
Users Online
· Guests Online: 13
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
Forum Threads
Newest Threads
No Threads created
Hottest Threads
No Threads created
Latest Articles
Articles Hierarchy
Java Interviews questions for Java Part 2
Q 23: What is serialization? How would you exclude a field of a class from serialization or what is a transient variable? What is the common use? What is a serial version id? LF SI PI FAQ
A 23: Serialization is a process of reading or writing an object. It is a process of saving an objects state to a sequence of bytes, as well as a process of rebuilding those bytes back into a live object at some future time. An object is marked serializable by implementing the java.io.Serializable interface, which is only a marker interface -- it simply allows the serialization mechanism to verify that the class can be persisted, typically to a file.
Transient variables cannot be serialized. The fields marked transient in a serializable object will not be
transmitted in the byte stream. An example would be a file handle, a database connection, a system thread etc. Such objects are only meaningful locally. So they should be marked as transient in a serializable class.
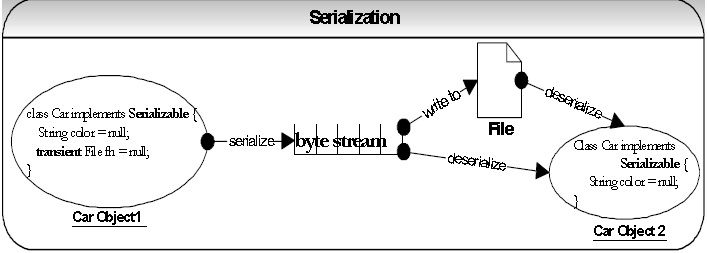
Serialization can adversely affect performance since it:
Depends on reflection.
Has an incredibly verbose data format.
Is very easy to send surplus data.
Q. When to use serialization?
Do not use serialization if you do not have to. A common use of serialization is to use it to send an object over the network or if the state of an object needs to be persisted to a flat file or a database. (Refer Q57 on Enterprise section). Deep cloning or copy can be achieved through serialization. This may be fast to code but will have performance implications (Refer Q26 in Java section).
To serialize the above Car object to a file (sample for illustration purpose only, should use try {} catch {} block):
Car car = new Car(); // The Car class implements a java.io.Serializable interface
FileOutputStream fos = new FileOutputStream(filename);
ObjectOutputStream out = new ObjectOutputStream(fos);
out.writeObject(car); // serialization mechanism happens here
out.close();
The objects stored in an HTTP session should be serializable to support in-memory replication of sessions to
achieve scalability (Refer Q20 in Enterprise section). Objects are passed in RMI (Remote Method Invocation)
across network using serialization (Refer Q57 in Enterprise section).
Q. What is Java Serial Version ID?
Say you create a Car class, instantiate it, and write it out to an object stream. The flattened car object sits in the file system for some time. Meanwhile, if the Car class is modified by adding a new field. Later on, when you try to read (i.e. deserialize) the flattened Car object, you get the java.io.InvalidClassException because all serializable classes are automatically given a unique identifier. This exception is thrown when the identifier of the class is not equal to the identifier of the flattened object. If you really think about it, the exception is thrown because of the addition of the new field. You can avoid this exception being thrown by controlling the versioning yourself by declaring an explicit serialVersionUID. There is also a small performance benefit in explicitly declaring your serialVersionUID (because does not have to be calculated). So, it
is best practice to add your own serialVersionUID to your Serializable classes as soon as you create them as
shown below:
public class Car {
static final long serialVersionUID = 1L; //assign a long value
}
Note: Alternatively you can use the serialver tool comes with Suns JDK. This tool takes a full class name on the command line and returns the serialVersionUID for that compiled class. For example:
static final long serialVersionUID = 10275439472837494L; //generated by serialver tool.
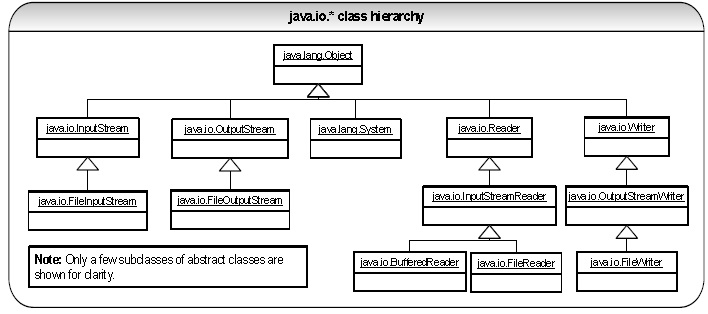
Q 24: Explain the Java I/O streaming concept and the use of the decorator design pattern in Java I/O? LF DP PI SI
A 24: Java input and output is defined in terms of an abstract concept called a stream, which is a sequence of data.
There are 2 kinds of streams.
Byte streams (8 bit bytes) Abstract classes are: InputStream and OutputStream
Character streams (16 bit UNICODE) Abstract classes are: Reader and Writer
Design pattern: java.io.* classes use the decorator design pattern. The decorator design pattern attaches
responsibilities to objects at runtime. Decorators are more flexible than inheritance because the inheritance
attaches responsibility to classes at compile time. The java.io.* classes use the decorator pattern to construct
different combinations of behavior at runtime based on some basic classes.

