What is Scikit-learn?
Scikit-learn is an open source Python library for machine learning. The library supports state-of-the-art algorithms such as KNN, XGBoost, random forest, SVM among others. It is built on top of Numpy. Scikit-learn is widely used in kaggle competition as well as prominent tech companies. Scikit-learn helps in preprocessing, dimensionality reduction(parameter selection), classification, regression, clustering, and model selection.
Scikit-learn has the best documentation of all opensource libraries. It provides you an interactive chart at http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html.
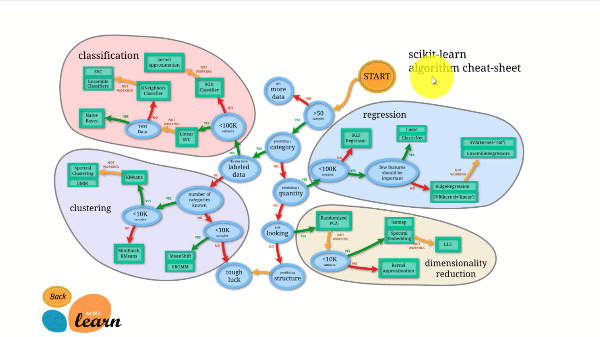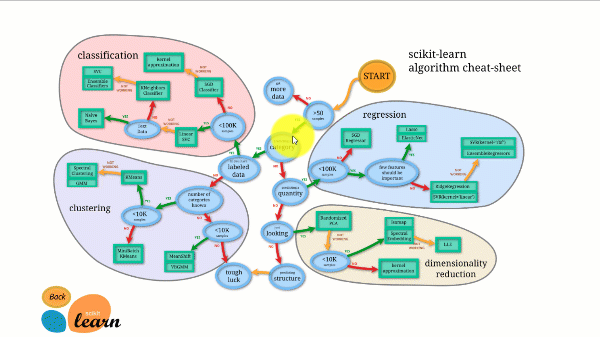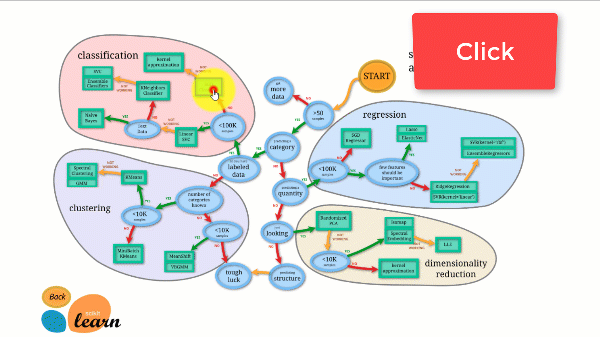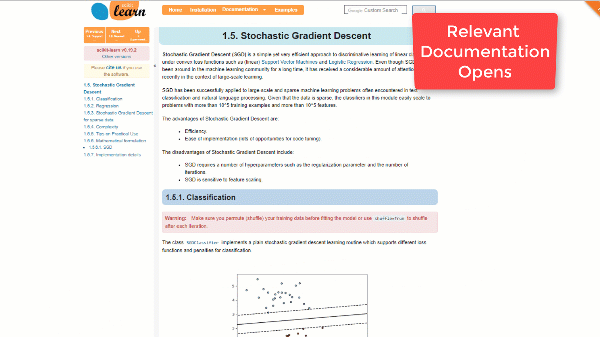
Scikit-learn is not very difficult to use and provides excellent results. However, scikit learn does not support parallel computations. It is possible to run a deep learning algorithm with it but is not an optimal solution, especially if you know how to use TensorFlow.
In this tutorial, you will learn.
- What is Scikit-learn?
- Download and Install scikit-learn
- Machine learning with scikit-learn
- Import the data
- Create the train/test set
- Build the pipeline
- Using our pipeline in a grid search
- XGBoost Model with scikit-learn
- Create DNN with MLPClassifier in scikit-learn
- LIME: Trust your Model
Download and Install scikit-learn
Option 1: AWS
scikit-learn can be used over AWS. Please refer The docker image has scikit-learn preinstalled.
To use developer version use the command in Jupyter
import sys
!{sys.executable} -m pip install git+git://github.com/scikit-learn/scikit-learn.git
Option 2: Mac or Windows using Anaconda
To learn about Anaconda installation refer https://www.guru99.com/download-install-tensorflow.html
Recently, the developers of scikit have released a development version that tackles common problem faced with the current version. We found it more convenient to use the developer version instead of the current version.
