
Users Online
· Guests Online: 9
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
Forum Threads
Newest Threads
No Threads created
Hottest Threads
No Threads created
Latest Articles
Articles Hierarchy
Module 3: Getting Started With Hadoop
Prerequisites
Developing for Hadoop requires a Java programming environment. You can download a Java Development Kit (JDK) for a wide variety of operating systems from http://java.sun.com. Hadoop requires the Java Standard Edition (Java SE), version 6, which is the most current version at the time of this writing.
A Virtual Machine Hadoop Environment
This section explains how to configure a virtual machine to run Hadoop within your host computer. After installing the virtual machine software and the virtual machine image, you will learn how to log in and run jobs within the Hadoop environment.
Users of Linux, Mac OSX, or other Unix-like environments are able to install Hadoop and run it on one (or more) machines with no additional software beyond Java. If you are interested in doing this, there are instructions available on the Hadoop web site in the quickstart document.
Running Hadoop on top of Windows requires installing cygwin, a Linux-like environment that runs within Windows. Hadoop works reasonably well on cygwin, but it is officially for "development purposes only." Hadoop on cygwin may be unstable, and installing cygwin itself can be cumbersome.
To aid developers in getting started easily with Hadoop, we have provided a virtual machine image containing a preconfigured Hadoop installation. The virtual machine image will run inside of a "sandbox" environment in which we can run another operating system. The OS inside the sandbox does not know that there is another operating environment outside of it; it acts as though it is on its own computer. This sandbox environment is referred to as the "guest machine" running a "guest operating system." The actual physical machine running the VM software is referred to as the "host machine" and it runs the "host operating system." The virtual machine provides other host-machine applications with the appearance that another physical computer is available on the same network. Applications running on the host machine see the VM as a separate machine with its own IP address, and can interact with the programs inside the VM in this fashion.
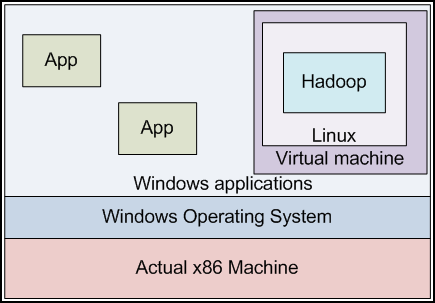
Figure 3.1: A virtual machine encapsulates one operating system within another. Applications in the VM believe they run on a separate physical host from other applications in the external operating system. Here we demonstrate a Windows host machine and a Linux guest (virtual) machine.
Application developers do not need to use the virtual machine to run Hadoop. Developers on Linux typically use Hadoop in their native development environment, and Windows users often install cygwin for Hadoop development. The virtual machine provided with this tutorial allows users a convenient alternative development platform with a minimum of configuration required. Another advantage of the virtual machine is its easy reset functionality. If your experiments break the Hadoop configuration or render the operating system unusable, you can always simply copy the virtual machine image from the CD back to where you installed it on your computer, and start from a known-good state.
Our virtual machine will run Linux, and comes preconfigured to run Hadoop in pseudo-distributed mode on this system. (It is configured like a fully distributed system, but is actually running on a single machine instance.) We can write Hadoop programs using editors and other applications of the host platform, and run them on our "cluster" consisting of just the virtual machine. We will connect our host environment to the virtual machine through the network.
It should be noted that the virtual machine will also run inside of another instance of Linux. Linux users can install the virtual machine software and run the Hadoop VM as well; the same separation between host processes and guest processes applies here.
Installing VMware Player
The virtual machine is designed to run inside of the VMware Player. A copy of the VMware player installer (version 2.5) for both 32-bit Windows and Linux is included here (linux-rpm, linux-bundle, windows-exe). A Getting Started guide for VMware player provides instructions for installing the VMware player. Review the license information for VMware player before using it..
If you are running on a different operating system, or would prefer to download a more recent version of the player, an alternate installation strategy is to navigate to http://info.vmware.com/content/GLP_VMwarePlayer. You will need to register for a "virtualization starter kit." You will receive an email with a link to "Download VMware Player." Click the link, then click the "download now" button at the top of the screen under "most recent version" and follow the instructions. VMware Player is available for Windows or Linux. The latter is available in both 32- and 64-bit versions.
VMware Player itself is approximately a 170 MB download. When the download has completed, run the installer program to set up VMware Player, and follow the prompts as directed. Installation in Windows is performed by a typical Windows installation process.
Setting up the Virtual Environment
Next, copy the Hadoop Virtual Machine into a location on your hard drive. It is a zipped vmware folder (hadoop-vm-appliance-0-18-0) which includes a few files; a .vmdk file that is a snapshot of the virtual machine's hard drive, and a .vmx file which contains the configuration information to start the virtual machine. After unzipping the vmware folder zip file, to start the virtual machine, double-click on the hadoop-appliance-0.18.0.vmx file in Windows Explorer.
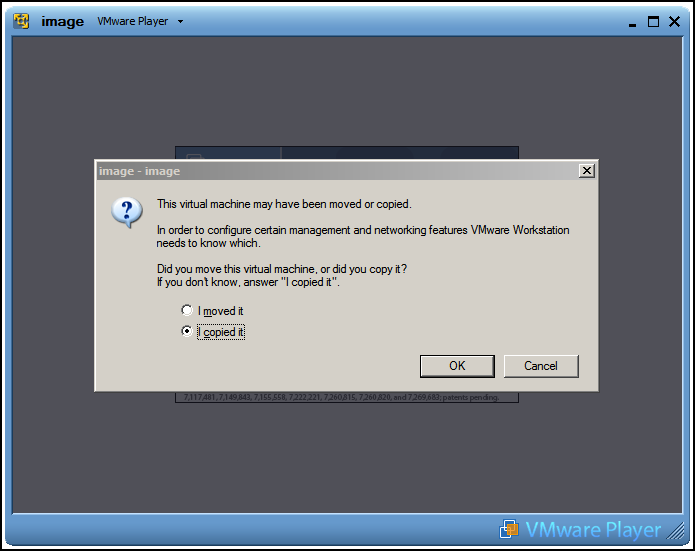
Figure 3.2: When you start the virtual machine for the first time, tell VMware Player that you have copied the VM image.
When you start the virtual machine for the first time, VMware Player will recognize that the virtual machine image is not in the same location it used to be. You should inform VMware Player that you copied this virtual machine image. VMware Player will then generate new session identifiers for this instance of the virtual machine. If you later move the VM image to a different location on your own hard drive, you should tell VMware Player that you have moved the image.
