
3_2. What are the typical data ingestion patterns?
Unstructured data, if stored in a relational database management system (RDBMS) will create performance and scalability concerns. Hence, in the big data world, data is loaded using multiple solutions and multiple target destinations to solve the specific types of problems encountered during ingestion.
Ingestion patterns describe solutions to commonly encountered problems in data source to ingestion layer communications. These solutions can be chosen based on the performance, scalability, and availability requirements.
Well look at these patterns (which are shown in Figure 3-1) in the subsequent sections. We will cover the following common data-ingestion and streaming patterns in this chapter:
Multisource Extractor Pattern: This pattern is an approach to ingest multiple data source types in an efficient manner.
Protocol Converter Pattern:This pattern employs a protocol mediator to provide abstraction for the incoming data from the different protocol layers.
Multidestination Pattern: This pattern is used in a scenario where the ingestion layer has to transport the data to multiple storage components like Hadoop Distributed File System
(HDFS), data marts, or real-time analytics engines.
Just-in-Time Transformation Pattern: Large quantities of unstructured data can be uploaded in a batch mode using traditional ETL (extract, transfer and load) tools and methods. However, the data is transformed only when required to save compute time.
Real-Time Streaming patterns: Certain business problems require an instant analysis of data coming into the enterprise. In these circumstances, real-time ingestion and analysis of the in-streaming data is required.
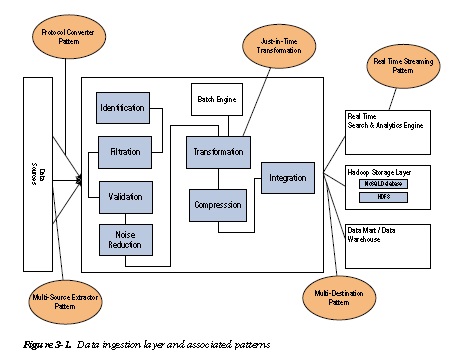
Top
Unstructured data, if stored in a relational database management system (RDBMS) will create performance and scalability concerns. Hence, in the big data world, data is loaded using multiple solutions and multiple target destinations to solve the specific types of problems encountered during ingestion.
Ingestion patterns describe solutions to commonly encountered problems in data source to ingestion layer communications. These solutions can be chosen based on the performance, scalability, and availability requirements.
Well look at these patterns (which are shown in Figure 3-1) in the subsequent sections. We will cover the following common data-ingestion and streaming patterns in this chapter:
Multisource Extractor Pattern: This pattern is an approach to ingest multiple data source types in an efficient manner.
Protocol Converter Pattern:This pattern employs a protocol mediator to provide abstraction for the incoming data from the different protocol layers.
Multidestination Pattern: This pattern is used in a scenario where the ingestion layer has to transport the data to multiple storage components like Hadoop Distributed File System
(HDFS), data marts, or real-time analytics engines.
Just-in-Time Transformation Pattern: Large quantities of unstructured data can be uploaded in a batch mode using traditional ETL (extract, transfer and load) tools and methods. However, the data is transformed only when required to save compute time.
Real-Time Streaming patterns: Certain business problems require an instant analysis of data coming into the enterprise. In these circumstances, real-time ingestion and analysis of the in-streaming data is required.
Top
3_3. How will you ingest data from multiple sources and different formats in an efficient manner?
Multisource Extractor Pattern
The multisource extractor pattern (shown in Figure 3-2) is applicable in scenarios where enterprises that have large collections of unstructured data need to investigate these disparate datasets and nonrelational databases (for example, NoSQL, Cassandra, and so forth); typical industry examples are claims and underwriting, financial trading, telecommunications, e-commerce, fraud detection, social media, gaming, and wagering. Feeds from energy exploration and video-surveillance equipment where application workloads are CPU and I/O-intensive are also ideal candidates for the multisource extractor pattern.
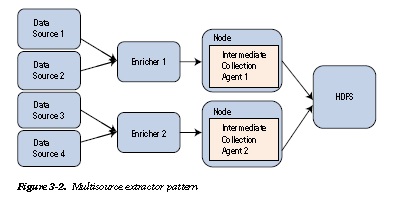
Multisource extractor taxonomy ensures that the ingestion tool/framework is highly available and distributed.