If you installed scikit-learn with the conda environment, please follow the step to update to version 0.20
Step 1) Activate tensorflow environment
source activate hello-tf
Step 2) Remove scikit lean using the conda command
conda remove scikit-learn
Step 3) Install scikit learn developer version along with necessary libraries.
conda install -c anaconda git pip install Cython pip install h5py pip install git+git://github.com/scikit-learn/scikit-learn.git
NOTE: Windows used will need to install Microsoft Visual C++ 14. You can get it from here
Machine learning with scikit-learn
This tutorial is divided into two parts:
- Machine learning with scikit-learn
- How to trust your model with LIME
The first part details how to build a pipeline, create a model and tune the hyperparameters while the second part provides state-of-the-art in term of model selection.
Step 1) Import the data
During this tutorial, you will be using the adult dataset. For a background in this dataset refer If you are interested to know more about the descriptive statistics, please use Dive and Overview tools. Refer this tutorial learn more about Dive and Overview
You import the dataset with Pandas. Note that you need to convert the type of the continuous variables in float format.
This dataset includes eights categorical variables:
The categorical variables are listed in CATE_FEATURES
- workclass
- education
- marital
- occupation
- relationship
- race
- sex
- native_country
moreover, six continuous variables:
The continuous variables are listed in CONTI_FEATURES
- age
- fnlwgt
- education_num
- capital_gain
- capital_loss
- hours_week
Note that we fill the list by hand so that you have a better idea of what columns we are using. A faster way to construct a list of categorical or continuous is to use:
## List Categorical
CATE_FEATURES = df_train.iloc[:,:-1].select_dtypes('object').columns
print(CATE_FEATURES)
## List continuous
CONTI_FEATURES = df_train._get_numeric_data()
print(CONTI_FEATURES)
Here is the code to import the data:
# Import dataset
import pandas as pd
## Define path data
COLUMNS = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country', 'label']
### Define continuous list
CONTI_FEATURES = ['age', 'fnlwgt','capital_gain', 'education_num', 'capital_loss', 'hours_week']
### Define categorical list
CATE_FEATURES = ['workclass', 'education', 'marital', 'occupation', 'relationship', 'race', 'sex', 'native_country']
## Prepare the data
features = ['age','workclass', 'fnlwgt', 'education', 'education_num', 'marital',
'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss',
'hours_week', 'native_country']
PATH = "https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data"
df_train = pd.read_csv(PATH, skipinitialspace=True, names = COLUMNS, index_col=False)
df_train[CONTI_FEATURES] =df_train[CONTI_FEATURES].astype('float64')
df_train.describe()
| age | fnlwgt | education_num | capital_gain | capital_loss | hours_week | |
| count | 32561.000000 | 3.256100e+04 | 32561.000000 | 32561.000000 | 32561.000000 | 32561.000000 |
| mean | 38.581647 | 1.897784e+05 | 10.080679 | 1077.648844 | 87.303830 | 40.437456 |
| std | 13.640433 | 1.055500e+05 | 2.572720 | 7385.292085 | 402.960219 | 12.347429 |
| min | 17.000000 | 1.228500e+04 | 1.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 28.000000 | 1.178270e+05 | 9.000000 | 0.000000 | 0.000000 | 40.000000 |
| 50% | 37.000000 | 1.783560e+05 | 10.000000 | 0.000000 | 0.000000 | 40.000000 |
| 75% | 48.000000 | 2.370510e+05 | 12.000000 | 0.000000 | 0.000000 | 45.000000 |
| max | 90.000000 | 1.484705e+06 | 16.000000 | 99999.000000 | 4356.000000 | 99.000000 |
You can check the count of unique values of the native_country features. You can see that only one household comes from Holand-Netherlands. This household won't bring us any information, but will through an error during the training.
df_train.native_country.value_counts()
United-States 29170 Mexico 643 ? 583 Philippines 198 Germany 137 Canada 121 Puerto-Rico 114 El-Salvador 106 India 100 Cuba 95 England 90 Jamaica 81 South 80 China 75 Italy 73 Dominican-Republic 70 Vietnam 67 Guatemala 64 Japan 62 Poland 60 Columbia 59 Taiwan 51 Haiti 44 Iran 43 Portugal 37 Nicaragua 34 Peru 31 France 29 Greece 29 Ecuador 28 Ireland 24 Hong 20 Cambodia 19 Trinadad&Tobago 19 Thailand 18 Laos 18 Yugoslavia 16 Outlying-US(Guam-USVI-etc) 14 Honduras 13 Hungary 13 Scotland 12 Holand-Netherlands 1 Name: native_country, dtype: int64
You can exclude this uninformative row from the dataset
## Drop Netherland, because only one row df_train = df_train[df_train.native_country != "Holand-Netherlands"]
Next, you store the position of the continuous features in a list. You will need it in the next step to build the pipeline.