If you ever corrupt the VM image (e.g., by inadvertently deleting or overwriting important files), you can always restore a pristine copy of the virtual machine by copying a fresh VM image off of this tutorial CD. (So don't be shy about exploring! You can always reset it to a functioning state.)
After you select this option and click OK, the virtual machine should begin booting normally. You will see it perform the standard boot procedure for a Linux system. It will bind itself to an IP address on an unused network segment, and then display a prompt allowing a user to log in.
Virtual Machine User Accounts
The virtual machine comes preconfigured with two user accounts: "root" and "hadoop-user". The hadoop-user account has sudo permissions to perform system management functions, such as shutting down the virtual machine. The vast majority of your interaction with the virtual machine will be as hadoop-user.
To log in as hadoop-user, first click inside the virtual machine's display. The virtual machine will take control of your keyboard and mouse. To escape back into Windows at any time, press CTRL+ALT at the same time. The hadoop-user user's password is hadoop. To log in as root, the password is root.
Running a Hadoop Job
Now that the VM is started, or you have installed Hadoop on your own system in pseudo-distributed mode, let us make sure that Hadoop is properly configured.
If you are using the VM, log in as hadoop-user, as directed above. You will start in your home directory: /home/hadoop-user. Typing ls, you will see a directory named hadoop/, as well as a set of scripts to manage the server. The virtual machine's hostname is hadoop-desk.
First, we must start the Hadoop system. Type the following command:
hadoop-user@hadoop-desk:~$ ./start-hadoop
If you installed Hadoop on your host system, use the following commands to launch hadoop (assuming you installed to ~/hadoop):
you@your-machine:~$ cd hadoop
you@your-machine:~/hadoop$ bin/start-all.sh
You will see a set of status messages appear as the services boot. If prompted whether it is okay to connect to the current host, type "yes". Try running an example program to ensure that Hadoop is correctly configured:
hadoop-user@hadoop-desk:~$ cd hadoop
hadoop-user@hadoop-desk:~/hadoop$ bin/hadoop jar hadoop-0.18.0-examples.jar pi 10 1000000
This should provide output that looks something like this:
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
...
Wrote input for Map #10
Starting Job
INFO mapred.FileInputFormat: Total input paths to process: 10
INFO mapred.JobClient: Running job: job_200806230804_0001
INFO mapred.JobClient: map 0% reduce 0%
INFO mapred.JobClient: map 10% reduce 0%
...
INFO mapred.JobClient: map 100% reduce 100%
INFO mapred.JobClient: Job complete: job_200806230804_0001
...
Job Finished in 25.841 second
Estimated value of PI is 3.141688
This task runs a simulation to estimate the value of pi based on sampling. The test first wrote out a number of points to a list of files, one per map task. It then calculated an estimate of pi based on these points, in the MapReduce task itself. How MapReduce works and how to write such a program are discussed in the next module. The Hadoop client program you used to launch the pi test launched the job, displayed some progress update information as to how the job is proceeding, and then displayed some final performance counters and the job-specific output: an estimate for the value of pi.
Accessing the VM via ssh
Rather than directly use the terminal of the virtual machine, you can also log in "remotely" over ssh from the host environment. Using an ssh client like putty (in Windows), log in with username "hadoop-user" (password hadoop) to the IP address displayed in the virtual machine terminal when it starts up. You can now interact with this virtual machine as if it were another Linux machine on the network.
This can only be done from the host machine. The VMware image is, by default, configured to use host-only networking; only the host machine can talk to the virtual machine over its network interface. The virtual machine does not appear on the actual external network. This is done for security purposes.
If you need to find the virtual machine's IP address later, the ifconfig command will display this under the "inet addr" field.
Important security note: In the VMware settings, you can reconfigure the virtual machine for networked access rather than host-only networking. If you enable network access, you can access the virtual machine from anywhere else on the network via its IP address. In this case, you should change the passwords associated with the accounts on the virtual machine to prevent unauthorized users from logging in with the default password.
Shutting Down the VM
When you are done with the virtual machine, you can turn it off by logging in as hadoop-user and typing sudo poweroff. The virtual machine will shut itself down in an orderly fashion and the window it runs in will disappear.
Getting Started With Eclipse
A powerful development environment for Java-based programming is Eclipse. Eclipse is a free, open-source IDE. It supports multiple languages through a plugin interface, with special attention paid to Java. Tools designed for working with Hadoop can be integrated into Eclipse, making it an attractive platform for Hadoop development. In this section we will review how to obtain, configure, and use Eclipse.
Downloading and Installing
Note: The most current release of Eclipse is called Ganymede. Our testing shows that Ganymede is currently incompatible with the Hadoop MapReduce plugin. The most recent version which worked properly with the Hadoop plugin is version 3.3.1, "Europa." To download Europa, do not visit the main Eclipse website; it can be found in the archive site http://archive.eclipse.org/eclipse/downloads/ as the "Archived Release (3.3.1)."
The Eclipse website has several versions available for download; choose either "Eclipse Classic" or "Eclipse IDE for Java Developers."
Because it is written in Java, Eclipse is very cross-platform. Eclipse is available for Windows, Linux, and Mac OSX.
Installing Eclipse is very straightforward. Eclipse is packaged as a .zip file. Windows itself can natively unzip the compressed file into a directory. If you encounter errors using the Windows decompression tool (see [1]), try using a third-party unzip utility such as 7-zip or WinRAR.
After you have decompressed Eclipse into a directory, you can run it straight from that directory with no modifications or other "installation" procedure. You may want to move it into C:\Program Files\Eclipse to keep consistent with your other applications, but it can reside in the Desktop or elsewhere as well.
Installing the Hadoop MapReduce Plugin
Hadoop comes with a plugin for Eclipse that makes developing MapReduce programs easier. In the hadoop-0.18.0/contrib/eclipse-plugin directory on this CD, you will find a file named hadoop-0.18.0-eclipse-plugin.jar. Copy this into the plugins/ subdirectory of wherever you unzipped Eclipse.
Making a Copy of Hadoop
While we will be running MapReduce programs on the virtual machine, we will be compiling them on the host machine. The host therefore needs a copy of the Hadoop jars to compile your code against. Copy the /hadoop-0.18.0 directory from the CD into a location on your local drive, and remember where this is. You do not need to configure this copy of Hadoop in any way.