It also ensures that huge volumes of data get segregated into multiple batches across different nodes. For a very small implementation involving a handful of clients and/or only a small volume of data, even a single-node implementation will work. But, for a continuous stream of data influx from multiple clients and a huge volume, it makes sense to have clustered implementation with batches partitioned into small volumes.
Generally, in large ingestion systems, big data operators employ enrichers to do initial data aggregation and cleansing. (See Figure 3-2.) An enricher reliably transfers files, validates them, reduces noise, compresses and transforms from a native format to an easily interpreted representation. Initial data cleansing (for example, removing duplication) is also commonly performed in the enricher tier.
Once the files are processed by enrichers, they are transferred to a cluster of intermediate collectors for final processing and loading to destination systems.
Because the ingestion layer has to be fault-tolerant, it always makes sense to have multiple nodes. The number of disks and disk size per node have to be based on each clients volume. Multiple nodes will be able to write to more drives in parallel and provide greater throughput.
However, the multisource extractor pattern has a number of significant disadvantages that make it unusable for real-time ingestion. The major shortcomings are as follows:
Not Real Time: Data-ingestion latency might vary between 30 minutes and a few hours.
Redundant Data: Multiple copies of data need to be kept in different tiers of enrichers and collection agents. This makes already large data volumes even larger.
High Costs: High availability is usually a requirement for this pattern. As the systems grow in capacity, costs of maintaining high availability increases.
Complex Configuration: This batch-oriented pattern is difficult to configure and maintain.

Top
Multisource Extractor Pattern
The multisource extractor pattern (shown in Figure 3-2) is applicable in scenarios where enterprises that have large collections of unstructured data need to investigate these disparate datasets and nonrelational databases (for example, NoSQL, Cassandra, and so forth); typical industry examples are claims and underwriting, financial trading, telecommunications, e-commerce, fraud detection, social media, gaming, and wagering. Feeds from energy exploration and video-surveillance equipment where application workloads are CPU and I/O-intensive are also ideal candidates for the multisource extractor pattern.
Multisource extractor taxonomy ensures that the ingestion tool/framework is highly available and distributed.
It also ensures that huge volumes of data get segregated into multiple batches across different nodes. For a very small implementation involving a handful of clients and/or only a small volume of data, even a single-node implementation will work. But, for a continuous stream of data influx from multiple clients and a huge volume, it makes sense to have clustered implementation with batches partitioned into small volumes.
Generally, in large ingestion systems, big data operators employ enrichers to do initial data aggregation and cleansing. (See Figure 3-2.) An enricher reliably transfers files, validates them, reduces noise, compresses and transforms from a native format to an easily interpreted representation. Initial data cleansing (for example, removing duplication) is also commonly performed in the enricher tier.
Once the files are processed by enrichers, they are transferred to a cluster of intermediate collectors for final processing and loading to destination systems.
Because the ingestion layer has to be fault-tolerant, it always makes sense to have multiple nodes. The number of disks and disk size per node have to be based on each clients volume. Multiple nodes will be able to write to more drives in parallel and provide greater throughput.
However, the multisource extractor pattern has a number of significant disadvantages that make it unusable for real-time ingestion. The major shortcomings are as follows:
Not Real Time: Data-ingestion latency might vary between 30 minutes and a few hours.
Redundant Data: Multiple copies of data need to be kept in different tiers of enrichers and collection agents. This makes already large data volumes even larger.
High Costs: High availability is usually a requirement for this pattern. As the systems grow in capacity, costs of maintaining high availability increases.
Complex Configuration: This batch-oriented pattern is difficult to configure and maintain.
Top
3_4. How will you ingest data from multiple sources and different formats/protocols in an efficient manner?
Protocol Converter Pattern
The protocol converter pattern (shown in Figure 3-3) is applicable in scenarios where enterprises have a wide variety
of unstructured data from data sources that have different data protocols and formats. In this pattern, the ingestion
layer does the following:
1. Identifies multiple channels of incoming event.
2. Identifies polydata structures.
3. Provides services to mediate multiple protocols into suitable sinks.
4. Provides services to interface binding of external system containing several sets of
messaging patterns into a common platform.