The code below will loop over all columns names in CONTI_FEATURES and get its location (i.e., its number) and then append it to a list called conti_features
## Get the column index of the categorical features
conti_features = []
for i in CONTI_FEATURES:
position = df_train.columns.get_loc(i)
conti_features.append(position)
print(conti_features)
[0, 2, 10, 4, 11, 12]
The code below does the same job as above but for the categorical variable. The code below repeats what you have done previously, except with the categorical features.
## Get the column index of the categorical features
categorical_features = []
for i in CATE_FEATURES:
position = df_train.columns.get_loc(i)
categorical_features.append(position)
print(categorical_features)
[1, 3, 5, 6, 7, 8, 9, 13]
You can have a look at the dataset. Note that, each categorical feature is a string. You cannot feed a model with a string value. You need to transform the dataset using a dummy variable.
df_train.head(5)
In fact, you need to create one column for each group in the feature. First, you can run the code below to compute the total amount of columns needed.
print(df_train[CATE_FEATURES].nunique(),
'There are',sum(df_train[CATE_FEATURES].nunique()), 'groups in the whole dataset')
workclass 9 education 16 marital 7 occupation 15 relationship 6 race 5 sex 2 native_country 41 dtype: int64 There are 101 groups in the whole dataset
The whole dataset contains 101 groups as shown above. For instance, the features of workclass have nine groups. You can visualize the name of the groups with the following codes
unique() returns the unique values of the categorical features.
for i in CATE_FEATURES:
print(df_train[i].unique())
['State-gov' 'Self-emp-not-inc' 'Private' 'Federal-gov' 'Local-gov' '?' 'Self-emp-inc' 'Without-pay' 'Never-worked'] ['Bachelors' 'HS-grad' '11th' 'Masters' '9th' 'Some-college' 'Assoc-acdm' 'Assoc-voc' '7th-8th' 'Doctorate' 'Prof-school' '5th-6th' '10th' '1st-4th' 'Preschool' '12th'] ['Never-married' 'Married-civ-spouse' 'Divorced' 'Married-spouse-absent' 'Separated' 'Married-AF-spouse' 'Widowed'] ['Adm-clerical' 'Exec-managerial' 'Handlers-cleaners' 'Prof-specialty' 'Other-service' 'Sales' 'Craft-repair' 'Transport-moving' 'Farming-fishing' 'Machine-op-inspct' 'Tech-support' '?' 'Protective-serv' 'Armed-Forces' 'Priv-house-serv'] ['Not-in-family' 'Husband' 'Wife' 'Own-child' 'Unmarried' 'Other-relative'] ['White' 'Black' 'Asian-Pac-Islander' 'Amer-Indian-Eskimo' 'Other'] ['Male' 'Female'] ['United-States' 'Cuba' 'Jamaica' 'India' '?' 'Mexico' 'South' 'Puerto-Rico' 'Honduras' 'England' 'Canada' 'Germany' 'Iran' 'Philippines' 'Italy' 'Poland' 'Columbia' 'Cambodia' 'Thailand' 'Ecuador' 'Laos' 'Taiwan' 'Haiti' 'Portugal' 'Dominican-Republic' 'El-Salvador' 'France' 'Guatemala' 'China' 'Japan' 'Yugoslavia' 'Peru' 'Outlying-US(Guam-USVI-etc)' 'Scotland' 'Trinadad&Tobago' 'Greece' 'Nicaragua' 'Vietnam' 'Hong' 'Ireland' 'Hungary']
Therefore, the training dataset will contain 101 + 7 columns. The last seven columns are the continuous features.
Scikit-learn can take care of the conversion. It is done in two steps:
- First, you need to convert the string to ID. For instance, State-gov will have the ID 1, Self-emp-not-inc ID 2 and so on. The function LabelEncoder does this for you
- Transpose each ID into a new column. As mentioned before, the dataset has 101 group's ID. Therefore there will be 101 columns capturing all categoricals features' groups. Scikit-learn has a function called OneHotEncoder that performs this operation
Step 2) Create the train/test set
Now that the dataset is ready, we can split it 80/20. 80 percent for the training set and 20 percent for the test set.
