
Users Online
· Guests Online: 13
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
Forum Threads
Newest Threads
No Threads created
Hottest Threads
No Threads created
Latest Articles
FAQ: Big Data Deployment Patterns
| FAQ (Frequently Asked Questions) >Big Data Deployment Patterns |
8_1. What do you mean by Big Data Deployment
Big data deployment involves distributed computing, multiple clusters, networks, and firewalls. The infrastructure involves complicated horizontal scaling, and the inclusion of the cloud in some scenarios makes it more complex.
Deployment patterns you can use to deal with this complexity up front and align with the other patterns across various layers.
Big Data Infrastructure: Hybrid Architecture Patterns
Infrastructure for a big data implementation includes storage, network, and processing power units. In addition to Hadoop clusters, security infrastructure for data traffic from multiple data centers and infrastructure for uploading data to downstream systems and/or a data center might be needed. Appliances or NoSQL data storage layers might
require additional infrastructure for storage of data and metadata.
A variety of products and/or services can be used to implement a hybrid infrastructure. Various hybrid
architecture patterns are discussed in the next sections. Each pattern is presented as a problem in the form of a question, followed by an answer in the form of a diagram.
Top
Big data deployment involves distributed computing, multiple clusters, networks, and firewalls. The infrastructure involves complicated horizontal scaling, and the inclusion of the cloud in some scenarios makes it more complex.
Deployment patterns you can use to deal with this complexity up front and align with the other patterns across various layers.
Big Data Infrastructure: Hybrid Architecture Patterns
Infrastructure for a big data implementation includes storage, network, and processing power units. In addition to Hadoop clusters, security infrastructure for data traffic from multiple data centers and infrastructure for uploading data to downstream systems and/or a data center might be needed. Appliances or NoSQL data storage layers might
require additional infrastructure for storage of data and metadata.
A variety of products and/or services can be used to implement a hybrid infrastructure. Various hybrid
architecture patterns are discussed in the next sections. Each pattern is presented as a problem in the form of a question, followed by an answer in the form of a diagram.
Top
8_2. Ingesting data into a Hadoop platform sequentially would take a huge amount of time. What infrastructure pattern can help you ingest data as fast as possible into as many data nodes as possible?
Traditional Tree Network Pattern
Implement a traditional tree network pattern (Figure 8-1).
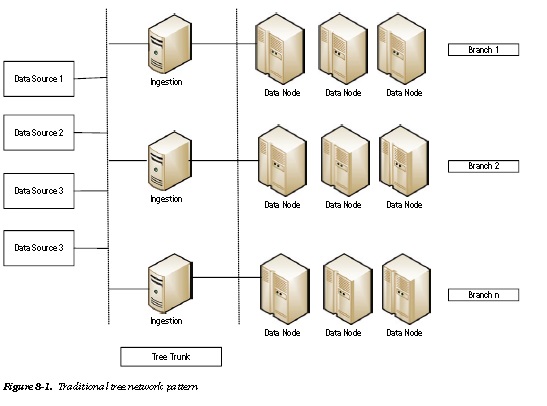
Uploading or transferring bulk data into the Hadoop layer is the first requirement encountered in finalizing the Hadoop infrastructure. Flume or SFTP can be used as the ingestion tool or framework, but until the data is uploaded, typically in terabyte-scale volumes, into the Hadoop ecosystem, no processing can start. Sequential ingestion would consume hours or days. To reduce the ingestion time significantly, simultaneous ingestion can be effected by implementing the traditional tree network pattern. This pattern entails using Flume or some alternative framework to channelize multiple agents in multiple nodes (trunks) that run in parallel and feed into Hadoop ecosystem branches.
Top
Traditional Tree Network Pattern
Implement a traditional tree network pattern (Figure 8-1).
Uploading or transferring bulk data into the Hadoop layer is the first requirement encountered in finalizing the Hadoop infrastructure. Flume or SFTP can be used as the ingestion tool or framework, but until the data is uploaded, typically in terabyte-scale volumes, into the Hadoop ecosystem, no processing can start. Sequential ingestion would consume hours or days. To reduce the ingestion time significantly, simultaneous ingestion can be effected by implementing the traditional tree network pattern. This pattern entails using Flume or some alternative framework to channelize multiple agents in multiple nodes (trunks) that run in parallel and feed into Hadoop ecosystem branches.
Top
8_3. When data is being distributed across multiple nodes, how do you deploy and store client data securely?
Resource Negotiator Pattern for Security and Data Integrity
Implement a resource negotiator pattern (Figure 8-2).