Running Eclipse
Navigate into the Eclipse directory and run eclipse.exe to start the IDE. Eclipse stores all of your source projects and their related settings in a directory called a workspace.
Upon starting Eclipse, it will prompt you for a directory to act as the workspace. Choose a directory name that makes sense to you and click OK.
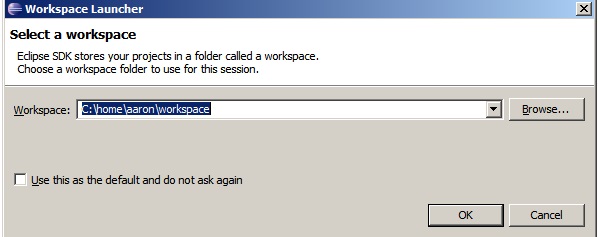
Figure 3.3: When you first start Eclipse, you must choose a directory to act as your workspace.
Configuring the MapReduce Plugin
In this section, we will walk through the process of configuring Eclipse to switch to the MapReduce perspective and connect to the Hadoop virtual machine.
Step 1: If you have not already done so, start Eclipse and choose a workspace directory. If you are presented with a "welcome" screen, click the button that says "Go to the Workbench." The Workbench is the main view of Eclipse, where you can write source code, launch programs, and manage your projects.
Step 2: Start the virtual machine. Double-click on the image.vmx file in the virtual machine's installation directory to launch the virtual machine. It should begin the Linux boot process.
Step 3: Switch to the MapReduce perspective. In the upper-right corner of the workbench, click the "Open Perspective" button, as shown in Figure 3.4:
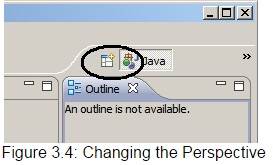
Figure 3.4: Changing the Perspective
Select "Other," followed by "Map/Reduce" in the window that opens up. At first, nothing may appear to change. In the menu, choose Window * Show View * Other. Under "MapReduce Tools," select "Map/Reduce Locations." This should make a new panel visible at the bottom of the screen, next to Problems and Tasks.
Step 4: Add the Server. In the Map/Reduce Locations panel, click on the elephant logo in the upper-right corner to add a new server to Eclipse.

Figure 3.5: Adding a New Server
You will now be asked to fill in a number of parameters identifying the server. To connect to the VMware image, the values are:
Location name: (Any descriptive name you want; e.g., "VMware server")
Map/Reduce Master Host: (The IP address printed at startup)
Map/Reduce Master Port: 9001
DFS Master Port: 9000
User name: hadoop-user
Next, click on the "Advanced" tab. There are two settings here which must be changed.
Scroll down to hadoop.job.ugi. It contains your current Windows login credentials. Highlight the first comma-separated value in this list (your username) and replace it with hadoop-user.
Next, scroll further down to mapred.system.dir. Erase the current value and set it to /hadoop/mapred/system.
When you are done, click "Finish." Your server will now appear in the Map/Reduce Locations panel. If you look in the Project Explorer (upper-left corner of Eclipse), you will see that the MapReduce plugin has added the ability to browse HDFS. Click the [+] buttons to expand the directory tree to see any files already there. If you inserted files into HDFS yourself, they will be visible in this tree.
Figure 3.6: Files Visible in the HDFS Viewer
Now that your system is configured, the following sections will introduce you to the basic features and verify that they work correctly.
Interacting With HDFS
The VMware image will expose a single-node HDFS instance for your use in MapReduce applications. If you are logged in to the virtual machine, you can interact with HDFS using the command-line tools described in Module 2. You can also manipulate HDFS through the MapReduce plugin.
Using the Command Line
An interesting MapReduce task will require some external data to process: log files, web crawl results, etc. Before you can begin processing with MapReduce, data must be loaded into its distributed file system. In Module 2, you learned how to copy files from the local file system into HDFS. But this will copy files from the local file system of the VM into HDFS - not from the file system of your host computer.
To load data into HDFS in the virtual machine, you have several options available to you:
scp the files to the virtual machine, and then use the bin/hadoop fs -put ... syntax to copy the files from the VM's local file system into HDFS, pipe the data from the local machine into a put command reading from stdin,
or install the Hadoop tools on the host system and configure it to communicate directly with the guest instance. We will review each of these in turn.
To load data into HDFS using the command line within the virtual machine, you can first send the data to the VM's local disk, then insert it into HDFS. You can send files to the VM using an scp client, such as the pscp component of putty, or WinSCP.
scp will allow you to copy files from one machine to another over the network. The scp command takes two arguments, both of the form [[username@]hostname]:filename. The scp command itself is of the form scp source dest, where source and dest are formatted as described above. By default, it will assume that paths are on the local host, and should be accessed using the current username. You can override the username and hostname to perform remote copies.
So supposing you have a file named foo.txt, and you would like to copy this into the virtual machine which has IP address 192.168.190.128, you can perform this operation with the command:
$ scp foo.txt hadoop-user@192.168.190.128:foo.txt
If you are using the pscp program, substitute pscp instead of scp above. A copy of the "regular" scp can be run under cygwin by downloading the OpenSSH package. pscp is a utility by the makers of putty and does not require cygwin.
Note that since we did not specify a destination directory, it will go in /home/hadoop-user by default. To change the target directory, specify it after the hostname (e.g., hadoop-user@192.168.128.190:/some/dest/path/foo.txt.) You can also omit the destination filename, if you want it to be identical to the source filename. However, if you omit both the target directory and filename, you must not forget the colon (":") that follows the target hostname. Otherwise it will make a local copy of the file, with the name 192.168.190.128. An equivalent correct command to copy foo.txt to /home/hadoop-user on the remote machine is:
$ scp foo.txt hadoop-user@192.168.190.128:
Windows users may be more inclined to use a GUI tool to perform scp commands. The free WinSCP program provides an FTP-like GUI interface over scp.
After you have copied files into the local disk of the virtual machine, you can log in to the virtual machine as hadoop-user and insert the files into HDFS using the standard Hadoop commands. For example,
hadoop-user@vm-instance:hadoop$ bin/hadoop dfs -put ~/foo.txt \
/user/hadoop-user/input/foo.txt
A second option available to upload individual files to HDFS from the host machine is to echo the file contents into a put command running via ssh. e.g., assuming you have the cat program (which comes with Linux or cygwin) to echo the contents of a file to the terminal output, you can connect its output to the input of a put command running over ssh like so:
you@host-machine$ cat somefile | ssh hadoop-user@vm-ip-addr \
"hadoop/bin/hadoop fs -put - destinationfile
The - as an argument to the put command instructs the system to use stdin as its input file. This will copy somefile on the host machine to destinationfile in HDFS on the virtual machine.