You can use train_test_split. The first argument is the dataframe is the features and the second argument is the label dataframe. You can specify the size of the test set with test_size.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df_train[features],
df_train.label,
test_size = 0.2,
random_state=0)
X_train.head(5)
print(X_train.shape, X_test.shape)
(26048, 14) (6512, 14)
Step 3) Build the pipeline
The pipeline makes it easier to feed the model with consistent data. The idea behind is to put the raw data into a 'pipeline' to perform operations. For instance, with the current dataset, you need to standardize the continuous variables and convert the categorical data. Note that you can perform any operation inside the pipeline. For instance, if you have 'NA's' in the dataset, you can replace them by the mean or median. You can also create new variables.
You have the choice; hard code the two processes or create a pipeline. The first choice can lead to data leakage and create inconsistencies over time. A better option is to use the pipeline.
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder from sklearn.compose import ColumnTransformer, make_column_transformer from sklearn.pipeline import make_pipeline from sklearn.linear_model import LogisticRegression
The pipeline will perform two operations before feeding the logistic classifier:
- Standardize the variable: `StandardScaler()``
- Convert the categorical features: OneHotEncoder(sparse=False)
You can perform the two steps using the make_column_transformer. This function is not available in the current version of scikit-learn (0.19). It is not possible with the current version to perform the label encoder and one hot encoder in the pipeline. It is one reason we decided to use the developer version.
make_column_transformer is easy to use. You need to define which columns to apply the transformation and what transformation to operate. For instance, to standardize the continuous feature, you can do:
- conti_features, StandardScaler() inside make_column_transformer.
- conti_features: list with the continuous variable
- StandardScaler: standardize the variable
The object OneHotEncoder inside make_column_transformer automatically encodes the label.
preprocess = make_column_transformer(
(conti_features, StandardScaler()),
### Need to be numeric not string to specify columns name
(categorical_features, OneHotEncoder(sparse=False))
)
You can test if the pipeline works with fit_transform. The dataset should have the following shape: 26048, 107
preprocess.fit_transform(X_train).shape
(26048, 107)
The data transformer is ready to use. You can create the pipeline with make_pipeline. Once the data are transformed, you can feed the logistic regression.
model = make_pipeline(
preprocess,
LogisticRegression())
Training a model with scikit-learn is trivial. You need to use the object fit preceded by the pipeline, i.e., model. You can print the accuracy with the score object from the scikit-learn library
model.fit(X_train, y_train)
print("logistic regression score: %f" % model.score(X_test, y_test))
logistic regression score: 0.850891
Finally, you can predict the classes with predict_proba. It returns the probability for each class. Note that it sums to one.
model.predict_proba(X_test)
array([[0.83576663, 0.16423337],
[0.94582765, 0.05417235],
[0.64760587, 0.35239413],
...,
[0.99639252, 0.00360748],
[0.02072181, 0.97927819],
[0.56781353, 0.43218647]])
Step 4) Using our pipeline in a grid search
Tune the hyperparameter (variables that determine network structure like hidden units) can be tedious and exhausting. One way to evaluate the model could be to change the size of the training set and evaluate the performances. You can repeat this method ten times to see the score metrics. However, it is too much work.
Instead, scikit-learn provides a function to carry out parameter tuning and cross-validation.
Cross-validation
Cross-Validation means during the training, the training set is slip n number of times in folds and then evaluates the model n time. For instance, if cv is set to 10, the training set is trained and evaluates ten times. At each round, the classifier chooses randomly nine fold to train the model, and the 10th fold is meant for evaluation.
Grid search Each classifier has hyperparameters to tune. You can try different values, or you can set a parameter grid. If you go to the scikit-learn official website, you can see the logistic classifier has different parameters to tune. To make the training faster, you choose to tune the C parameter. It controls for the regularization parameter. It should be positive. A small value gives more weight to the regularizer.
You can use the object GridSearchCV. You need to create a dictionary containing the hyperparameters to tune.
You list the hyperparameters followed by the values you want to try. For instance, to tune the C parameter, you use:
- 'logisticregression__C': [0.1, 1.0, 1.0]: The parameter is preceded by the name, in lower case, of the classifier and two underscores.
The model will try four different values: 0.001, 0.01, 0.1 and 1.
You train the model using 10 folds: cv=10
from sklearn.model_selection import GridSearchCV
# Construct the parameter grid
param_grid = {
'logisticregression__C': [0.001, 0.01,0.1, 1.0],
}
You can train the model using GridSearchCV with the parameter gri and cv.