Q. How does the new I/O (NIO) offer better scalability and better performance?
Java has long been not suited for developing programs that perform a lot of I/O operations. Furthermore,
commonly needed tasks such as file locking, non-blocking and asynchronous I/O operations and ability to map file
to memory were not available. Non-blocking I/O operations were achieved through work around such as
multithreading or using JNI. The New I/O API (aka NIO) in J2SE 1.4 has changed this situation.
A servers ability to handle several client requests effectively depends on how it uses I/O streams. When a server has to handle hundreds of clients simultaneously, it must be able to use I/O services concurrently. One way to cater for this scenario in Java is to use threads but having almost one-to-one ratio of threads (100 clients will have 100 threads) is prone to enormous thread overhead and can result in performance and scalability problems due to consumption of memory stacks (i.e. each thread has its own stack. Refer Q34, Q42 in Java section) and CPU context switching (i.e. switching between threads as opposed to doing real computation.). To overcome this problem, a new set of non-blocking I/O classes have been introduced to the Java platform in java.nio package.
The non-blocking I/O mechanism is built around Selectors and Channels. Channels, Buffers and Selectors are
the core of the NIO.
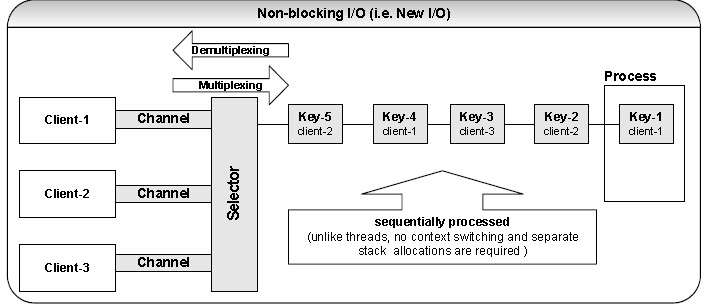
A Channel class represents a bi-directional communication channel (similar to InputStream and OutputStream)
between datasources such as a socket, a file, or an application component, which is capable of performing one or
more I/O operations such as reading or writing. Channels can be non-blocking, which means, no I/O operation will
wait for data to be read or written to the network. The good thing about NIO channels is that they can be
asynchronously interrupted and closed. So if a thread is blocked in an I/O operation on a channel, another thread
can interrupt that blocked thread.
A Selector class enables multiplexing (combining multiple streams into a single stream) and demultiplexing
(separating a single stream into multiple streams) I/O events and makes it possible for a single thread to efficiently
manage many I/O channels. A Selector monitors selectable channels, which are registered with it for I/O events
like connect, accept, read and write. The keys (i.e. Key1, Key2 etc represented by the SelectionKey class)
encapsulate the relationship between a specific selectable channel and a specific selector.
Buffers hold data. Channels can fill and drain Buffers. Buffers replace the need for you to do your own buffer
management using byte arrays. There are different types of Buffers like ByteBuffer, CharBuffer, DoubleBuffer, etc.
Design pattern: NIO uses a reactor design pattern, which demultiplexes events (separating single stream into
multiple streams) and dispatches them to registered object handlers. The reactor pattern is similar to an observer pattern (aka publisher and subscriber design pattern), but an observer pattern handles only a single source of events (i.e. a single publisher with multiple subscribers) where a reactor pattern handles multiple event sources (i.e. multiple publishers with multiple subscribers). The intent of an observer pattern is to define a one-to-many dependency so that when one object (i.e. the publisher) changes its state, all its dependents (i.e. all its subscribers) are notified and updated correspondingly.
Another sought after functionality of NIO is its ability to map a file to memory. There is a specialized form of a
Buffer known as MappedByteBuffer, which represents a buffer of bytes mapped to a file. To map a file to
MappedByteBuffer, you must first get a channel for a file. Once you get a channel then you map it to a buffer and subsequently you can access it like any other ByteBuffer. Once you map an input file to a CharBuffer, you can do pattern matching on the file contents. This is similar to running grep on a UNIX file system. Another feature of NIO is its ability to lock and unlock files. Locks can be exclusive or shared and can be held on a contiguous portion of a file. But file locks are subject to the control of the underlying operating system.
Q 25: How can you improve Java I/O performance? PI BP
A 25: Java applications that utilize Input/Output are excellent candidates for performance tuning. Profiling of Java applications that handle significant volumes of data will show significant time spent in I/O operations. This means substantial gains can be had from I/O performance tuning. Therefore, I/O efficiency should be a high priority for developers looking to optimally increase performance.
The basic rules for speeding up I/O performance are
Minimize accessing the hard disk.
Minimize accessing the underlying operating system.
Minimize processing bytes and characters individually.
Let us look at some of the techniques to improve I/O performance. CO
Use buffering to minimize disk access and underlying operating system. As shown below, with buffering
large chunks of a file are read from a disk and then accessed a byte or character at a time.

