
Users Online
· Guests Online: 1
· Members Online: 0
· Total Members: 185
· Newest Member: meenachowdary055
· Members Online: 0
· Total Members: 185
· Newest Member: meenachowdary055
Forum Threads
Newest Threads
No Threads created
Hottest Threads
No Threads created
Latest Articles
FAQ: Big Data Access Patterns
| FAQ (Frequently Asked Questions) >Big Data Access Patterns |
5_1. What are the typical access patterns for the Hadoop platform components to manipulate the data in the Hadoop storage layer?
Figure 5-1 shows how the platform layer of the big data tech stack communicates with the layers below.

The Hadoop platform management layer accesses data, runs queries, and manages the lower layers using scripting languages like Pig and Hive. Various data access patterns (platform layer to storage layer communication) suitable for different application scenarios are implemented based on the performance, scalability, and availability requirements.
Data access patterns describe solutions to commonly encountered problems when accessing data via the storage layer that can be chosen based on performance, scalability, and availability requirements. In the big data world, data that needs to be accessed can be classified as
• Incremental data
• Selective/filtered data
• Near real-time data with low latency
The raw big data does not provide intelligent information about the content and its operation. It is expected that the intended users of the data should be able to apply enough domain knowledge to get any meaningful insight from the raw data.
Data can be accessed from the big data resources in two primary forms:
• End-to-End User Driven API: These APIs permit users to write simple queries to produce clipped or aggregated output and throw on a visual display. Google Search is an example where the query results are abstracted from the user and the results are fetched using BASE
(basically available soft state consistent eventually) principles. Google gives users the opportunity to enter a query according to a set of Google-specified query rules, and it provides an output without exposing the internal mechanism of the query processing.
• Developer API: Individual developers can interact with the data and analytics service. These services might be available in SaaS (software as a service) formats. Amazon Web Services (AWS) is an example of an API. The API enables querying of the data or the summary of the analytics transactions.
Some of the patterns mentioned in this chapter can be used in conjunction with “data storage patterns.”
We will cover the following common data access patterns in this chapter, as shown in Figure 5-2:
• Stage Transform Pattern: This pattern uses the end-to-end user API approach and presents only the aggregated or clipped information in the NoSQL layer (Stage) after transforming the
raw data.
• Connector Pattern: This pattern uses the developer API approach of using APIs for accessing
data services provided by appliances.
• Lightweight Stateless Pattern: This pattern uses lightweight protocols like REST, HTTP, and others to do stateless queries of data from the big data storage layer.
• Service Locator Pattern: A scenario where the different sources of unstructured data are registered on a service catalog and dynamically invoked when required.
• Near Real-Time Pattern: This is an access pattern that works well in conjunction with (and is complementary to) the data ingestion pattern “just-in-time transformation.”
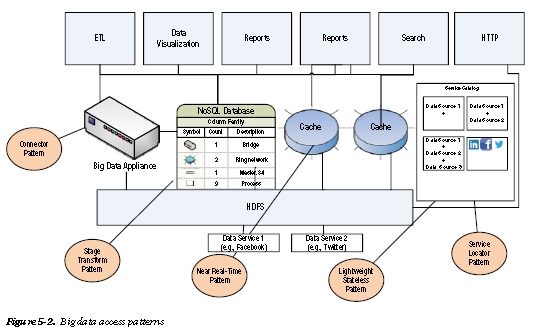
As you can see in Table 5-1, data should be abstracted in a layer above the Hadoop distributed file system (HDFS) to ensure low latency and business-specific data storage in a structured format.
Different patterns are suitable for different types of use cases:
• The Connector pattern is typically used to process bulk data in XML form. Usually, the connector APIs are provided by appliances or by the business intelligence (BI) systems that are big-data compliant.
• The Stage Transform pattern is useful for rapidly searching data that has been abstracted from
HDFS data storage into the NoSQL layer.
• If the data needs to be visualized in different perspectives, the Stage Transform and Connector
patterns can be used in conjunction to present the data in different views.