# Train the model
grid_clf = GridSearchCV(model,
param_grid,
cv=10,
iid=False)
grid_clf.fit(X_train, y_train)
OUTPUT
GridSearchCV(cv=10, error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...ty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False))]),
fit_params=None, iid=False, n_jobs=1,
param_grid={'logisticregression__C': [0.001, 0.01, 0.1, 1.0]},
pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',
scoring=None, verbose=0)
To access the best parameters, you use best_params_
grid_clf.best_params_
OUTPUT
{'logisticregression__C': 1.0}
After trained the model with four differents regularization values, the optimal parameter is
print("best logistic regression from grid search: %f" % grid_clf.best_estimator_.score(X_test, y_test))
best logistic regression from grid search: 0.850891
To access the predicted probabilities:
grid_clf.best_estimator_.predict_proba(X_test)
array([[0.83576677, 0.16423323],
[0.9458291 , 0.0541709 ],
[0.64760416, 0.35239584],
...,
[0.99639224, 0.00360776],
[0.02072033, 0.97927967],
[0.56782222, 0.43217778]])
XGBoost Model with scikit-learn
Let's try to train one of the best classifiers on the market. XGBoost is an improvement over the random forest. The theoretical background of the classifier out of the scope of this tutorial. Keep in mind that, XGBoost has won lots of kaggle competitions. With an average dataset size, it can perform as good as a deep learning algorithm or even better.
The classifier is challenging to train because it has a high number of parameters to tune. You can, of course, use GridSearchCV to choose the parameter for you.
Instead, let's see how to use a better way to find the optimal parameters. GridSearchCV can be tedious and very long to train if you pass many values. The search space grows along with the number of parameters. A preferable solution is to use RandomizedSearchCV. This method consists of choosing the values of each hyperparameter after each iteration randomly. For instance, if the classifier is trained over 1000 iterations, then 1000 combinations are evaluated. It works more or less like. GridSearchCV
You need to import xgboost. If the library is not installed, please use pip3 install xgboost or
use import sys
!{sys.executable} -m pip install xgboost
In Jupyter environment
Next,
import xgboost from sklearn.model_selection import RandomizedSearchCV from sklearn.model_selection import StratifiedKFold
The next step includes specifying the parameters to tune. You can refer to the official documentation to see all the parameters to tune. For the sake of the tutorial, you only choose two hyperparameters with two values each. XGBoost takes lots of time to train, the more hyperparameters in the grid, the longer time you need to wait.
params = {
'xgbclassifier__gamma': [0.5, 1],
'xgbclassifier__max_depth': [3, 4]
}
You construct a new pipeline with XGBoost classifier. You choose to define 600 estimators. Note that n_estimators are a parameter that you can tune. A high value can lead to overfitting. You can try by yourself different values but be aware it can takes hours. You use the default value for the other parameters
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1)
)
You can improve the cross-validation with the Stratified K-Folds cross-validator. You construct only three folds here to faster the computation but lowering the quality. Increase this value to 5 or 10 at home to improve the results.
You choose to train the model over four iterations.
skf = StratifiedKFold(n_splits=3,
shuffle = True,
random_state = 1001)
random_search = RandomizedSearchCV(model_xgb,
param_distributions=params,
n_iter=4,
scoring='accuracy',
n_jobs=4,
cv=skf.split(X_train, y_train),
verbose=3,
random_state=1001)
The randomized search is ready to use, you can train the model
#grid_xgb = GridSearchCV(model_xgb, params, cv=10, iid=False) random_search.fit(X_train, y_train)
Fitting 3 folds for each of 4 candidates, totalling 12 fits [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8759645283888057, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8729701715996775, total= 1.0min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=0.5, score=0.8706519235199263, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5 ............ [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8735460094437406, total= 1.3min [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8722791661868018, total= 57.7s [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8753886905447426, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8697304768486523, total= 1.3min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=0.5, score=0.8740066797189912, total= 1.4min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1 .............. [CV] xgbclassifier__max_depth=3, xgbclassifier__gamma=1, score=0.8707671043538355, total= 1.0min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8729701715996775, total= 1.2min [Parallel(n_jobs=4)]: Done 10 out of 12 | elapsed: 3.6min remaining: 43.5s [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8736611770125533, total= 1.2min [CV] xgbclassifier__max_depth=4, xgbclassifier__gamma=1, score=0.8692697535130154, total= 1.2min
[Parallel(n_jobs=4)]: Done 12 out of 12 | elapsed: 3.6min finished /Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/model_selection/_search.py:737: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal. DeprecationWarning)
RandomizedSearchCV(cv=<generator object _BaseKFold.split at 0x1101eb830>,
error_score='raise-deprecating',
estimator=Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))]),
fit_params=None, iid='warn', n_iter=4, n_jobs=4,
param_distributions={'xgbclassifier__gamma': [0.5, 1], 'xgbclassifier__max_depth': [3, 4]},
pre_dispatch='2*n_jobs', random_state=1001, refit=True,
return_train_score='warn', scoring='accuracy', verbose=3)
As you can see, XGBoost has a better score than the previous logisitc regression.