Finally, if you are running either Linux or cygwin, you can copy the /hadoop-0.18.0 directory on the CD to your local instance. You can then configure hadoop-site.xml to use the virtual machine as the default distributed file system (by setting the fs.default.name parameter). If you then run bin/hadoop fs -put ... commands on this machine (or any other hadoop commands, for that matter), they will interact with HDFS as served by the virtual machine. See the Hadoop quickstart for instructions on configuring a Hadoop installation, or Module 7 for a more thorough treatment.
Using the MapReduce Plugin For Eclipse
An easier way to manipulate files in HDFS may be through the Eclipse plugin. In the DFS location viewer, right-click on any folder to see a list of actions available. You can create new subdirectories, upload individual files or whole subdirectories, or download files and directories to the local disk.
If /user/hadoop-user does not exist, create that first. Right-click on the top-level directory and select "Create New Directory". Type "user" and click OK. You will then need to refresh the current directory view by right-clicking and selecting "Refresh" from the pop-up menu. Repeat this process to create the "hadoop-user" directory under "user."
Now, prepare some local files to upload. Somewhere on your hard drive, create a directory named "input" and find some text files to copy there. In the DFS explorer, right-click the "hadoop-user" directory and click "Upload Directory to DFS." Select your new input folder and click OK. Eclipse will copy the files directly into HDFS, bypassing the local drive of the virtual machine. You may have to refresh the directory view to see your changes. You should now have a directory hierarchy containing the /user/hadoop-user/input directory, which has at least one text file in it.
Running a Sample Program
While we have not yet formally introduced the programming style for Hadoop, we can still test whether a MapReduce program will run on our Hadoop virtual machine. This section walks you through the steps required to verify this.
The program that we will run is a word count utility. The program will read the files you uploaded to HDFS in the previous section, and determine how many times each word in the files appears.
If you have not already done so, start the virtual machine and Eclipse, and switch Eclipse to use the MapReduce perspective. Instructions are in the previous section.
Creating the Project
In the menu, click File * New * Project. Select "Map/Reduce Project" from the list and click Next.
You now need to select a project name. Any name will do, e.g., "WordCount". You will also need to specify the Hadoop Library Installation Path. This is the path where you made a copy of the /hadoop-0.18.0 folder on the CD. Since we have not yet configured this part of Eclipse, do so now by clicking "Configure Hadoop install directory..." and choosing the path where you copied Hadoop to. There should be a file named hadoop-0.18.0-core.jar in this directory. Creating a MapReduce Project instead of a generic Java project automatically adds the prerequisite jar files to the build path. If you create a regular Java project, you must add the Hadoop jar (and its dependencies) to the build path manually.
When you have completed these steps, click Finish.
Creating the Source Files
Our program needs three classes to run: a Mapper, a Reducer, and a Driver. The Driver tells Hadoop how to run the MapReduce process. The Mapper and Reducer operate on your data.
Right-click on the "src" folder under your project and select New * Other.... In the "Map/Reduce" folder on the resulting window, we can create Mapper, Reducer, and Driver classes based on pre-written stub code. Create classes named WordCountMapper, WordCountReducer, and WordCount that use the Mapper, Reducer, and Driver stubs respectively.
The code for each of these classes is shown here. You can copy this code into your files.
WordCountMapper.java:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class WordCountMapper extends MapReduceBase
implements Mapper {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(WritableComparable key, Writable value,
OutputCollector output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line.toLowerCase());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
WordCountReducer.java:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class WordCountReducer extends MapReduceBase
implements Reducer {
public void reduce(Text key, Iterator values,
OutputCollector output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
IntWritable value = (IntWritable) values.next();
sum += value.get(); // process value
}
output.collect(key, new IntWritable(sum));
}
}
WordCount.java:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
public class WordCount {
public static void main(String[] args) {
JobClient client = new JobClient();
JobConf conf = new JobConf(WordCount.class);
// specify output types
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
// specify input and output dirs
FileInputPath.addInputPath(conf, new Path("input"));
FileOutputPath.addOutputPath(conf, new Path("output"));
// specify a mapper
conf.setMapperClass(WordCountMapper.class);
// specify a reducer
conf.setReducerClass(WordCountReducer.class);
conf.setCombinerClass(WordCountReducer.class);
client.setConf(conf);
try {
JobClient.runJob(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
For now, don't worry about how these functions work; we will introduce how to write MapReduce programs in Module 4. We currently just want to establish that we can run jobs on the virtual machine.
Launching the Job
After the code has been entered, it is time to run it. You have already created a directory named input below /user/hadoop-user in HDFS. This will serve as the input files to this process. In the Project Explorer, right-click on the driver class, WordCount.java. In the pop-up menu, select Run As * Run On Hadoop. A window will appear asking you to select a Hadoop location to run on. Select the VMware server that you configured earlier, and click Finish.
If all goes well, the progress output from Hadoop should appear in the console in Eclipse; it should look something like:
08/06/25 12:14:22 INFO mapred.FileInputFormat: Total input paths to process : 3
08/06/25 12:14:23 INFO mapred.JobClient: Running job: job_200806250515_0002
08/06/25 12:14:24 INFO mapred.JobClient: map 0% reduce 0%
08/06/25 12:14:31 INFO mapred.JobClient: map 50% reduce 0%
08/06/25 12:14:33 INFO mapred.JobClient: map 100% reduce 0%
08/06/25 12:14:42 INFO mapred.JobClient: map 100% reduce 100%
08/06/25 12:14:43 INFO mapred.JobClient: Job complete: job_200806250515_0002
08/06/25 12:14:43 INFO mapred.JobClient: Counters: 12
08/06/25 12:14:43 INFO mapred.JobClient: Job Counters
08/06/25 12:14:43 INFO mapred.JobClient: Launched map tasks=4
08/06/25 12:14:43 INFO mapred.JobClient: Launched reduce tasks=1
08/06/25 12:14:43 INFO mapred.JobClient: Data-local map tasks=4
08/06/25 12:14:43 INFO mapred.JobClient: Map-Reduce Framework
08/06/25 12:14:43 INFO mapred.JobClient: Map input records=211
08/06/25 12:14:43 INFO mapred.JobClient: Map output records=1609
08/06/25 12:14:43 INFO mapred.JobClient: Map input bytes=11627
08/06/25 12:14:43 INFO mapred.JobClient: Map output bytes=16918
08/06/25 12:14:43 INFO mapred.JobClient: Combine input records=1609
08/06/25 12:14:43 INFO mapred.JobClient: Combine output records=682
08/06/25 12:14:43 INFO mapred.JobClient: Reduce input groups=568
08/06/25 12:14:43 INFO mapred.JobClient: Reduce input records=682
08/06/25 12:14:43 INFO mapred.JobClient: Reduce output records=568
In the DFS Explorer, right-click on /user/hadoop-user and select "Refresh." You should now see an "output" directory containing a file named part-00000. This is the output of the job. Double-clicking this file will allow you to view it in Eclipse; you can see each word and its frequency in the documents. (You may receive a warning that this file is larger than 1 MB, first. Click OK.)