Instead of reading a character or a byte at a time, the above code with buffering can be improved further by
reading one line at a time as shown below:
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
while (br.readLine() != null) count++;
By default the System.out is line buffered, which means that the output buffer is flushed when a new line character (i.e. \n) is encountered. This is required for any interactivity between an input prompt and display of output. The line buffering can be disabled for faster I/O operation as follows:
FileOutputStream fos = new FileOutputStream(file);
BufferedOutputStream bos = new BufferedOutputStream(fos, 1024);
PrintStream ps = new PrintStream(bos,false);
// To redirect standard output to a file instead of the System console which is the default for both System.out (i.e.
// standard output) and System.err (i.e. standard error device) variables
System.setOut(ps);
while (someConditionIsTrue)
System.out.println(blah blah );
}
It is recommended to use logging frameworks like Log4J with SLF4J (Simple Logging Façade for Java),
which uses buffering instead of using default behavior of System.out.println( ..) for better performance.
Frameworks like Log4J are configurable, flexible, extensible and easy to use.
Use the NIO package, if you are using JDK 1.4 or later, which uses performance-enhancing features like
buffers to hold data, memory mapping of files, non-blocking I/O operations etc.
I/O performance can be improved by minimizing the calls to the underlying operating systems. The Java runtime itself cannot know the length of a file, querying the file system for isDirectory(), isFile(), exists() etc must query the underlying operating system.
Where applicable caching can be used to improve performance by reading in all the lines of a file into a Java Collection class like an ArrayList or a HashMap and subsequently access the data from an in-memory collection instead of the disk.
Q 26: What is the main difference between shallow cloning and deep cloning of objects? DC LF MI PI
A 26: The default behavior of an objects clone() method automatically yields a shallow copy. So to achieve a deep copy the classes must be edited or adjusted.
Shallow copy: If a shallow copy is performed on obj-1 as shown in fig-2 then it is copied but its contained objects are not. The contained objects Obj-1 and Obj-2 are affected by changes to cloned Obj-2. Java supports shallow cloning of objects by default when a class implements the java.lang.Cloneable interface.
Deep copy: If a deep copy is performed on obj-1 as shown in fig-3 then not only obj-1 has been copied but the objects contained within it have been copied as well. Serialization can be used to achieve deep cloning. Deep cloning through serialization is faster to develop and easier to maintain but carries a performance overhead.
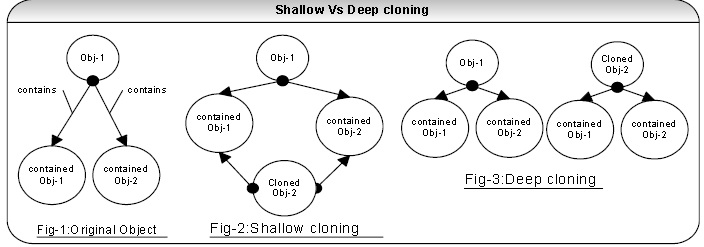
For example invoking clone() method on a collection like HashMap, List etc returns a shallow copy of HashMap,
List, instances. This means if you clone a HashMap, the map instance is cloned but the keys and values
themselves are not cloned. If you want a deep copy then a simple method is to serialize the HashMap to a
ByteArrayOutputSream and then deserialize it. This creates a deep copy but does require that all keys and values in the HashMap are Serializable. Main advantage of this approach is that it will deep copy any arbitrary object graph. Refer Q23 in Java section for deep copying using Serialization. Alternatively you can provide a static factory method to deep copy. Example: to deep copy a list of Car objects.
public static List deepCopy(List listCars) {
List copiedList = new ArrayList(10);
for (Object object : listCars) { //JDK 1.5 for each loop
Car original = (Car)object;
Car carCopied = new Car(); //instantiate a new Car object
carCopied.setColor((original.getColor()));
copiedList.add(carCopied);
}
return copiedList;
}
Q 27: What is the difference between an instance variable and a static variable? How does a local variable compare to an instance or a static variable? Give an example where you might use a static variable? LF FAQ

Q 28: Give an example where you might use a static method? LF FAQ
A 28: Static methods prove useful for creating utility classes, singleton classes and factory methods (Refer Q51, Q52 in Java section). Utility classes are not meant to be instantiated. Improper coding of utility classes can lead to procedural coding. java.lang.Math, java.util.Collections etc are examples of utility classes in Java.
Q 29: What are access modifiers? LF FAQ
A 29:
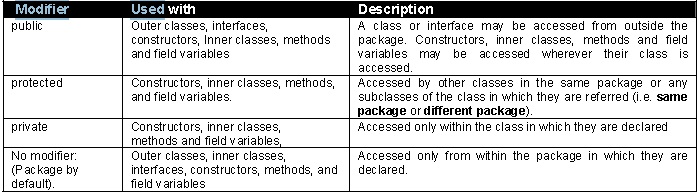
Q 30: Where and how can you use a private constructor? LF FAQ
A 30: Private constructor is used if you do not want other classes to instantiate the object and to prevent subclassing. The instantiation is done by a public static method (i.e. a static factory method) within the same class.
- Used in the singleton design pattern. (Refer Q51 in Java section).