5. Provides services to handle various request types.
6. Provides services to abstract incoming data from various protocol layers.
7. Provides a unifying platform for the next layer to process the incoming data.
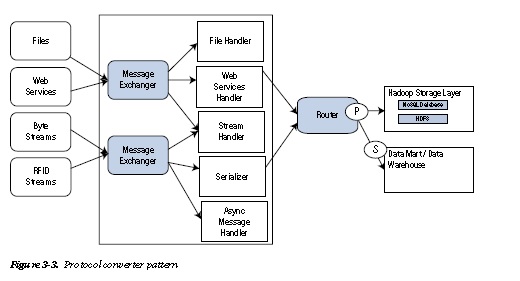
Protocol conversion is required when the source of data follows various different protocols. The variation in the protocol is either in the headers or the actual message. It could be either the number of bits in the headers, the length of the various fields and the corresponding logic required to decipher the data content, the message could be fixed length or variable length with separators.
This pattern is required to standardize the structure of the various different messages so that it is possible to analyze the information together using an analytics tool . The converter fits the different messages into a standard canonical message format that is usually mapped to a NoSQL data structure.
This concept is important when a system needs to be designed to address multiple protocols having multiple structures for incoming data.
In this pattern, the ingestion layer provides the following services:
Message Exchanger: The messages could be synchronous or asynchronous depending on the
protocol used for transport. A typical example is a web application information exchange over HTPP and the JMS-like message oriented communication that is usually asynchronous.
Stream Handler: This component recognizes and transforms data being sent as byte streams or object streamsfor example, bytes of image data, PDFs, and so forth.
File handler: This component recognizes and loads data being sent as filesfor example, FTP.
Web Services Handler: This component defines the manner of data population and parsing and translation of the incoming data into the agreed-upon formatfor example, REST WS,
SOAP-based WS, and so forth.
Async Handler: This component defines the system used to handle asynchronous eventsfor example, MQ, Async HTTP, and so forth.
Serializer: The serializer handles incoming data as Objects or complex types over RMI (remote method invocation)for example, EJB components. The object state is stored in
databases or flat files.
Top
Protocol Converter Pattern
The protocol converter pattern (shown in Figure 3-3) is applicable in scenarios where enterprises have a wide variety
of unstructured data from data sources that have different data protocols and formats. In this pattern, the ingestion
layer does the following:
1. Identifies multiple channels of incoming event.
2. Identifies polydata structures.
3. Provides services to mediate multiple protocols into suitable sinks.
4. Provides services to interface binding of external system containing several sets of
messaging patterns into a common platform.
5. Provides services to handle various request types.
6. Provides services to abstract incoming data from various protocol layers.
7. Provides a unifying platform for the next layer to process the incoming data.
Protocol conversion is required when the source of data follows various different protocols. The variation in the protocol is either in the headers or the actual message. It could be either the number of bits in the headers, the length of the various fields and the corresponding logic required to decipher the data content, the message could be fixed length or variable length with separators.
This pattern is required to standardize the structure of the various different messages so that it is possible to analyze the information together using an analytics tool . The converter fits the different messages into a standard canonical message format that is usually mapped to a NoSQL data structure.
This concept is important when a system needs to be designed to address multiple protocols having multiple structures for incoming data.
In this pattern, the ingestion layer provides the following services:
Message Exchanger: The messages could be synchronous or asynchronous depending on the
protocol used for transport. A typical example is a web application information exchange over HTPP and the JMS-like message oriented communication that is usually asynchronous.
Stream Handler: This component recognizes and transforms data being sent as byte streams or object streamsfor example, bytes of image data, PDFs, and so forth.
File handler: This component recognizes and loads data being sent as filesfor example, FTP.
Web Services Handler: This component defines the manner of data population and parsing and translation of the incoming data into the agreed-upon formatfor example, REST WS,
SOAP-based WS, and so forth.
Async Handler: This component defines the system used to handle asynchronous eventsfor example, MQ, Async HTTP, and so forth.
Serializer: The serializer handles incoming data as Objects or complex types over RMI (remote method invocation)for example, EJB components. The object state is stored in
databases or flat files.
Top
3_5. Should all the raw data be ingested only in HDFS? In what scenario should it be ingested in multiple destinations?
Multidestination Pattern
Many organizations have traditional RDBMS systems as well as analytics platforms like SAS or Informatica. However, the ever-growing amount of data from an increasing number of data streams causes storage overflow problems. Also, the cost of licenses required to process this huge data slowly starts to become prohibitive. Increasing volume also causes data errors (a.k.a., data regret), and the time required to process the data increases exponentially. Because the RDBMS and analytics platforms are physically separate, a huge amount of data needs to be transferred over the network on a daily basis.