print("Best parameter", random_search.best_params_)
print("best logistic regression from grid search: %f" % random_search.best_estimator_.score(X_test, y_test))
Best parameter {'xgbclassifier__max_depth': 3, 'xgbclassifier__gamma': 0.5}
best logistic regression from grid search: 0.873157
random_search.best_estimator_.predict(X_test)
array(['<=50K', '<=50K', '<=50K', ..., '<=50K', '>50K', '<=50K'], dtype=object)
Create DNN with MLPClassifier in scikit-learn
Finally, you can train a deep learning algorithm with scikit-learn. The method is the same as the other classifier. The classifier is available at MLPClassifier.
from sklearn.neural_network import MLPClassifier
You define the following deep learning algorithm:
- Adam solver
- Relu activation function
- Alpha = 0.0001
- batch size of 150
- Two hidden layers with 100 and 50 neurons respectively
model_dnn = make_pipeline(
preprocess,
MLPClassifier(solver='adam',
alpha=0.0001,
activation='relu',
batch_size=150,
hidden_layer_sizes=(200, 100),
random_state=1))
You can change the number of layers to improve the model
model_dnn.fit(X_train, y_train)
print("DNN regression score: %f" % model_dnn.score(X_test, y_test))
DNN regression score: 0.821253
LIME: Trust your Model
Now that you have a good model, you need a tool to trust it. Machine learning algorithm, especially random forest and neural network, are known to be blax-box algorithm. Say differently, it works but no one knows why.
Three researchers have come up with a great tool to see how the computer makes a prediction. The paper is called Why Should I Trust You?
They developed an algorithm named Local Interpretable Model-Agnostic Explanations (LIME).
Take an example:
sometimes you do not know if you can trust a machine-learning prediction:
A doctor, for example, cannot trust a diagnosis just because a computer said so. You also need to know if you can trust the model before putting it into production.
Imagine we can understand why any classifier is making a prediction even incredibly complicated models such as neural networks, random forests or svms with any kernel
will become more accessible to trust a prediction if we can understand the reasons behind it. From the example with the doctor, if the model told him which symptoms are essential you would trust it, it is also easier to figure out if you should not trust the model.
Lime can tell you what features affect the decisions of the classifier
Data Preparation
They are a couple of things you need to change to run LIME with python. First of all, you need to install lime in the terminal. You can use pip install lime
Lime makes use of LimeTabularExplainer object to approximate the model locally. This object requires:
- a dataset in numpy format
- The name of the features: feature_names
- The name of the classes: class_names
- The index of the column of the categorical features: categorical_features
- The name of the group for each categorical features: categorical_names
Create numpy train set
You can copy and convert df_train from pandas to numpy very easily
df_train.head(5) # Create numpy data df_lime = df_train df_lime.head(3)
Get the class name The label is accessible with the object unique(). You should see:
- '<=50K'
- '>50K'
# Get the class name class_names = df_lime.label.unique() class_names
array(['<=50K', '>50K'], dtype=object)
index of the column of the categorical features
You can use the method you lean before to get the name of the group. You encode the label with LabelEncoder. You repeat the operation on all the categorical features.
##
import sklearn.preprocessing as preprocessing
categorical_names = {}
for feature in CATE_FEATURES:
le = preprocessing.LabelEncoder()
le.fit(df_lime[feature])
df_lime[feature] = le.transform(df_lime[feature])
categorical_names[feature] = le.classes_
print(categorical_names)
{'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
df_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 label object dtype: object
Now that the dataset is ready, you can construct the different dataset. You actually transform the data outside of the pipeline in order to avoid errors with LIME. The training set in the LimeTabularExplainer should be a numpy array without string. With the method above, you have a training dataset already converted.