• Standard enterprise reports can be derived from the NoSQL databases instead of HBASE directly using the Stage Transform pattern.
• Data discovery from multiple data sources can be facilitated using RESTful services provided by those sources using the Lightweight Stateless pattern.
• An enterprise-wide dashboard collates data from applications across the organization using the catalog of services available from the API management software. This dashboard can
dynamically present the data using the Service Locator pattern.
Top
Figure 5-1 shows how the platform layer of the big data tech stack communicates with the layers below.
The Hadoop platform management layer accesses data, runs queries, and manages the lower layers using scripting languages like Pig and Hive. Various data access patterns (platform layer to storage layer communication) suitable for different application scenarios are implemented based on the performance, scalability, and availability requirements.
Data access patterns describe solutions to commonly encountered problems when accessing data via the storage layer that can be chosen based on performance, scalability, and availability requirements. In the big data world, data that needs to be accessed can be classified as
• Incremental data
• Selective/filtered data
• Near real-time data with low latency
The raw big data does not provide intelligent information about the content and its operation. It is expected that the intended users of the data should be able to apply enough domain knowledge to get any meaningful insight from the raw data.
Data can be accessed from the big data resources in two primary forms:
• End-to-End User Driven API: These APIs permit users to write simple queries to produce clipped or aggregated output and throw on a visual display. Google Search is an example where the query results are abstracted from the user and the results are fetched using BASE
(basically available soft state consistent eventually) principles. Google gives users the opportunity to enter a query according to a set of Google-specified query rules, and it provides an output without exposing the internal mechanism of the query processing.
• Developer API: Individual developers can interact with the data and analytics service. These services might be available in SaaS (software as a service) formats. Amazon Web Services (AWS) is an example of an API. The API enables querying of the data or the summary of the analytics transactions.
Some of the patterns mentioned in this chapter can be used in conjunction with “data storage patterns.”
We will cover the following common data access patterns in this chapter, as shown in Figure 5-2:
• Stage Transform Pattern: This pattern uses the end-to-end user API approach and presents only the aggregated or clipped information in the NoSQL layer (Stage) after transforming the
raw data.
• Connector Pattern: This pattern uses the developer API approach of using APIs for accessing
data services provided by appliances.
• Lightweight Stateless Pattern: This pattern uses lightweight protocols like REST, HTTP, and others to do stateless queries of data from the big data storage layer.
• Service Locator Pattern: A scenario where the different sources of unstructured data are registered on a service catalog and dynamically invoked when required.
• Near Real-Time Pattern: This is an access pattern that works well in conjunction with (and is complementary to) the data ingestion pattern “just-in-time transformation.”
As you can see in Table 5-1, data should be abstracted in a layer above the Hadoop distributed file system (HDFS) to ensure low latency and business-specific data storage in a structured format.
Different patterns are suitable for different types of use cases:
• The Connector pattern is typically used to process bulk data in XML form. Usually, the connector APIs are provided by appliances or by the business intelligence (BI) systems that are big-data compliant.
• The Stage Transform pattern is useful for rapidly searching data that has been abstracted from
HDFS data storage into the NoSQL layer.
• If the data needs to be visualized in different perspectives, the Stage Transform and Connector
patterns can be used in conjunction to present the data in different views.
• Standard enterprise reports can be derived from the NoSQL databases instead of HBASE directly using the Stage Transform pattern.
• Data discovery from multiple data sources can be facilitated using RESTful services provided by those sources using the Lightweight Stateless pattern.
• An enterprise-wide dashboard collates data from applications across the organization using the catalog of services available from the API management software. This dashboard can
dynamically present the data using the Service Locator pattern.
Top
5_10. Are there products from industry leaders in the traditional BI landscape that offer big data integration features?
Yes, vendors like Pentaho, Talend, Teradata, and others have product offerings that require less learning time for BI
developers to harness the power of big data.
Example: Pentaho’s big data analytics integrates with Hadoop, NoSQL, and other big data appliances. It’s a visually easy tool that can be used by business analysts.