If you want to run the job again, you will need to delete the output directory first. Right-click the output directory in the DFS Explorer and click "Delete."
Congratulations! You should now have a functioning Hadoop development environment. In the next module, we will learn how to use it to perform powerful programming tasks.
Developing for Hadoop requires a Java programming environment. You can download a Java Development Kit (JDK) for a wide variety of operating systems from http://java.sun.com. Hadoop requires the Java Standard Edition (Java SE), version 6, which is the most current version at the time of this writing.
A Virtual Machine Hadoop Environment
This section explains how to configure a virtual machine to run Hadoop within your host computer. After installing the virtual machine software and the virtual machine image, you will learn how to log in and run jobs within the Hadoop environment.
Users of Linux, Mac OSX, or other Unix-like environments are able to install Hadoop and run it on one (or more) machines with no additional software beyond Java. If you are interested in doing this, there are instructions available on the Hadoop web site in the quickstart document.
Running Hadoop on top of Windows requires installing cygwin, a Linux-like environment that runs within Windows. Hadoop works reasonably well on cygwin, but it is officially for "development purposes only." Hadoop on cygwin may be unstable, and installing cygwin itself can be cumbersome.
To aid developers in getting started easily with Hadoop, we have provided a virtual machine image containing a preconfigured Hadoop installation. The virtual machine image will run inside of a "sandbox" environment in which we can run another operating system. The OS inside the sandbox does not know that there is another operating environment outside of it; it acts as though it is on its own computer. This sandbox environment is referred to as the "guest machine" running a "guest operating system." The actual physical machine running the VM software is referred to as the "host machine" and it runs the "host operating system." The virtual machine provides other host-machine applications with the appearance that another physical computer is available on the same network. Applications running on the host machine see the VM as a separate machine with its own IP address, and can interact with the programs inside the VM in this fashion.
Figure 3.1: A virtual machine encapsulates one operating system within another. Applications in the VM believe they run on a separate physical host from other applications in the external operating system. Here we demonstrate a Windows host machine and a Linux guest (virtual) machine.
Application developers do not need to use the virtual machine to run Hadoop. Developers on Linux typically use Hadoop in their native development environment, and Windows users often install cygwin for Hadoop development. The virtual machine provided with this tutorial allows users a convenient alternative development platform with a minimum of configuration required. Another advantage of the virtual machine is its easy reset functionality. If your experiments break the Hadoop configuration or render the operating system unusable, you can always simply copy the virtual machine image from the CD back to where you installed it on your computer, and start from a known-good state.
Our virtual machine will run Linux, and comes preconfigured to run Hadoop in pseudo-distributed mode on this system. (It is configured like a fully distributed system, but is actually running on a single machine instance.) We can write Hadoop programs using editors and other applications of the host platform, and run them on our "cluster" consisting of just the virtual machine. We will connect our host environment to the virtual machine through the network.
It should be noted that the virtual machine will also run inside of another instance of Linux. Linux users can install the virtual machine software and run the Hadoop VM as well; the same separation between host processes and guest processes applies here.
Installing VMware Player
The virtual machine is designed to run inside of the VMware Player. A copy of the VMware player installer (version 2.5) for both 32-bit Windows and Linux is included here (linux-rpm, linux-bundle, windows-exe). A Getting Started guide for VMware player provides instructions for installing the VMware player. Review the license information for VMware player before using it..
If you are running on a different operating system, or would prefer to download a more recent version of the player, an alternate installation strategy is to navigate to http://info.vmware.com/content/GLP_VMwarePlayer. You will need to register for a "virtualization starter kit." You will receive an email with a link to "Download VMware Player." Click the link, then click the "download now" button at the top of the screen under "most recent version" and follow the instructions. VMware Player is available for Windows or Linux. The latter is available in both 32- and 64-bit versions.
VMware Player itself is approximately a 170 MB download. When the download has completed, run the installer program to set up VMware Player, and follow the prompts as directed. Installation in Windows is performed by a typical Windows installation process.
Setting up the Virtual Environment
Next, copy the Hadoop Virtual Machine into a location on your hard drive. It is a zipped vmware folder (hadoop-vm-appliance-0-18-0) which includes a few files; a .vmdk file that is a snapshot of the virtual machine's hard drive, and a .vmx file which contains the configuration information to start the virtual machine. After unzipping the vmware folder zip file, to start the virtual machine, double-click on the hadoop-appliance-0.18.0.vmx file in Windows Explorer.
Figure 3.2: When you start the virtual machine for the first time, tell VMware Player that you have copied the VM image.
When you start the virtual machine for the first time, VMware Player will recognize that the virtual machine image is not in the same location it used to be. You should inform VMware Player that you copied this virtual machine image. VMware Player will then generate new session identifiers for this instance of the virtual machine. If you later move the VM image to a different location on your own hard drive, you should tell VMware Player that you have moved the image.
If you ever corrupt the VM image (e.g., by inadvertently deleting or overwriting important files), you can always restore a pristine copy of the virtual machine by copying a fresh VM image off of this tutorial CD. (So don't be shy about exploring! You can always reset it to a functioning state.)
After you select this option and click OK, the virtual machine should begin booting normally. You will see it perform the standard boot procedure for a Linux system. It will bind itself to an IP address on an unused network segment, and then display a prompt allowing a user to log in.
Virtual Machine User Accounts
The virtual machine comes preconfigured with two user accounts: "root" and "hadoop-user". The hadoop-user account has sudo permissions to perform system management functions, such as shutting down the virtual machine. The vast majority of your interaction with the virtual machine will be as hadoop-user.