from sklearn.model_selection import train_test_split
X_train_lime, X_test_lime, y_train_lime, y_test_lime = train_test_split(df_lime[features],
df_lime.label,
test_size = 0.2,
random_state=0)
X_train_lime.head(5)
You can make the pipeline with the optimal parameters from XGBoost
model_xgb = make_pipeline(
preprocess,
xgboost.XGBClassifier(max_depth = 3,
gamma = 0.5,
n_estimators=600,
objective='binary:logistic',
silent=True,
nthread=1))
model_xgb.fit(X_train_lime, y_train_lime)
/Users/Thomas/anaconda3/envs/hello-tf/lib/python3.6/site-packages/sklearn/preprocessing/_encoders.py:351: FutureWarning: The handling of integer data will change in version 0.22. Currently, the categories are determined based on the range [0, max(values)], while in the future they will be determined based on the unique values. If you want the future behavior and silence this warning, you can specify "categories='auto'."In case you used a LabelEncoder before this OneHotEncoder to convert the categories to integers, then you can now use the OneHotEncoder directly. warnings.warn(msg, FutureWarning)
Pipeline(memory=None,
steps=[('columntransformer', ColumnTransformer(n_jobs=1, remainder='drop', transformer_weights=None,
transformers=[('standardscaler', StandardScaler(copy=True, with_mean=True, with_std=True), [0, 2, 10, 4, 11, 12]), ('onehotencoder', OneHotEncoder(categorical_features=None, categories=None,...
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=True, subsample=1))])
You get a warning. The warning explains that you do not need to create a label encoder before the pipeline. If you do not want to use LIME, you are fine to use the method from the first part of the tutorial. Otherwise, you can keep with this method, first create an encoded dataset, set get the hot one encoder within the pipeline.
print("best logistic regression from grid search: %f" % model_xgb.score(X_test_lime, y_test_lime))
best logistic regression from grid search: 0.873157
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
Before to use LIME in action, let's create a numpy array with the features of the wrong classification. You can use that list later to get an idea about what mislead the classifier.
temp = pd.concat([X_test_lime, y_test_lime], axis= 1)
temp['predicted'] = model_xgb.predict(X_test_lime)
temp['wrong']= temp['label'] != temp['predicted']
temp = temp.query('wrong==True').drop('wrong', axis=1)
temp= temp.sort_values(by=['label'])
temp.shape
(826, 16)
You create a lambda function to retrieve the prediction from the model with the new data. You will need it soon.
predict_fn = lambda x: model_xgb.predict_proba(x).astype(float) X_test_lime.dtypes
age float64 workclass int64 fnlwgt float64 education int64 education_num float64 marital int64 occupation int64 relationship int64 race int64 sex int64 capital_gain float64 capital_loss float64 hours_week float64 native_country int64 dtype: object
predict_fn(X_test_lime)
array([[7.96461046e-01, 2.03538969e-01],
[9.51730132e-01, 4.82698716e-02],
[7.93448269e-01, 2.06551731e-01],
...,
[9.90314305e-01, 9.68566816e-03],
[6.45816326e-04, 9.99354184e-01],
[9.71042812e-01, 2.89571714e-02]])
You convert the pandas dataframe to numpy array
X_train_lime = X_train_lime.values X_test_lime = X_test_lime.values X_test_lime
array([[4.00000e+01, 5.00000e+00, 1.93524e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.70000e+01, 4.00000e+00, 2.16481e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
[2.50000e+01, 4.00000e+00, 2.56263e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01],
...,
[2.80000e+01, 6.00000e+00, 2.11032e+05, ..., 0.00000e+00,
4.00000e+01, 2.50000e+01],
[4.40000e+01, 4.00000e+00, 1.67005e+05, ..., 0.00000e+00,
6.00000e+01, 3.80000e+01],
[5.30000e+01, 4.00000e+00, 2.57940e+05, ..., 0.00000e+00,
4.00000e+01, 3.80000e+01]])
model_xgb.predict_proba(X_test_lime)
array([[7.9646105e-01, 2.0353897e-01],
[9.5173013e-01, 4.8269872e-02],
[7.9344827e-01, 2.0655173e-01],
...,
[9.9031430e-01, 9.6856682e-03],
[6.4581633e-04, 9.9935418e-01],
[9.7104281e-01, 2.8957171e-02]], dtype=float32)
print(features,
class_names,
categorical_features,
categorical_names)
['age', 'workclass', 'fnlwgt', 'education', 'education_num', 'marital', 'occupation', 'relationship', 'race', 'sex', 'capital_gain', 'capital_loss', 'hours_week', 'native_country'] ['<=50K' '>50K'] [1, 3, 5, 6, 7, 8, 9, 13] {'workclass': array(['?', 'Federal-gov', 'Local-gov', 'Never-worked', 'Private',