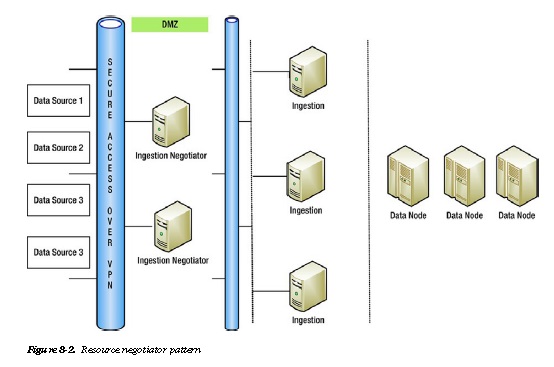
Clients might be wary of transferring data to the Hadoop ecosystem if it is not secure or if the channel through
which the data is uploaded is not secure. For its part, the data center in which the Hadoop ecosytem resides might not want to expose the Hadoop cluster directly, preferring to interpose a proxy to intercept the data and then ingest it in the Hadoop ecosystem.
Proxy interposition is effected by implementing a resource negotiator pattern (Figure 8-2). Data from the client source is securely ingested into negotiator nodes, which sit in a different network ring-fenced by firewalls. Discrete batch job flows ingest data from these negotiator nodes into the Hadoop ecosystem. This double separation ensures
security for both the source data center and the target Hadoop data center.
The high processing, storage, and server costs entailed by negotiator nodes might urge you to replace them with an intermediate Hadoop storage ecosystem, as depicted in Figure 8-3. This latter solution, which is particularly appropriate for configurations in which data is being ingested from multiple data centers, gives rise to spine fabric and federation patterns.
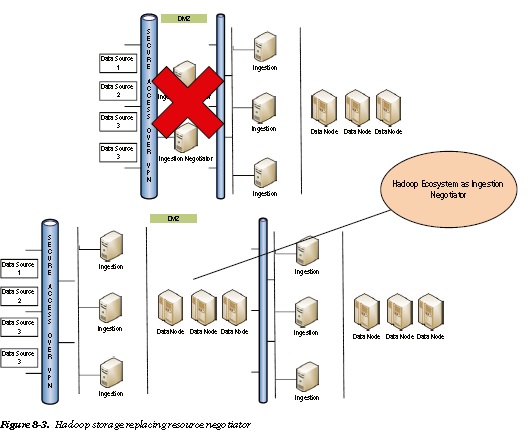
Top
Resource Negotiator Pattern for Security and Data Integrity
Implement a resource negotiator pattern (Figure 8-2).
Clients might be wary of transferring data to the Hadoop ecosystem if it is not secure or if the channel through
which the data is uploaded is not secure. For its part, the data center in which the Hadoop ecosytem resides might not want to expose the Hadoop cluster directly, preferring to interpose a proxy to intercept the data and then ingest it in the Hadoop ecosystem.
Proxy interposition is effected by implementing a resource negotiator pattern (Figure 8-2). Data from the client source is securely ingested into negotiator nodes, which sit in a different network ring-fenced by firewalls. Discrete batch job flows ingest data from these negotiator nodes into the Hadoop ecosystem. This double separation ensures
security for both the source data center and the target Hadoop data center.
The high processing, storage, and server costs entailed by negotiator nodes might urge you to replace them with an intermediate Hadoop storage ecosystem, as depicted in Figure 8-3. This latter solution, which is particularly appropriate for configurations in which data is being ingested from multiple data centers, gives rise to spine fabric and federation patterns.
Top
8_4. How do you handle data coming in from multiple data sources with varying degrees of security implementation?
Spine Fabric Pattern
Implement a spine fabric pattern (Figure 8-4).
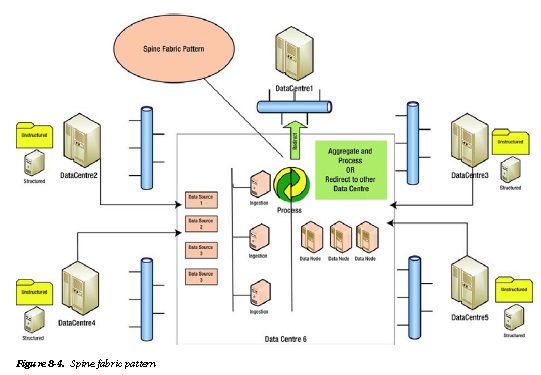
Data from multiple data centers, whether structured logs and reports or unstructured data, can be moved to a spine Hadoop ecosystem, which redirects the data to a target Hadoop ecosystem within the data center or in an
external data center. The advantage of the spine fabric pattern is that the end data center is abstracted from the source data centers and new sources can be easily ingested without making any changes to the deployment pattern of the target or spine Hadoop ecosystems.
Top
Spine Fabric Pattern
Implement a spine fabric pattern (Figure 8-4).
Data from multiple data centers, whether structured logs and reports or unstructured data, can be moved to a spine Hadoop ecosystem, which redirects the data to a target Hadoop ecosystem within the data center or in an
external data center. The advantage of the spine fabric pattern is that the end data center is abstracted from the source data centers and new sources can be easily ingested without making any changes to the deployment pattern of the target or spine Hadoop ecosystems.