Top
Yes, vendors like Pentaho, Talend, Teradata, and others have product offerings that require less learning time for BI
developers to harness the power of big data.
Example: Pentaho’s big data analytics integrates with Hadoop, NoSQL, and other big data appliances. It’s a visually easy tool that can be used by business analysts.
Top
5_2. HDFS does not provide the ease of data access that an RDBMS does. Also, there is too much data that is not relevant for all business cases. Is there a way to reduce a huge data scan?
Stage Transform Pattern
HDFS is good for two purposes:
• Data storage
• Data analytics
As mentioned earlier, NoSQL does not need to host all the data. HDFS can hold all the raw data and only business-specific data can be abstracted in a NoSQL database, with HBase being the most well-known. There are other NoSQL databases—like MongoDB, Riak, Vertica, neo4j, CouchDB, and Redis—that provide application-oriented
structures, thereby making it easier to access data in the required format.
For example, for implementing data discovery for a retail application that depends on social media data,
enterprise data, historical data and recommendation engine analysis, or abstracting data for a retail user or users, a NoSQL database makes the implementation of a recommendation engine much easier.
The stage transform pattern in Figure 5-3 can be merged with the NoSQL pattern, which was discussed in
Chapter 4 of. The NoSQL pattern can be used to extract user data and store it in a NoSQL database. This extracted
data, which will be used by the recommendation engine, significantly reduces the overall amount of data to be
scanned. The performance benefit recognized will invariably improve the customer experience.
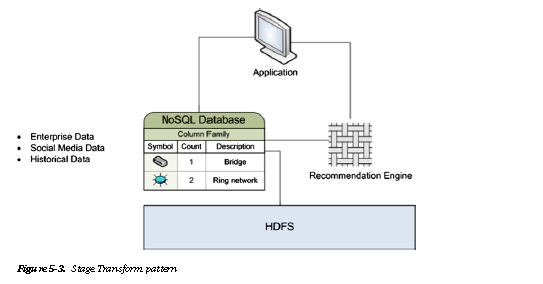
As you can see in Figure 5-3, the two “stages” of HDFS and NoSQL storage are used appropriately to reduce access times. Frequently accessed information is aggregated or contextualized in the NoSQL layer. The HDFS layer data can be scanned by long-running batch processes to derive inferences across long periods of time.
This virtualization of data from HDFS to a NoSQL database is implemented very widely and, at times, is integrated with a big data appliance to accelerate data access or transfer to other systems, as can be seen in the section that follows.
Top
Stage Transform Pattern
HDFS is good for two purposes:
• Data storage
• Data analytics
As mentioned earlier, NoSQL does not need to host all the data. HDFS can hold all the raw data and only business-specific data can be abstracted in a NoSQL database, with HBase being the most well-known. There are other NoSQL databases—like MongoDB, Riak, Vertica, neo4j, CouchDB, and Redis—that provide application-oriented
structures, thereby making it easier to access data in the required format.
For example, for implementing data discovery for a retail application that depends on social media data,
enterprise data, historical data and recommendation engine analysis, or abstracting data for a retail user or users, a NoSQL database makes the implementation of a recommendation engine much easier.
The stage transform pattern in Figure 5-3 can be merged with the NoSQL pattern, which was discussed in
Chapter 4 of. The NoSQL pattern can be used to extract user data and store it in a NoSQL database. This extracted
data, which will be used by the recommendation engine, significantly reduces the overall amount of data to be
scanned. The performance benefit recognized will invariably improve the customer experience.
As you can see in Figure 5-3, the two “stages” of HDFS and NoSQL storage are used appropriately to reduce access times. Frequently accessed information is aggregated or contextualized in the NoSQL layer. The HDFS layer data can be scanned by long-running batch processes to derive inferences across long periods of time.
This virtualization of data from HDFS to a NoSQL database is implemented very widely and, at times, is integrated with a big data appliance to accelerate data access or transfer to other systems, as can be seen in the section that follows.
Top
5_3. Just as there are XML accelerator appliances (like IBM DataPower), are there appliances that can accelerate data access/transfer and enable the use of the developer API approach?