To log in as hadoop-user, first click inside the virtual machine's display. The virtual machine will take control of your keyboard and mouse. To escape back into Windows at any time, press CTRL+ALT at the same time. The hadoop-user user's password is hadoop. To log in as root, the password is root.
Running a Hadoop Job
Now that the VM is started, or you have installed Hadoop on your own system in pseudo-distributed mode, let us make sure that Hadoop is properly configured.
If you are using the VM, log in as hadoop-user, as directed above. You will start in your home directory: /home/hadoop-user. Typing ls, you will see a directory named hadoop/, as well as a set of scripts to manage the server. The virtual machine's hostname is hadoop-desk.
First, we must start the Hadoop system. Type the following command:
hadoop-user@hadoop-desk:~$ ./start-hadoop
If you installed Hadoop on your host system, use the following commands to launch hadoop (assuming you installed to ~/hadoop):
you@your-machine:~$ cd hadoop
you@your-machine:~/hadoop$ bin/start-all.sh
You will see a set of status messages appear as the services boot. If prompted whether it is okay to connect to the current host, type "yes". Try running an example program to ensure that Hadoop is correctly configured:
hadoop-user@hadoop-desk:~$ cd hadoop
hadoop-user@hadoop-desk:~/hadoop$ bin/hadoop jar hadoop-0.18.0-examples.jar pi 10 1000000
This should provide output that looks something like this:
Wrote input for Map #1
Wrote input for Map #2
Wrote input for Map #3
...
Wrote input for Map #10
Starting Job
INFO mapred.FileInputFormat: Total input paths to process: 10
INFO mapred.JobClient: Running job: job_200806230804_0001
INFO mapred.JobClient: map 0% reduce 0%
INFO mapred.JobClient: map 10% reduce 0%
...
INFO mapred.JobClient: map 100% reduce 100%
INFO mapred.JobClient: Job complete: job_200806230804_0001
...
Job Finished in 25.841 second
Estimated value of PI is 3.141688
This task runs a simulation to estimate the value of pi based on sampling. The test first wrote out a number of points to a list of files, one per map task. It then calculated an estimate of pi based on these points, in the MapReduce task itself. How MapReduce works and how to write such a program are discussed in the next module. The Hadoop client program you used to launch the pi test launched the job, displayed some progress update information as to how the job is proceeding, and then displayed some final performance counters and the job-specific output: an estimate for the value of pi.
Accessing the VM via ssh
Rather than directly use the terminal of the virtual machine, you can also log in "remotely" over ssh from the host environment. Using an ssh client like putty (in Windows), log in with username "hadoop-user" (password hadoop) to the IP address displayed in the virtual machine terminal when it starts up. You can now interact with this virtual machine as if it were another Linux machine on the network.
This can only be done from the host machine. The VMware image is, by default, configured to use host-only networking; only the host machine can talk to the virtual machine over its network interface. The virtual machine does not appear on the actual external network. This is done for security purposes.
If you need to find the virtual machine's IP address later, the ifconfig command will display this under the "inet addr" field.
Important security note: In the VMware settings, you can reconfigure the virtual machine for networked access rather than host-only networking. If you enable network access, you can access the virtual machine from anywhere else on the network via its IP address. In this case, you should change the passwords associated with the accounts on the virtual machine to prevent unauthorized users from logging in with the default password.
Shutting Down the VM
When you are done with the virtual machine, you can turn it off by logging in as hadoop-user and typing sudo poweroff. The virtual machine will shut itself down in an orderly fashion and the window it runs in will disappear.
Getting Started With Eclipse
A powerful development environment for Java-based programming is Eclipse. Eclipse is a free, open-source IDE. It supports multiple languages through a plugin interface, with special attention paid to Java. Tools designed for working with Hadoop can be integrated into Eclipse, making it an attractive platform for Hadoop development. In this section we will review how to obtain, configure, and use Eclipse.
Downloading and Installing
Note: The most current release of Eclipse is called Ganymede. Our testing shows that Ganymede is currently incompatible with the Hadoop MapReduce plugin. The most recent version which worked properly with the Hadoop plugin is version 3.3.1, "Europa." To download Europa, do not visit the main Eclipse website; it can be found in the archive site http://archive.eclipse.org/eclipse/downloads/ as the "Archived Release (3.3.1)."
The Eclipse website has several versions available for download; choose either "Eclipse Classic" or "Eclipse IDE for Java Developers."
Because it is written in Java, Eclipse is very cross-platform. Eclipse is available for Windows, Linux, and Mac OSX.
Installing Eclipse is very straightforward. Eclipse is packaged as a .zip file. Windows itself can natively unzip the compressed file into a directory. If you encounter errors using the Windows decompression tool (see [1]), try using a third-party unzip utility such as 7-zip or WinRAR.
After you have decompressed Eclipse into a directory, you can run it straight from that directory with no modifications or other "installation" procedure. You may want to move it into C:\Program Files\Eclipse to keep consistent with your other applications, but it can reside in the Desktop or elsewhere as well.
Installing the Hadoop MapReduce Plugin
Hadoop comes with a plugin for Eclipse that makes developing MapReduce programs easier. In the hadoop-0.18.0/contrib/eclipse-plugin directory on this CD, you will find a file named hadoop-0.18.0-eclipse-plugin.jar. Copy this into the plugins/ subdirectory of wherever you unzipped Eclipse.
Making a Copy of Hadoop
While we will be running MapReduce programs on the virtual machine, we will be compiling them on the host machine. The host therefore needs a copy of the Hadoop jars to compile your code against. Copy the /hadoop-0.18.0 directory from the CD into a location on your local drive, and remember where this is. You do not need to configure this copy of Hadoop in any way.
Running Eclipse
Navigate into the Eclipse directory and run eclipse.exe to start the IDE. Eclipse stores all of your source projects and their related settings in a directory called a workspace.
Upon starting Eclipse, it will prompt you for a directory to act as the workspace. Choose a directory name that makes sense to you and click OK.
Figure 3.3: When you first start Eclipse, you must choose a directory to act as your workspace.
Configuring the MapReduce Plugin
In this section, we will walk through the process of configuring Eclipse to switch to the MapReduce perspective and connect to the Hadoop virtual machine.