Top
8_5. Can data from multiple sources be zoned and then processed?
Federation Pattern
Implement a federation pattern (Figure 8-5).

In a federation pattern, the Hadoop ecosystem in the data center where the big data is processed splits and redirects the processed data to other Hadoop clusters within the same data center or in external data centers.
Top
Federation Pattern
Implement a federation pattern (Figure 8-5).
In a federation pattern, the Hadoop ecosystem in the data center where the big data is processed splits and redirects the processed data to other Hadoop clusters within the same data center or in external data centers.
Top
8_6. How can you automate infrastructure and cluster creation as virtual machine (VM) instances?
Lean DevOps Pattern
Implement a Lean DevOps pattern (Figure 8-6).
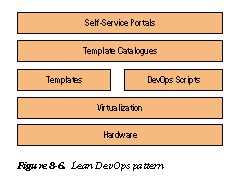
Agile Infrastructure-as-a-Code (IaaC) scripts (exemplified by such products as Chef and Puppet) can be used to create templates of environment configurations and to re-create the whole virtual machine (VM) cluster and/or infrastructure as needed. Infrastructure teams and application teams might need to collaborate in the creation of instance and server templates to configure the applications and batch jobs properly.
Because every entitywhether it is a Hadoop component (such as a data node or hive metastore) or an application component (such as a visualization or analytics tool) has to be converted into a template and configured.
Licenses for each component have to be manually configured. To be on the safe side, have the product vendor provide you with a virtual licensing policy that can facilitate your creation of templates. If the infrastructure is hardened in conformity with organizational policies, the vendor product might have to be reconfigured to ensure that it installs and runs successfully.
IBMs SmartCloud Orchestrator and OpsCode Chef are examples of popular DevOps implementation products.
The Lean DevOps pattern has been successfully implemented by Netflix on Amazon Web Services Cloud.
Top
Lean DevOps Pattern
Implement a Lean DevOps pattern (Figure 8-6).
Agile Infrastructure-as-a-Code (IaaC) scripts (exemplified by such products as Chef and Puppet) can be used to create templates of environment configurations and to re-create the whole virtual machine (VM) cluster and/or infrastructure as needed. Infrastructure teams and application teams might need to collaborate in the creation of instance and server templates to configure the applications and batch jobs properly.
Because every entitywhether it is a Hadoop component (such as a data node or hive metastore) or an application component (such as a visualization or analytics tool) has to be converted into a template and configured.
Licenses for each component have to be manually configured. To be on the safe side, have the product vendor provide you with a virtual licensing policy that can facilitate your creation of templates. If the infrastructure is hardened in conformity with organizational policies, the vendor product might have to be reconfigured to ensure that it installs and runs successfully.
IBMs SmartCloud Orchestrator and OpsCode Chef are examples of popular DevOps implementation products.
The Lean DevOps pattern has been successfully implemented by Netflix on Amazon Web Services Cloud.
Top
8_7. Can you avoid operational overheads by utilizing services available on the cloud?
Data residing in a data center can utilize the processing power of the cloud (Figure 8-7).

There are several cloud options available for big data. AWS provides infrastructure as well as Amazon Elastic MapReduce (EMR). SAP provides the packaged software solution SAP OnDemand. IBM and Oracle provide the DevOps-based cloud implementations PureFlex/Maximo and Oracle Exalytics, which are offered in the form of self-service portals affording access to whole clusters along with the necessary software libraries. Such systems combine servers, storage, networking, virtualization, and management into a single infrastructure system.
Top
Data residing in a data center can utilize the processing power of the cloud (Figure 8-7).
There are several cloud options available for big data. AWS provides infrastructure as well as Amazon Elastic MapReduce (EMR). SAP provides the packaged software solution SAP OnDemand. IBM and Oracle provide the DevOps-based cloud implementations PureFlex/Maximo and Oracle Exalytics, which are offered in the form of self-service portals affording access to whole clusters along with the necessary software libraries. Such systems combine servers, storage, networking, virtualization, and management into a single infrastructure system.
Top
8_8. Hadoop distributions provide dashboards to monitor the health of various nodes. Should a data center have an additional monitoring mechanism?
Hadoop distributions such as Cloudera Manager have been found to suffer occasional limitations in fully representing the health of various nodes because of failure by its agents. It is therefore advisable to supplement your Hadoop monitoring tools with end-to-end IT operations tools, such as Nagios or ZenOS.
Top
Hadoop distributions such as Cloudera Manager have been found to suffer occasional limitations in fully representing the health of various nodes because of failure by its agents. It is therefore advisable to supplement your Hadoop monitoring tools with end-to-end IT operations tools, such as Nagios or ZenOS.
Top