- Used in the factory method design pattern (Refer Q52 in Java section). e.g. java.util.Collections class (Refer
Q16 in Java section).
- Used in utility classes e.g. StringUtils etc.
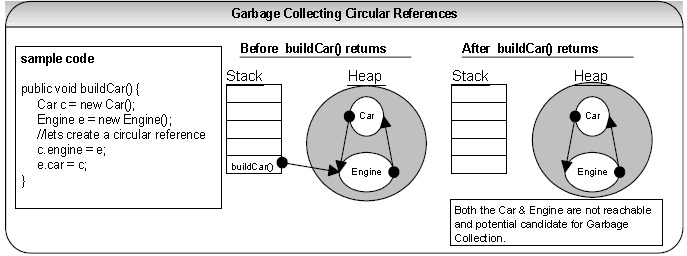
Q 38: If you have a circular reference of objects, but you no longer reference it from an execution thread, will this object be a potential candidate for garbage collection? LF MI
A 38: Yes. Refer diagram below.
Q 39: Discuss the Java error handling mechanism? What is the difference between Runtime (unchecked) exceptions and checked exceptions? What is the implication of catching all the exceptions with the type Exception? EH BP FAQ
A 39:
Errors: When a dynamic linking failure or some other hard failure in the virtual machine occurs, the virtual
machine throws an Error. Typical Java programs should not catch Errors. In addition, its unlikely that typical Java programs will ever throw Errors either.
Exceptions: Most programs throw and catch objects that derive from the Exception class. Exceptions indicate
that a problem occurred but that the problem is not a serious JVM problem. An Exception class has many
subclasses. These descendants indicate various types of exceptions that can occur. For example,
NegativeArraySizeException indicates that a program attempted to create an array with a negative size. One
exception subclass has special meaning in the Java language: RuntimeException. All the exceptions except
RuntimeException are compiler checked exceptions. If a method is capable of throwing a checked exception it
must declare it in its method header or handle it in a try/catch block. Failure to do so raises a compiler error. So checked exceptions can, at compile time, greatly reduce the occurrence of unhandled exceptions surfacing at runtime in a given application at the expense of requiring large throws declarations and encouraging use of poorlyconstructed try/catch blocks. Checked exceptions are present in other languages like C++, C#, and Python.
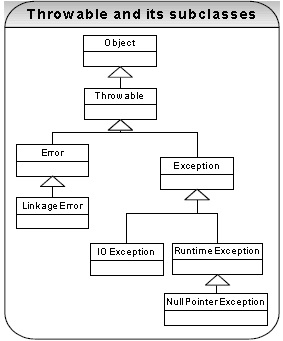
Runtime Exceptions (unchecked exception)
A RuntimeException class represents exceptions that occur within the Java virtual machine (during runtime). An example of a runtime exception is NullPointerException. The cost of checking for the runtime exception often outweighs the benefit of catching it. Attempting to catch or specify all of them all the time would make your code unreadable and unmaintainable. The compiler allows runtime exceptions to go uncaught and unspecified. If you like, you can catch these exceptions just like other exceptions. However, you do not have to declare it in your throws" clause or catch it in your catch clause. In addition, you can create your own RuntimeException subclasses and this approach is probably preferred at times because checked exceptions can complicate method signatures and can be difficult to follow.
Q. What are the exception handling best practices: BP
1. Q. Why is it not advisable to catch type Exception? CO
Exception handling in Java is polymorphic in nature. For example if you catch type Exception in your code then it can catch or throw its descendent types like IOException as well. So if you catch the type Exception before the type IOException then the type Exception block will catch the entire exceptions and type IOException block is never reached. In order to catch the type IOException and handle it differently to type Exception, IOException should be caught first (remember that you cant have a bigger basket above a smaller basket).
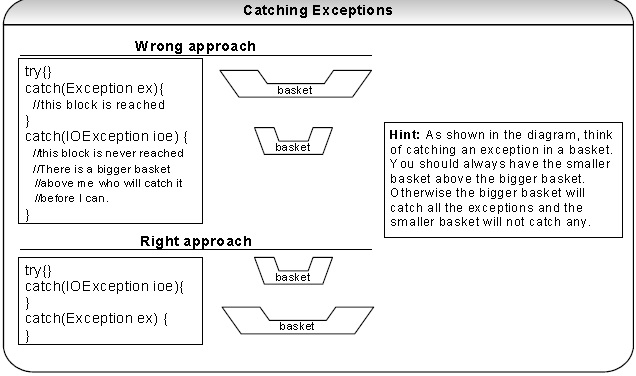
The diagram above is an example for illustration only. In practice it is not recommended to catch type
Exception. We should only catch specific subtypes of the Exception class. Having a bigger basket (i.e.
Exception) will hide or cause problems. Since the RunTimeException is a subtype of Exception, catching the type Exception will catch all the run time exceptions (like NullPointerException, ArrayIndexOutOfBoundsException) as well.
Example: The FileNotFoundException is extended (i.e. inherited) from the IOException. So (subclasses have to
be caught first) FileNotFoundException (small basket) should be caught before IOException (big basket).