Step 1: If you have not already done so, start Eclipse and choose a workspace directory. If you are presented with a "welcome" screen, click the button that says "Go to the Workbench." The Workbench is the main view of Eclipse, where you can write source code, launch programs, and manage your projects.
Step 2: Start the virtual machine. Double-click on the image.vmx file in the virtual machine's installation directory to launch the virtual machine. It should begin the Linux boot process.
Step 3: Switch to the MapReduce perspective. In the upper-right corner of the workbench, click the "Open Perspective" button, as shown in Figure 3.4:
Figure 3.4: Changing the Perspective
Select "Other," followed by "Map/Reduce" in the window that opens up. At first, nothing may appear to change. In the menu, choose Window * Show View * Other. Under "MapReduce Tools," select "Map/Reduce Locations." This should make a new panel visible at the bottom of the screen, next to Problems and Tasks.
Step 4: Add the Server. In the Map/Reduce Locations panel, click on the elephant logo in the upper-right corner to add a new server to Eclipse.
Figure 3.5: Adding a New Server
You will now be asked to fill in a number of parameters identifying the server. To connect to the VMware image, the values are:
Location name: (Any descriptive name you want; e.g., "VMware server")
Map/Reduce Master Host: (The IP address printed at startup)
Map/Reduce Master Port: 9001
DFS Master Port: 9000
User name: hadoop-user
Next, click on the "Advanced" tab. There are two settings here which must be changed.
Scroll down to hadoop.job.ugi. It contains your current Windows login credentials. Highlight the first comma-separated value in this list (your username) and replace it with hadoop-user.
Next, scroll further down to mapred.system.dir. Erase the current value and set it to /hadoop/mapred/system.
When you are done, click "Finish." Your server will now appear in the Map/Reduce Locations panel. If you look in the Project Explorer (upper-left corner of Eclipse), you will see that the MapReduce plugin has added the ability to browse HDFS. Click the [+] buttons to expand the directory tree to see any files already there. If you inserted files into HDFS yourself, they will be visible in this tree.
Figure 3.6: Files Visible in the HDFS Viewer
Now that your system is configured, the following sections will introduce you to the basic features and verify that they work correctly.
Interacting With HDFS
The VMware image will expose a single-node HDFS instance for your use in MapReduce applications. If you are logged in to the virtual machine, you can interact with HDFS using the command-line tools described in Module 2. You can also manipulate HDFS through the MapReduce plugin.
Using the Command Line
An interesting MapReduce task will require some external data to process: log files, web crawl results, etc. Before you can begin processing with MapReduce, data must be loaded into its distributed file system. In Module 2, you learned how to copy files from the local file system into HDFS. But this will copy files from the local file system of the VM into HDFS - not from the file system of your host computer.
To load data into HDFS in the virtual machine, you have several options available to you:
scp the files to the virtual machine, and then use the bin/hadoop fs -put ... syntax to copy the files from the VM's local file system into HDFS, pipe the data from the local machine into a put command reading from stdin,
or install the Hadoop tools on the host system and configure it to communicate directly with the guest instance. We will review each of these in turn.
To load data into HDFS using the command line within the virtual machine, you can first send the data to the VM's local disk, then insert it into HDFS. You can send files to the VM using an scp client, such as the pscp component of putty, or WinSCP.
scp will allow you to copy files from one machine to another over the network. The scp command takes two arguments, both of the form [[username@]hostname]:filename. The scp command itself is of the form scp source dest, where source and dest are formatted as described above. By default, it will assume that paths are on the local host, and should be accessed using the current username. You can override the username and hostname to perform remote copies.
So supposing you have a file named foo.txt, and you would like to copy this into the virtual machine which has IP address 192.168.190.128, you can perform this operation with the command:
$ scp foo.txt hadoop-user@192.168.190.128:foo.txt
If you are using the pscp program, substitute pscp instead of scp above. A copy of the "regular" scp can be run under cygwin by downloading the OpenSSH package. pscp is a utility by the makers of putty and does not require cygwin.
Note that since we did not specify a destination directory, it will go in /home/hadoop-user by default. To change the target directory, specify it after the hostname (e.g., hadoop-user@192.168.128.190:/some/dest/path/foo.txt.) You can also omit the destination filename, if you want it to be identical to the source filename. However, if you omit both the target directory and filename, you must not forget the colon (":") that follows the target hostname. Otherwise it will make a local copy of the file, with the name 192.168.190.128. An equivalent correct command to copy foo.txt to /home/hadoop-user on the remote machine is:
$ scp foo.txt hadoop-user@192.168.190.128:
Windows users may be more inclined to use a GUI tool to perform scp commands. The free WinSCP program provides an FTP-like GUI interface over scp.
After you have copied files into the local disk of the virtual machine, you can log in to the virtual machine as hadoop-user and insert the files into HDFS using the standard Hadoop commands. For example,
hadoop-user@vm-instance:hadoop$ bin/hadoop dfs -put ~/foo.txt \
/user/hadoop-user/input/foo.txt
A second option available to upload individual files to HDFS from the host machine is to echo the file contents into a put command running via ssh. e.g., assuming you have the cat program (which comes with Linux or cygwin) to echo the contents of a file to the terminal output, you can connect its output to the input of a put command running over ssh like so:
you@host-machine$ cat somefile | ssh hadoop-user@vm-ip-addr \
"hadoop/bin/hadoop fs -put - destinationfile
The - as an argument to the put command instructs the system to use stdin as its input file. This will copy somefile on the host machine to destinationfile in HDFS on the virtual machine.
Finally, if you are running either Linux or cygwin, you can copy the /hadoop-0.18.0 directory on the CD to your local instance. You can then configure hadoop-site.xml to use the virtual machine as the default distributed file system (by setting the fs.default.name parameter). If you then run bin/hadoop fs -put ... commands on this machine (or any other hadoop commands, for that matter), they will interact with HDFS as served by the virtual machine. See the Hadoop quickstart for instructions on configuring a Hadoop installation, or Module 7 for a more thorough treatment.
Using the MapReduce Plugin For Eclipse
An easier way to manipulate files in HDFS may be through the Eclipse plugin. In the DFS location viewer, right-click on any folder to see a list of actions available. You can create new subdirectories, upload individual files or whole subdirectories, or download files and directories to the local disk.
If /user/hadoop-user does not exist, create that first. Right-click on the top-level directory and select "Create New Directory". Type "user" and click OK. You will then need to refresh the current directory view by right-clicking and selecting "Refresh" from the pop-up menu. Repeat this process to create the "hadoop-user" directory under "user."