To overcome these challenges, an organization can start ingesting data into multiple data stores, both RDBMS as well as NoSQL data stores. The data transformation can be performed in the HDFS storage. Hive or Pig can be used to analyze the data at a lower cost. This also reduces the load on the existing SAS/Informatica analytics engines.
The Hadoop layer uses map reduce jobs to prepare the data for effective querying by Hive and Pig. This also ensures that large amounts of data need not be transferred over the network, thus avoiding huge costs.
The multidestination pattern (Figure 3-4) is very similar to the multisource ingestion pattern until it is ready to integrate with multiple destinations. A router publishes the enriched data and then broadcasts it to the subscriber destinations. The destinations have to register with the publishing agent on the router. Enrichers can be used as required by the publishers as well as the subscribers. The router can be deployed in a cluster, depending on the volume of data and number of subscribing destinations.

This pattern solves some of the problems of ingesting and storing huge volumes of data:
Splits the cost of storage by dividing stored data among traditional storage systems and HDFS.
Provides the ability to partition the data for flexible access and processing in a decentralized
fashion.
Due to replication on the HDFS nodes, there is no data regret.
Because each node is self-sufficient, its easy to add more nodes and storage without delays.
Decentralized computation at the data nodes without extraction of data to other tools.
Allows use of simple query languages like Hive and Pig alongside the giants of traditional
analytics.
Top
Multidestination Pattern
Many organizations have traditional RDBMS systems as well as analytics platforms like SAS or Informatica. However, the ever-growing amount of data from an increasing number of data streams causes storage overflow problems. Also, the cost of licenses required to process this huge data slowly starts to become prohibitive. Increasing volume also causes data errors (a.k.a., data regret), and the time required to process the data increases exponentially. Because the RDBMS and analytics platforms are physically separate, a huge amount of data needs to be transferred over the network on a daily basis.
To overcome these challenges, an organization can start ingesting data into multiple data stores, both RDBMS as well as NoSQL data stores. The data transformation can be performed in the HDFS storage. Hive or Pig can be used to analyze the data at a lower cost. This also reduces the load on the existing SAS/Informatica analytics engines.
The Hadoop layer uses map reduce jobs to prepare the data for effective querying by Hive and Pig. This also ensures that large amounts of data need not be transferred over the network, thus avoiding huge costs.
The multidestination pattern (Figure 3-4) is very similar to the multisource ingestion pattern until it is ready to integrate with multiple destinations. A router publishes the enriched data and then broadcasts it to the subscriber destinations. The destinations have to register with the publishing agent on the router. Enrichers can be used as required by the publishers as well as the subscribers. The router can be deployed in a cluster, depending on the volume of data and number of subscribing destinations.
This pattern solves some of the problems of ingesting and storing huge volumes of data:
Splits the cost of storage by dividing stored data among traditional storage systems and HDFS.
Provides the ability to partition the data for flexible access and processing in a decentralized
fashion.
Due to replication on the HDFS nodes, there is no data regret.
Because each node is self-sufficient, its easy to add more nodes and storage without delays.
Decentralized computation at the data nodes without extraction of data to other tools.
Allows use of simple query languages like Hive and Pig alongside the giants of traditional
analytics.
Top
3_6. Should preprocessing of datafor example, cleansing/validationalways be done before ingesting data in HDFS?
Just-in-Time Transformation Pattern
For a huge volume of data and a huge number of analytical computations, it makes sense to ingest all the raw data into HDFS and then run dependent preprocessing batch jobs based on the business case to be implemented to
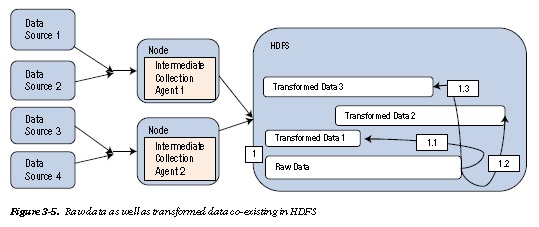
cleanse, validate, co-relate, and transform the data. This transformed data, then, can again be stored in HDFS itself or transferred to data marts, warehouses, or real-time analytics engines. In short, raw data and transformed data can co-exist in HDFS and running all preprocessing transformations before ingestion might not be always ideal.