2. Q. Why should you throw an exception early? CO
The exception stack trace helps you pinpoint where an exception occurred by showing you the exact sequence of method calls that lead to the exception. By throwing your exception early, the exception becomes more accurate and more specific. Avoid suppressing or ignoring exceptions. Also avoid using exceptions just to get a flow control. Instead of:
// assume this line throws an exception because filename == null.
InputStream in = new FileInputStream(fileName);
if(filename == null) {
throw new IllegalArgumentException(file name is null);
}
InputStream in = new FileInputStream(fileName);
3. Why should you catch a checked exception late in a catch {} block?
You should not try to catch the exception before your program can handle it in an appropriate manner. The natural tendency when a compiler complains about a checked exception is to catch it so that the compiler stops reporting errors. It is a bad practice to sweep the exceptions under the carpet by catching it and not doing anything with it.
The best practice is to catch the exception at the appropriate layer (e.g. an exception thrown at an integration layer can be caught at a presentation layer in a catch {} block), where your program can either meaningfully recover from the exception and continue to execute or log the exception only once in detail, so that user can identify the cause of the exception.
4. Q. When should you use a checked exception and when should you use an unchecked exception?
Due to heavy use of checked exceptions and minimal use of unchecked exceptions, there has been a hot debate in the Java community regarding true value of checked exceptions. Use checked exceptions when the client code can take some useful recovery action based on information in exception. Use unchecked exception when client code cannot do anything. For example Convert your SQLException into another checked exception if the client code can recover from it. Convert your SQLException into an unchecked (i.e. RuntimeException) exception, if the client code can not recover from it. (Note: Hibernate 3 & Spring uses RuntimeExceptions prevalently).
Important: throw an exception early and catch an exception late but do not sweep n exception under the carpet by catching it and not doing anything with it. This will hide problems and it will be hard to debug and fix. CO
A note on key words for error handling:
throw / throws used to pass an exception to the method that called it.
try block of code will be tried but may cause an exception.
catch declares the block of code, which handles the exception.
finally block of code, which is always executed (except System.exit(0) call) no matter what program flow, occurs
when dealing with an exception.
assert Evaluates a conditional expression to verify the programmers assumption.
Q 40: What is a user defined exception? EH
A 40: User defined exceptions may be implemented by defining a new exception class by extending the Exception class.
public class MyException extends Exception {
/* class definition of constructors goes here */
public MyException() {
super();
}
public MyException (String errorMessage) {
super (errorMessage);
}
}
Throw and/or throws statement is used to signal the occurrence of an exception. To throw an exception:
throw new MyException(I threw my own exception.)
To declare an exception: public myMethod() throws MyException { }
A 23: Serialization is a process of reading or writing an object. It is a process of saving an objects state to a sequence of bytes, as well as a process of rebuilding those bytes back into a live object at some future time. An object is marked serializable by implementing the java.io.Serializable interface, which is only a marker interface -- it simply allows the serialization mechanism to verify that the class can be persisted, typically to a file.
Transient variables cannot be serialized. The fields marked transient in a serializable object will not be
transmitted in the byte stream. An example would be a file handle, a database connection, a system thread etc. Such objects are only meaningful locally. So they should be marked as transient in a serializable class.
Serialization can adversely affect performance since it:
Depends on reflection.
Has an incredibly verbose data format.
Is very easy to send surplus data.
Q. When to use serialization?
Do not use serialization if you do not have to. A common use of serialization is to use it to send an object over the network or if the state of an object needs to be persisted to a flat file or a database. (Refer Q57 on Enterprise section). Deep cloning or copy can be achieved through serialization. This may be fast to code but will have performance implications (Refer Q26 in Java section).
To serialize the above Car object to a file (sample for illustration purpose only, should use try {} catch {} block):
Car car = new Car(); // The Car class implements a java.io.Serializable interface
FileOutputStream fos = new FileOutputStream(filename);
ObjectOutputStream out = new ObjectOutputStream(fos);
out.writeObject(car); // serialization mechanism happens here
out.close();
The objects stored in an HTTP session should be serializable to support in-memory replication of sessions to
achieve scalability (Refer Q20 in Enterprise section). Objects are passed in RMI (Remote Method Invocation)
across network using serialization (Refer Q57 in Enterprise section).
Q. What is Java Serial Version ID?
Say you create a Car class, instantiate it, and write it out to an object stream. The flattened car object sits in the file system for some time. Meanwhile, if the Car class is modified by adding a new field. Later on, when you try to read (i.e. deserialize) the flattened Car object, you get the java.io.InvalidClassException because all serializable classes are automatically given a unique identifier. This exception is thrown when the identifier of the class is not equal to the identifier of the flattened object. If you really think about it, the exception is thrown because of the addition of the new field. You can avoid this exception being thrown by controlling the versioning yourself by declaring an explicit serialVersionUID. There is also a small performance benefit in explicitly declaring your serialVersionUID (because does not have to be calculated). So, it
is best practice to add your own serialVersionUID to your Serializable classes as soon as you create them as
shown below:
public class Car {
static final long serialVersionUID = 1L; //assign a long value
}
Note: Alternatively you can use the serialver tool comes with Suns JDK. This tool takes a full class name on the command line and returns the serialVersionUID for that compiled class. For example:
static final long serialVersionUID = 10275439472837494L; //generated by serialver tool.