Now, prepare some local files to upload. Somewhere on your hard drive, create a directory named "input" and find some text files to copy there. In the DFS explorer, right-click the "hadoop-user" directory and click "Upload Directory to DFS." Select your new input folder and click OK. Eclipse will copy the files directly into HDFS, bypassing the local drive of the virtual machine. You may have to refresh the directory view to see your changes. You should now have a directory hierarchy containing the /user/hadoop-user/input directory, which has at least one text file in it.
Running a Sample Program
While we have not yet formally introduced the programming style for Hadoop, we can still test whether a MapReduce program will run on our Hadoop virtual machine. This section walks you through the steps required to verify this.
The program that we will run is a word count utility. The program will read the files you uploaded to HDFS in the previous section, and determine how many times each word in the files appears.
If you have not already done so, start the virtual machine and Eclipse, and switch Eclipse to use the MapReduce perspective. Instructions are in the previous section.
Creating the Project
In the menu, click File * New * Project. Select "Map/Reduce Project" from the list and click Next.
You now need to select a project name. Any name will do, e.g., "WordCount". You will also need to specify the Hadoop Library Installation Path. This is the path where you made a copy of the /hadoop-0.18.0 folder on the CD. Since we have not yet configured this part of Eclipse, do so now by clicking "Configure Hadoop install directory..." and choosing the path where you copied Hadoop to. There should be a file named hadoop-0.18.0-core.jar in this directory. Creating a MapReduce Project instead of a generic Java project automatically adds the prerequisite jar files to the build path. If you create a regular Java project, you must add the Hadoop jar (and its dependencies) to the build path manually.
When you have completed these steps, click Finish.
Creating the Source Files
Our program needs three classes to run: a Mapper, a Reducer, and a Driver. The Driver tells Hadoop how to run the MapReduce process. The Mapper and Reducer operate on your data.
Right-click on the "src" folder under your project and select New * Other.... In the "Map/Reduce" folder on the resulting window, we can create Mapper, Reducer, and Driver classes based on pre-written stub code. Create classes named WordCountMapper, WordCountReducer, and WordCount that use the Mapper, Reducer, and Driver stubs respectively.
The code for each of these classes is shown here. You can copy this code into your files.
WordCountMapper.java:
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class WordCountMapper extends MapReduceBase
implements Mapper
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(WritableComparable key, Writable value,
OutputCollector output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line.toLowerCase());
while(itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
WordCountReducer.java:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class WordCountReducer extends MapReduceBase
implements Reducer
public void reduce(Text key, Iterator values,
OutputCollector output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
IntWritable value = (IntWritable) values.next();
sum += value.get(); // process value
}
output.collect(key, new IntWritable(sum));
}
}
WordCount.java:
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
public class WordCount {
public static void main(String[] args) {
JobClient client = new JobClient();
JobConf conf = new JobConf(WordCount.class);
// specify output types
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
// specify input and output dirs
FileInputPath.addInputPath(conf, new Path("input"));
FileOutputPath.addOutputPath(conf, new Path("output"));
// specify a mapper
conf.setMapperClass(WordCountMapper.class);
// specify a reducer
conf.setReducerClass(WordCountReducer.class);
conf.setCombinerClass(WordCountReducer.class);
client.setConf(conf);
try {
JobClient.runJob(conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
For now, don't worry about how these functions work; we will introduce how to write MapReduce programs in Module 4. We currently just want to establish that we can run jobs on the virtual machine.
Launching the Job
After the code has been entered, it is time to run it. You have already created a directory named input below /user/hadoop-user in HDFS. This will serve as the input files to this process. In the Project Explorer, right-click on the driver class, WordCount.java. In the pop-up menu, select Run As * Run On Hadoop. A window will appear asking you to select a Hadoop location to run on. Select the VMware server that you configured earlier, and click Finish.
If all goes well, the progress output from Hadoop should appear in the console in Eclipse; it should look something like:
08/06/25 12:14:22 INFO mapred.FileInputFormat: Total input paths to process : 3
08/06/25 12:14:23 INFO mapred.JobClient: Running job: job_200806250515_0002
08/06/25 12:14:24 INFO mapred.JobClient: map 0% reduce 0%
08/06/25 12:14:31 INFO mapred.JobClient: map 50% reduce 0%
08/06/25 12:14:33 INFO mapred.JobClient: map 100% reduce 0%
08/06/25 12:14:42 INFO mapred.JobClient: map 100% reduce 100%
08/06/25 12:14:43 INFO mapred.JobClient: Job complete: job_200806250515_0002
08/06/25 12:14:43 INFO mapred.JobClient: Counters: 12
08/06/25 12:14:43 INFO mapred.JobClient: Job Counters
08/06/25 12:14:43 INFO mapred.JobClient: Launched map tasks=4
08/06/25 12:14:43 INFO mapred.JobClient: Launched reduce tasks=1
08/06/25 12:14:43 INFO mapred.JobClient: Data-local map tasks=4
08/06/25 12:14:43 INFO mapred.JobClient: Map-Reduce Framework
08/06/25 12:14:43 INFO mapred.JobClient: Map input records=211
08/06/25 12:14:43 INFO mapred.JobClient: Map output records=1609
08/06/25 12:14:43 INFO mapred.JobClient: Map input bytes=11627
08/06/25 12:14:43 INFO mapred.JobClient: Map output bytes=16918
08/06/25 12:14:43 INFO mapred.JobClient: Combine input records=1609
08/06/25 12:14:43 INFO mapred.JobClient: Combine output records=682
08/06/25 12:14:43 INFO mapred.JobClient: Reduce input groups=568
08/06/25 12:14:43 INFO mapred.JobClient: Reduce input records=682
08/06/25 12:14:43 INFO mapred.JobClient: Reduce output records=568
In the DFS Explorer, right-click on /user/hadoop-user and select "Refresh." You should now see an "output" directory containing a file named part-00000. This is the output of the job. Double-clicking this file will allow you to view it in Eclipse; you can see each word and its frequency in the documents. (You may receive a warning that this file is larger than 1 MB, first. Click OK.)
If you want to run the job again, you will need to delete the output directory first. Right-click the output directory in the DFS Explorer and click "Delete."
Congratulations! You should now have a functioning Hadoop development environment. In the next module, we will learn how to use it to perform powerful programming tasks.

Comments
No Comments have been Posted.
Post Comment
Please Login to Post a Comment.