But basic validations can be performed as part of preprocessing on data being ingested.
This section introduces you to the just-in-time transformation pattern, where data is loaded and then
transformed when required by the business. Notice the absence of the enricher layer in Figure 3-5. Multiple batch jobs run in parallel to transform data as required in the HDFS storage.
Top
Just-in-Time Transformation Pattern
For a huge volume of data and a huge number of analytical computations, it makes sense to ingest all the raw data into HDFS and then run dependent preprocessing batch jobs based on the business case to be implemented to
cleanse, validate, co-relate, and transform the data. This transformed data, then, can again be stored in HDFS itself or transferred to data marts, warehouses, or real-time analytics engines. In short, raw data and transformed data can co-exist in HDFS and running all preprocessing transformations before ingestion might not be always ideal.
But basic validations can be performed as part of preprocessing on data being ingested.
This section introduces you to the just-in-time transformation pattern, where data is loaded and then
transformed when required by the business. Notice the absence of the enricher layer in Figure 3-5. Multiple batch jobs run in parallel to transform data as required in the HDFS storage.
Top
3_7. How do we develop big data applications for processing continuous, real-time and unstructured inflow of data into the enterprise?
Real-Time Streaming Pattern
The key characteristics of a real-time streaming ingestion system (Figure 3-6) are as follows:
It should be self-sufficient and use local memory in each processing node to minimize latency.
It should have a share-nothing architecturethat is, all nodes should have atomic responsibilities and should not be dependent on each other.
It should provide a simple API for parsing the real time information quickly.
The atomicity of each of the components should be such that the system can scale across clusters using commodity hardware.
There should be no centralized master node. All nodes should be deployable with a uniform script.

Event processing nodes (EPs) consume the different inputs from various data sources. EPs create events that are captured by the event listeners of the event processing engines. Event listeners are the logical hosts to EPs. Event processing engines have a very large in-memory capacity (big memory). EPs get triggered by events as they are based on an event driven architecture. As soon as a event occurs the EP is triggered to execute a specific operation and then forward it to the alerter. The alerter publishes the results of the in-memory big data analytics to the enterprise BPM (business process management) engines. The BPM processes can redirect the results of the analysis to various channels like mobile, CIO dashboards, BAM systems and so forth.
Top
Real-Time Streaming Pattern
The key characteristics of a real-time streaming ingestion system (Figure 3-6) are as follows:
It should be self-sufficient and use local memory in each processing node to minimize latency.
It should have a share-nothing architecturethat is, all nodes should have atomic responsibilities and should not be dependent on each other.
It should provide a simple API for parsing the real time information quickly.
The atomicity of each of the components should be such that the system can scale across clusters using commodity hardware.
There should be no centralized master node. All nodes should be deployable with a uniform script.
Event processing nodes (EPs) consume the different inputs from various data sources. EPs create events that are captured by the event listeners of the event processing engines. Event listeners are the logical hosts to EPs. Event processing engines have a very large in-memory capacity (big memory). EPs get triggered by events as they are based on an event driven architecture. As soon as a event occurs the EP is triggered to execute a specific operation and then forward it to the alerter. The alerter publishes the results of the in-memory big data analytics to the enterprise BPM (business process management) engines. The BPM processes can redirect the results of the analysis to various channels like mobile, CIO dashboards, BAM systems and so forth.
Top
3_8. What are the essential tools/frameworks required in your big data ingestion layer to handle files in batch-processing mode?
There are many product options to facilitate batch-processing-based ingestion. Here are some of the major frameworks available in the market:
Apache Sqoop is a is used to transfer large volumes of data between Hadoop big data nodes and relational databases.. It offers two-way replication with both snapshots and incremental updates.
Chukwa is a Hadoop subproject that is designed for efficient log processing. It provides
a scalable distributed system for monitoring and analysis of log-based data. It supports appending to existing files and can be configured to monitor and process logs that are generated incrementally across many machines.
Apache Kafka is a broadcast messaging system where the information is being listened
to by multiple subscribers and picked up based on relevance to each subscriber. The
publisher can be configured to retain the messages until the confirmation is received from
all the subscribers. If any subscriber does not receive the information, the publisher will
send it again. Its features include the use of compression to optimize IO performance and
mirroring to improve availability, improve scalability, to optimize performance in multiple-cluster scenarios. It can be used as the framework between the router and Hadoop in the multidestination pattern implementation.