Q 24: Explain the Java I/O streaming concept and the use of the decorator design pattern in Java I/O? LF DP PI SI
A 24: Java input and output is defined in terms of an abstract concept called a stream, which is a sequence of data.
There are 2 kinds of streams.
Byte streams (8 bit bytes) Abstract classes are: InputStream and OutputStream
Character streams (16 bit UNICODE) Abstract classes are: Reader and Writer
Design pattern: java.io.* classes use the decorator design pattern. The decorator design pattern attaches
responsibilities to objects at runtime. Decorators are more flexible than inheritance because the inheritance
attaches responsibility to classes at compile time. The java.io.* classes use the decorator pattern to construct
different combinations of behavior at runtime based on some basic classes.
Q. How does the new I/O (NIO) offer better scalability and better performance?
Java has long been not suited for developing programs that perform a lot of I/O operations. Furthermore,
commonly needed tasks such as file locking, non-blocking and asynchronous I/O operations and ability to map file
to memory were not available. Non-blocking I/O operations were achieved through work around such as
multithreading or using JNI. The New I/O API (aka NIO) in J2SE 1.4 has changed this situation.
A servers ability to handle several client requests effectively depends on how it uses I/O streams. When a server has to handle hundreds of clients simultaneously, it must be able to use I/O services concurrently. One way to cater for this scenario in Java is to use threads but having almost one-to-one ratio of threads (100 clients will have 100 threads) is prone to enormous thread overhead and can result in performance and scalability problems due to consumption of memory stacks (i.e. each thread has its own stack. Refer Q34, Q42 in Java section) and CPU context switching (i.e. switching between threads as opposed to doing real computation.). To overcome this problem, a new set of non-blocking I/O classes have been introduced to the Java platform in java.nio package.
The non-blocking I/O mechanism is built around Selectors and Channels. Channels, Buffers and Selectors are
the core of the NIO.
A Channel class represents a bi-directional communication channel (similar to InputStream and OutputStream)
between datasources such as a socket, a file, or an application component, which is capable of performing one or
more I/O operations such as reading or writing. Channels can be non-blocking, which means, no I/O operation will
wait for data to be read or written to the network. The good thing about NIO channels is that they can be
asynchronously interrupted and closed. So if a thread is blocked in an I/O operation on a channel, another thread
can interrupt that blocked thread.
A Selector class enables multiplexing (combining multiple streams into a single stream) and demultiplexing
(separating a single stream into multiple streams) I/O events and makes it possible for a single thread to efficiently
manage many I/O channels. A Selector monitors selectable channels, which are registered with it for I/O events
like connect, accept, read and write. The keys (i.e. Key1, Key2 etc represented by the SelectionKey class)
encapsulate the relationship between a specific selectable channel and a specific selector.
Buffers hold data. Channels can fill and drain Buffers. Buffers replace the need for you to do your own buffer
management using byte arrays. There are different types of Buffers like ByteBuffer, CharBuffer, DoubleBuffer, etc.
Design pattern: NIO uses a reactor design pattern, which demultiplexes events (separating single stream into
multiple streams) and dispatches them to registered object handlers. The reactor pattern is similar to an observer pattern (aka publisher and subscriber design pattern), but an observer pattern handles only a single source of events (i.e. a single publisher with multiple subscribers) where a reactor pattern handles multiple event sources (i.e. multiple publishers with multiple subscribers). The intent of an observer pattern is to define a one-to-many dependency so that when one object (i.e. the publisher) changes its state, all its dependents (i.e. all its subscribers) are notified and updated correspondingly.
Another sought after functionality of NIO is its ability to map a file to memory. There is a specialized form of a
Buffer known as MappedByteBuffer, which represents a buffer of bytes mapped to a file. To map a file to
MappedByteBuffer, you must first get a channel for a file. Once you get a channel then you map it to a buffer and subsequently you can access it like any other ByteBuffer. Once you map an input file to a CharBuffer, you can do pattern matching on the file contents. This is similar to running grep on a UNIX file system. Another feature of NIO is its ability to lock and unlock files. Locks can be exclusive or shared and can be held on a contiguous portion of a file. But file locks are subject to the control of the underlying operating system.
Q 25: How can you improve Java I/O performance? PI BP
A 25: Java applications that utilize Input/Output are excellent candidates for performance tuning. Profiling of Java applications that handle significant volumes of data will show significant time spent in I/O operations. This means substantial gains can be had from I/O performance tuning. Therefore, I/O efficiency should be a high priority for developers looking to optimally increase performance.
The basic rules for speeding up I/O performance are
Minimize accessing the hard disk.
Minimize accessing the underlying operating system.
Minimize processing bytes and characters individually.
Let us look at some of the techniques to improve I/O performance. CO
Use buffering to minimize disk access and underlying operating system. As shown below, with buffering
large chunks of a file are read from a disk and then accessed a byte or character at a time.