Connector Pattern
EMC Greenplum, IBM PureData (Big Insights + Netezza), HP Vertica, and Oracle Exadata are some of the appliances that bring significant performance benefits. Though the data is stored in HDFS, some of these appliances abstract data in NoSQL databases. Some vendors have their own implementation of a file system (such as GreenPlum’s OneFS) to improve data access.
The advantage of such appliances is that they provide developer-usable APIs and SQL-like query languages to access data. This dramatically reduces the development time and does away with the need for identifying resources with niche skills.
Figure 5-4 shows the components of a typical big data appliance. It houses a complete big data ecosystem.
Appliances support virtualization. Thus, each node/disk is a virtual machine (VM) on top of a distributed database like HDFS. The appliance supports redundancy and replication using protocols like RAID. Some appliances also host a NoSQL database.
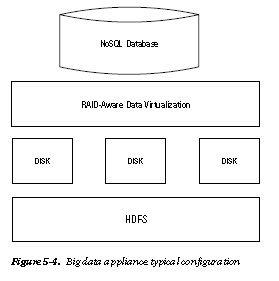
Examples are shown in Table 5-2.

Appliances might induce dependency on vendors. Some appliances, as seen in an earlier chapter, come
packaged as hardware, software, or a NoSQL database. For example, Vertica comes bundled with built-in “R” and “SAS” based engines and algorithms. Vertica can support any Hadoop distribution, such as Hortonworks, Cloudera,
and MapR.
Top
Connector Pattern
EMC Greenplum, IBM PureData (Big Insights + Netezza), HP Vertica, and Oracle Exadata are some of the appliances that bring significant performance benefits. Though the data is stored in HDFS, some of these appliances abstract data in NoSQL databases. Some vendors have their own implementation of a file system (such as GreenPlum’s OneFS) to improve data access.
The advantage of such appliances is that they provide developer-usable APIs and SQL-like query languages to access data. This dramatically reduces the development time and does away with the need for identifying resources with niche skills.
Figure 5-4 shows the components of a typical big data appliance. It houses a complete big data ecosystem.
Appliances support virtualization. Thus, each node/disk is a virtual machine (VM) on top of a distributed database like HDFS. The appliance supports redundancy and replication using protocols like RAID. Some appliances also host a NoSQL database.
Examples are shown in Table 5-2.
Appliances might induce dependency on vendors. Some appliances, as seen in an earlier chapter, come
packaged as hardware, software, or a NoSQL database. For example, Vertica comes bundled with built-in “R” and “SAS” based engines and algorithms. Vertica can support any Hadoop distribution, such as Hortonworks, Cloudera,
and MapR.
Top
5_4. Can we access data in near real-time from HDFS?
When we talk about “near real-time” access, we should keep in mind two things:
• Extremely low latency in capturing and processing the data. This means that as events happen, you act on the data; otherwise, that data becomes meaningless in the next minute.
• Analyzing the data in real time. This means you will need to have sophisticated analysis patterns to quickly look at the data, spot anomalies, relate the anomalies to meaningful business events, visualize the data, and provide alerts or guidance to the users. All this needs to happen at that very moment.
While the Hadoop ecosystem provides you the platform to access and process the data, fundamentally it still remains a batch-oriented architecture.
In this context, we encounter technologies used by Storm, in-memory appliances like Terracota, heavily indexed search patterns through Lucene and Solr.
Near Real-Time Access Pattern
Near real-time data access can be achieved when ingestion, storage, and data access are considered seamlessly as one single “pipe.” The right tools need to be used to ingest, and at the same time data should be filtered/sorted in multiple
storage destinations (as you saw in the multidestination pattern in an earlier chapter). In this scenario, one of the destinations could be a cache, which is then segregated based upon the business case. That cache can be in the form of a NoSQL database, or it can be in the form of memcache or any other implementation.
A typical example is searching application logs where data for the last hour is needed.