Top
There are many product options to facilitate batch-processing-based ingestion. Here are some of the major frameworks available in the market:
Apache Sqoop is a is used to transfer large volumes of data between Hadoop big data nodes and relational databases.. It offers two-way replication with both snapshots and incremental updates.
Chukwa is a Hadoop subproject that is designed for efficient log processing. It provides
a scalable distributed system for monitoring and analysis of log-based data. It supports appending to existing files and can be configured to monitor and process logs that are generated incrementally across many machines.
Apache Kafka is a broadcast messaging system where the information is being listened
to by multiple subscribers and picked up based on relevance to each subscriber. The
publisher can be configured to retain the messages until the confirmation is received from
all the subscribers. If any subscriber does not receive the information, the publisher will
send it again. Its features include the use of compression to optimize IO performance and
mirroring to improve availability, improve scalability, to optimize performance in multiple-cluster scenarios. It can be used as the framework between the router and Hadoop in the multidestination pattern implementation.
Top
3_9. What are the essential tools/frameworks required in your big data ingestion layer to handle real-time streaming data?
There are many product options to facilitate real-time streaming ingestion. Here are some of the major frameworks
available in the market:
Flume is a distributed system for collecting log data from many sources, aggregating it, and
writing it to HDFS. It is based on streaming data flows. Flume provides extensibility for
online analytic applications. However, Flume requires a fair amount of configuration that can
become very complex for very large systems.
Storm supports event-stream processing and can respond to individual events within a
reasonable time frame. Storm is a general-purpose, event-processing system that uses a
cluster of services for scalability and reliability. In Storm terminology, you create a topology
that runs continuously over a stream of incoming data. The data sources for the topology
are called spouts, and each processing node is called a bolt. Bolts can perform sophisticated
computations on the data, including output to data stores and other services. It is common for
organizations to run a combination of Hadoop and Storm services to gain the best features of
both platforms.
InfoSphere Streams is able to perform complex analytics of heterogeneous data types.
Infosphere Streams can support all data types. It can perform real-time and look-ahead
analysis of regularly generated data, using digital filtering, pattern/correlation analysis, and
decomposition as well as geospatial analysis. Apache S4 is a Yahoo invented platform for
handling continuous real time ingestion of data. It provides simple APIs for manipulating the
unstructured streams of data, searches and distributes the processing across multiple nodes
automatically without complicated programming. Client programs that send and receive
events can be written in any programming language. S4 is designed as a highly distributed
system. Throughput can be increased linearly by adding nodes into a cluster. The S4 design is
best suited for large-scale applications for data mining and machine learning in a production
environment.
Top
There are many product options to facilitate real-time streaming ingestion. Here are some of the major frameworks
available in the market:
Flume is a distributed system for collecting log data from many sources, aggregating it, and
writing it to HDFS. It is based on streaming data flows. Flume provides extensibility for
online analytic applications. However, Flume requires a fair amount of configuration that can
become very complex for very large systems.
Storm supports event-stream processing and can respond to individual events within a
reasonable time frame. Storm is a general-purpose, event-processing system that uses a
cluster of services for scalability and reliability. In Storm terminology, you create a topology
that runs continuously over a stream of incoming data. The data sources for the topology
are called spouts, and each processing node is called a bolt. Bolts can perform sophisticated
computations on the data, including output to data stores and other services. It is common for
organizations to run a combination of Hadoop and Storm services to gain the best features of
both platforms.
InfoSphere Streams is able to perform complex analytics of heterogeneous data types.
Infosphere Streams can support all data types. It can perform real-time and look-ahead
analysis of regularly generated data, using digital filtering, pattern/correlation analysis, and
decomposition as well as geospatial analysis. Apache S4 is a Yahoo invented platform for
handling continuous real time ingestion of data. It provides simple APIs for manipulating the
unstructured streams of data, searches and distributes the processing across multiple nodes
automatically without complicated programming. Client programs that send and receive
events can be written in any programming language. S4 is designed as a highly distributed
system. Throughput can be increased linearly by adding nodes into a cluster. The S4 design is
best suited for large-scale applications for data mining and machine learning in a production
environment.
Top