Instead of reading a character or a byte at a time, the above code with buffering can be improved further by
reading one line at a time as shown below:
FileReader fr = new FileReader(f);
BufferedReader br = new BufferedReader(fr);
while (br.readLine() != null) count++;
By default the System.out is line buffered, which means that the output buffer is flushed when a new line character (i.e. \n) is encountered. This is required for any interactivity between an input prompt and display of output. The line buffering can be disabled for faster I/O operation as follows:
FileOutputStream fos = new FileOutputStream(file);
BufferedOutputStream bos = new BufferedOutputStream(fos, 1024);
PrintStream ps = new PrintStream(bos,false);
// To redirect standard output to a file instead of the System console which is the default for both System.out (i.e.
// standard output) and System.err (i.e. standard error device) variables
System.setOut(ps);
while (someConditionIsTrue)
System.out.println(blah blah );
}
It is recommended to use logging frameworks like Log4J with SLF4J (Simple Logging Façade for Java),
which uses buffering instead of using default behavior of System.out.println( ..) for better performance.
Frameworks like Log4J are configurable, flexible, extensible and easy to use.
Use the NIO package, if you are using JDK 1.4 or later, which uses performance-enhancing features like
buffers to hold data, memory mapping of files, non-blocking I/O operations etc.
I/O performance can be improved by minimizing the calls to the underlying operating systems. The Java runtime itself cannot know the length of a file, querying the file system for isDirectory(), isFile(), exists() etc must query the underlying operating system.
Where applicable caching can be used to improve performance by reading in all the lines of a file into a Java Collection class like an ArrayList or a HashMap and subsequently access the data from an in-memory collection instead of the disk.
Q 26: What is the main difference between shallow cloning and deep cloning of objects? DC LF MI PI
A 26: The default behavior of an objects clone() method automatically yields a shallow copy. So to achieve a deep copy the classes must be edited or adjusted.
Shallow copy: If a shallow copy is performed on obj-1 as shown in fig-2 then it is copied but its contained objects are not. The contained objects Obj-1 and Obj-2 are affected by changes to cloned Obj-2. Java supports shallow cloning of objects by default when a class implements the java.lang.Cloneable interface.
Deep copy: If a deep copy is performed on obj-1 as shown in fig-3 then not only obj-1 has been copied but the objects contained within it have been copied as well. Serialization can be used to achieve deep cloning. Deep cloning through serialization is faster to develop and easier to maintain but carries a performance overhead.
For example invoking clone() method on a collection like HashMap, List etc returns a shallow copy of HashMap,
List, instances. This means if you clone a HashMap, the map instance is cloned but the keys and values
themselves are not cloned. If you want a deep copy then a simple method is to serialize the HashMap to a
ByteArrayOutputSream and then deserialize it. This creates a deep copy but does require that all keys and values in the HashMap are Serializable. Main advantage of this approach is that it will deep copy any arbitrary object graph. Refer Q23 in Java section for deep copying using Serialization. Alternatively you can provide a static factory method to deep copy. Example: to deep copy a list of Car objects.
public static List deepCopy(List listCars) {
List copiedList = new ArrayList(10);
for (Object object : listCars) { //JDK 1.5 for each loop
Car original = (Car)object;
Car carCopied = new Car(); //instantiate a new Car object
carCopied.setColor((original.getColor()));
copiedList.add(carCopied);
}
return copiedList;
}
Q 27: What is the difference between an instance variable and a static variable? How does a local variable compare to an instance or a static variable? Give an example where you might use a static variable? LF FAQ
Q 28: Give an example where you might use a static method? LF FAQ
A 28: Static methods prove useful for creating utility classes, singleton classes and factory methods (Refer Q51, Q52 in Java section). Utility classes are not meant to be instantiated. Improper coding of utility classes can lead to procedural coding. java.lang.Math, java.util.Collections etc are examples of utility classes in Java.
Q 29: What are access modifiers? LF FAQ
A 29:
Q 30: Where and how can you use a private constructor? LF FAQ
A 30: Private constructor is used if you do not want other classes to instantiate the object and to prevent subclassing. The instantiation is done by a public static method (i.e. a static factory method) within the same class.
- Used in the singleton design pattern. (Refer Q51 in Java section).
- Used in the factory method design pattern (Refer Q52 in Java section). e.g. java.util.Collections class (Refer
Q16 in Java section).
- Used in utility classes e.g. StringUtils etc.
Q 38: If you have a circular reference of objects, but you no longer reference it from an execution thread, will this object be a potential candidate for garbage collection? LF MI
A 38: Yes. Refer diagram below.
Q 39: Discuss the Java error handling mechanism? What is the difference between Runtime (unchecked) exceptions and checked exceptions? What is the implication of catching all the exceptions with the type Exception? EH BP FAQ
A 39:
Errors: When a dynamic linking failure or some other hard failure in the virtual machine occurs, the virtual
machine throws an Error. Typical Java programs should not catch Errors. In addition, its unlikely that typical Java programs will ever throw Errors either.