As you can see in Figure 5-5, the moment the data is ingested and filtered, it is transferred to a cache. This is where 90% of the noise is separated from 10% of the really relevant information. The relevant information is then stored in a rapidly accessible cache, which is usually in-memory. To quickly analyze this information before it becomes stale, search engines like Solr are used to complete this “Near Real-Time Access pattern” scenario.

Top
When we talk about “near real-time” access, we should keep in mind two things:
• Extremely low latency in capturing and processing the data. This means that as events happen, you act on the data; otherwise, that data becomes meaningless in the next minute.
• Analyzing the data in real time. This means you will need to have sophisticated analysis patterns to quickly look at the data, spot anomalies, relate the anomalies to meaningful business events, visualize the data, and provide alerts or guidance to the users. All this needs to happen at that very moment.
While the Hadoop ecosystem provides you the platform to access and process the data, fundamentally it still remains a batch-oriented architecture.
In this context, we encounter technologies used by Storm, in-memory appliances like Terracota, heavily indexed search patterns through Lucene and Solr.
Near Real-Time Access Pattern
Near real-time data access can be achieved when ingestion, storage, and data access are considered seamlessly as one single “pipe.” The right tools need to be used to ingest, and at the same time data should be filtered/sorted in multiple
storage destinations (as you saw in the multidestination pattern in an earlier chapter). In this scenario, one of the destinations could be a cache, which is then segregated based upon the business case. That cache can be in the form of a NoSQL database, or it can be in the form of memcache or any other implementation.
A typical example is searching application logs where data for the last hour is needed.
As you can see in Figure 5-5, the moment the data is ingested and filtered, it is transferred to a cache. This is where 90% of the noise is separated from 10% of the really relevant information. The relevant information is then stored in a rapidly accessible cache, which is usually in-memory. To quickly analyze this information before it becomes stale, search engines like Solr are used to complete this “Near Real-Time Access pattern” scenario.
Top
5_5. NAS (Network Access Storage) provides single file access. Can HDFS provide something similar using a lightweight protocol?
Lightweight Stateless Pattern
Files in HDFS can be accessed over RESTful HTTP calls using WebHDFS. Since it is a web service, the implementation
is not limited to Java or any particular language. For a cloud provider or an application wanting to expose its data to other systems, this is the simplest pattern.
The Lightweight Stateless pattern shown in Figure 5-6 is based on the HTTP REST protocol. HDFS systems expose RESTful web services to the consumers who want to analyze the big data. More and more of these services are hosted in a public cloud environment. This is also the beginning of the Integration Platform as a Service (iPaaS). This pattern reduces the cost of ownership for the enterprise by promising a pay-as-you-go model of big data analysis.

Top
Lightweight Stateless Pattern
Files in HDFS can be accessed over RESTful HTTP calls using WebHDFS. Since it is a web service, the implementation
is not limited to Java or any particular language. For a cloud provider or an application wanting to expose its data to other systems, this is the simplest pattern.
The Lightweight Stateless pattern shown in Figure 5-6 is based on the HTTP REST protocol. HDFS systems expose RESTful web services to the consumers who want to analyze the big data. More and more of these services are hosted in a public cloud environment. This is also the beginning of the Integration Platform as a Service (iPaaS). This pattern reduces the cost of ownership for the enterprise by promising a pay-as-you-go model of big data analysis.
Top
5_6. If there are multiple data storage sites (for example, Polyglot persistence) in the enterprise, how do I select a specific storage type?
Service Locator Pattern
For a storage landscape with different storage types, a data analyst needs the flexibility to manipulate , filter, select, and co-relate different data formats. Different data adapters should also be available at the click of a button through a common catalog of services. The Service Locator (SL) pattern resolves this problem where data storage access is
available in a SaaS model.