Exceptions: Most programs throw and catch objects that derive from the Exception class. Exceptions indicate
that a problem occurred but that the problem is not a serious JVM problem. An Exception class has many
subclasses. These descendants indicate various types of exceptions that can occur. For example,
NegativeArraySizeException indicates that a program attempted to create an array with a negative size. One
exception subclass has special meaning in the Java language: RuntimeException. All the exceptions except
RuntimeException are compiler checked exceptions. If a method is capable of throwing a checked exception it
must declare it in its method header or handle it in a try/catch block. Failure to do so raises a compiler error. So checked exceptions can, at compile time, greatly reduce the occurrence of unhandled exceptions surfacing at runtime in a given application at the expense of requiring large throws declarations and encouraging use of poorlyconstructed try/catch blocks. Checked exceptions are present in other languages like C++, C#, and Python.
Runtime Exceptions (unchecked exception)
A RuntimeException class represents exceptions that occur within the Java virtual machine (during runtime). An example of a runtime exception is NullPointerException. The cost of checking for the runtime exception often outweighs the benefit of catching it. Attempting to catch or specify all of them all the time would make your code unreadable and unmaintainable. The compiler allows runtime exceptions to go uncaught and unspecified. If you like, you can catch these exceptions just like other exceptions. However, you do not have to declare it in your throws" clause or catch it in your catch clause. In addition, you can create your own RuntimeException subclasses and this approach is probably preferred at times because checked exceptions can complicate method signatures and can be difficult to follow.
Q. What are the exception handling best practices: BP
1. Q. Why is it not advisable to catch type Exception? CO
Exception handling in Java is polymorphic in nature. For example if you catch type Exception in your code then it can catch or throw its descendent types like IOException as well. So if you catch the type Exception before the type IOException then the type Exception block will catch the entire exceptions and type IOException block is never reached. In order to catch the type IOException and handle it differently to type Exception, IOException should be caught first (remember that you cant have a bigger basket above a smaller basket).
The diagram above is an example for illustration only. In practice it is not recommended to catch type
Exception. We should only catch specific subtypes of the Exception class. Having a bigger basket (i.e.
Exception) will hide or cause problems. Since the RunTimeException is a subtype of Exception, catching the type Exception will catch all the run time exceptions (like NullPointerException, ArrayIndexOutOfBoundsException) as well.
Example: The FileNotFoundException is extended (i.e. inherited) from the IOException. So (subclasses have to
be caught first) FileNotFoundException (small basket) should be caught before IOException (big basket).
2. Q. Why should you throw an exception early? CO
The exception stack trace helps you pinpoint where an exception occurred by showing you the exact sequence of method calls that lead to the exception. By throwing your exception early, the exception becomes more accurate and more specific. Avoid suppressing or ignoring exceptions. Also avoid using exceptions just to get a flow control. Instead of:
// assume this line throws an exception because filename == null.
InputStream in = new FileInputStream(fileName);
if(filename == null) {
throw new IllegalArgumentException(file name is null);
}
InputStream in = new FileInputStream(fileName);
3. Why should you catch a checked exception late in a catch {} block?
You should not try to catch the exception before your program can handle it in an appropriate manner. The natural tendency when a compiler complains about a checked exception is to catch it so that the compiler stops reporting errors. It is a bad practice to sweep the exceptions under the carpet by catching it and not doing anything with it.
The best practice is to catch the exception at the appropriate layer (e.g. an exception thrown at an integration layer can be caught at a presentation layer in a catch {} block), where your program can either meaningfully recover from the exception and continue to execute or log the exception only once in detail, so that user can identify the cause of the exception.
4. Q. When should you use a checked exception and when should you use an unchecked exception?
Due to heavy use of checked exceptions and minimal use of unchecked exceptions, there has been a hot debate in the Java community regarding true value of checked exceptions. Use checked exceptions when the client code can take some useful recovery action based on information in exception. Use unchecked exception when client code cannot do anything. For example Convert your SQLException into another checked exception if the client code can recover from it. Convert your SQLException into an unchecked (i.e. RuntimeException) exception, if the client code can not recover from it. (Note: Hibernate 3 & Spring uses RuntimeExceptions prevalently).
Important: throw an exception early and catch an exception late but do not sweep n exception under the carpet by catching it and not doing anything with it. This will hide problems and it will be hard to debug and fix. CO
A note on key words for error handling:
throw / throws used to pass an exception to the method that called it.
try block of code will be tried but may cause an exception.
catch declares the block of code, which handles the exception.
finally block of code, which is always executed (except System.exit(0) call) no matter what program flow, occurs
when dealing with an exception.
assert Evaluates a conditional expression to verify the programmers assumption.
Q 40: What is a user defined exception? EH
A 40: User defined exceptions may be implemented by defining a new exception class by extending the Exception class.
public class MyException extends Exception {
/* class definition of constructors goes here */
public MyException() {
super();
}
public MyException (String errorMessage) {
super (errorMessage);
}
}
Throw and/or throws statement is used to signal the occurrence of an exception. To throw an exception:
throw new MyException(I threw my own exception.)
To declare an exception: public myMethod() throws MyException { }

Comments
No Comments have been Posted.
Post Comment
Please Login to Post a Comment.