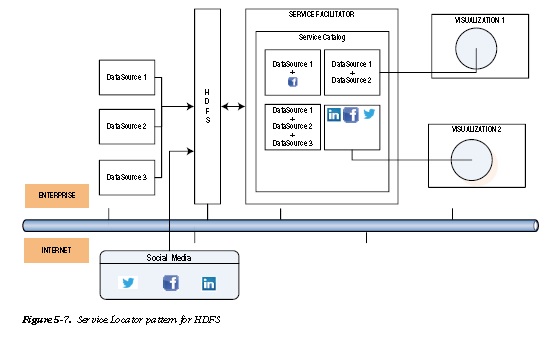
Figure 5-7 depicts the Service Locator pattern. Different data sources are exposed as services on a service catalog that is available to data analysts based on their authorization. The services could be within the enterprise or outside of
it. Different visualization tools can mix and match these services dynamically to show enterprise data alongside social media data.
Top
Service Locator Pattern
For a storage landscape with different storage types, a data analyst needs the flexibility to manipulate , filter, select, and co-relate different data formats. Different data adapters should also be available at the click of a button through a common catalog of services. The Service Locator (SL) pattern resolves this problem where data storage access is
available in a SaaS model.
Figure 5-7 depicts the Service Locator pattern. Different data sources are exposed as services on a service catalog that is available to data analysts based on their authorization. The services could be within the enterprise or outside of
it. Different visualization tools can mix and match these services dynamically to show enterprise data alongside social media data.
Top
5_7. Is MapReduce the only option for faster data processing and access?
Rapid Data Analysis
No. There are alternatives like Spark and Nokia’s DISCO.
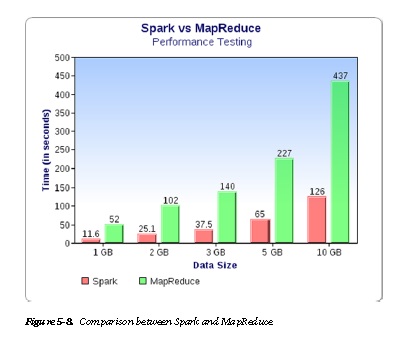
Spark is an open source, cluster-computing framework that can outperform Hadoop by 30 times. Spark can work with files stored in HDFS. MapReduce relies on disk storage while Spark relies on in-memory data across machines.
Figure 5-8 shows a comparison of the performance of a Spark vs. MapReduce.
Top
Rapid Data Analysis
No. There are alternatives like Spark and Nokia’s DISCO.
Spark is an open source, cluster-computing framework that can outperform Hadoop by 30 times. Spark can work with files stored in HDFS. MapReduce relies on disk storage while Spark relies on in-memory data across machines.
Figure 5-8 shows a comparison of the performance of a Spark vs. MapReduce.
Top
5_8. What security measures can be included to ensure data is not compromised during the interlayer communication?
Secure Data Access
Typical security measures that need to be looked into include the following:
Confidentiality: Data should be encr • ypted so that it is not sniffed during transport between
the layers.
• Authentication: Only authenticated users should be given access.
• Authorization: Users should have access to data according to their profiles and access rights only.
Other security measures are the traditional data center security measures like these:
• Network Intrusion Detection Systems (NIDS)
• Providing access only to requests coming from a particular IP
• Running nodes on ports other than default ports
• Host-based intrusion-prevention systems
Top
Secure Data Access
Typical security measures that need to be looked into include the following:
Confidentiality: Data should be encr • ypted so that it is not sniffed during transport between
the layers.
• Authentication: Only authenticated users should be given access.
• Authorization: Users should have access to data according to their profiles and access rights only.
Other security measures are the traditional data center security measures like these:
• Network Intrusion Detection Systems (NIDS)
• Providing access only to requests coming from a particular IP
• Running nodes on ports other than default ports
• Host-based intrusion-prevention systems
Top
5_9. Are there any large datasets available in the public domain that can be accessed by a layperson to analyze and use for big data experimentation?
Yes, there are many sites and services in the public domain for accessing data, such as:
Link
This collection presents the key sites that provide data, either through curated collections that offer access under the open data movement or through software/data-as-a-Service platforms.
Top
Yes, there are many sites and services in the public domain for accessing data, such as:
Link
This collection presents the key sites that provide data, either through curated collections that offer access under the open data movement or through software/data-as-a-Service platforms.
Top