'Self-emp-inc', 'Self-emp-not-inc', 'State-gov', 'Without-pay'],
dtype=object), 'education': array(['10th', '11th', '12th', '1st-4th', '5th-6th', '7th-8th', '9th',
'Assoc-acdm', 'Assoc-voc', 'Bachelors', 'Doctorate', 'HS-grad',
'Masters', 'Preschool', 'Prof-school', 'Some-college'],
dtype=object), 'marital': array(['Divorced', 'Married-AF-spouse', 'Married-civ-spouse',
'Married-spouse-absent', 'Never-married', 'Separated', 'Widowed'],
dtype=object), 'occupation': array(['?', 'Adm-clerical', 'Armed-Forces', 'Craft-repair',
'Exec-managerial', 'Farming-fishing', 'Handlers-cleaners',
'Machine-op-inspct', 'Other-service', 'Priv-house-serv',
'Prof-specialty', 'Protective-serv', 'Sales', 'Tech-support',
'Transport-moving'], dtype=object), 'relationship': array(['Husband', 'Not-in-family', 'Other-relative', 'Own-child',
'Unmarried', 'Wife'], dtype=object), 'race': array(['Amer-Indian-Eskimo', 'Asian-Pac-Islander', 'Black', 'Other',
'White'], dtype=object), 'sex': array(['Female', 'Male'], dtype=object), 'native_country': array(['?', 'Cambodia', 'Canada', 'China', 'Columbia', 'Cuba',
'Dominican-Republic', 'Ecuador', 'El-Salvador', 'England',
'France', 'Germany', 'Greece', 'Guatemala', 'Haiti', 'Honduras',
'Hong', 'Hungary', 'India', 'Iran', 'Ireland', 'Italy', 'Jamaica',
'Japan', 'Laos', 'Mexico', 'Nicaragua',
'Outlying-US(Guam-USVI-etc)', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Puerto-Rico', 'Scotland', 'South', 'Taiwan',
'Thailand', 'Trinadad&Tobago', 'United-States', 'Vietnam',
'Yugoslavia'], dtype=object)}
import lime
import lime.lime_tabular
### Train should be label encoded not one hot encoded
explainer = lime.lime_tabular.LimeTabularExplainer(X_train_lime ,
feature_names = features,
class_names=class_names,
categorical_features=categorical_features,
categorical_names=categorical_names,
kernel_width=3)
Lets choose a random household from the test set and see the model prediction and how the computer made his choice.
import numpy as np np.random.seed(1) i = 100 print(y_test_lime.iloc[i]) >50K
X_test_lime[i]
array([4.20000e+01, 4.00000e+00, 1.76286e+05, 7.00000e+00, 1.20000e+01,
2.00000e+00, 4.00000e+00, 0.00000e+00, 4.00000e+00, 1.00000e+00,
0.00000e+00, 0.00000e+00, 4.00000e+01, 3.80000e+01])
You can use the explainer with explain_instance to check the explanation behind the model
exp = explainer.explain_instance(X_test_lime[i], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

We can see that the classifier predicted the household correctly. The income is, indeed, above 50k.
The first thing we can say is the classifier is not that sure about the predicted probabilities. The machine predicts the household has an income over 50k with a probability of 64%. This 64% is made up of Capital gain and marital. The blue color contributes negatively to the positive class and the orange line, positively.
The classifier is confused because the capital gain of this household is null, while the capital gain is usually a good predictor of wealth. Besides, the household works less than 40 hours per week. Age, occupation, and sex contribute positively to the classifier.
If the marital status were single, the classifier would have predicted an income below 50k (0.64-0.18 = 0.46)
We can try with another household which has been wrongly classified
temp.head(3) temp.iloc[1,:-2]
age 58 workclass 4 fnlwgt 68624 education 11 education_num 9 marital 2 occupation 4 relationship 0 race 4 sex 1 capital_gain 0 capital_loss 0 hours_week 45 native_country 38 Name: 20931, dtype: object
i = 1
print('This observation is', temp.iloc[i,-2:])
This observation is label <=50K predicted >50K Name: 20931, dtype: object
exp = explainer.explain_instance(temp.iloc[1,:-2], predict_fn, num_features=6) exp.show_in_notebook(show_all=False)

The classifier predicted an income below 50k while it is untrue. This household seems odd. It does not have a capital gain, nor capital loss. He is divorced and is 60 years old, and it is an educated people, i.e., education_num > 12. According to the overall pattern, this household should, like explain by the classifier, get an income below 50k.
You try to play around with LIME. You will notice gross mistakes from the classifier.
You can check the GitHub of the owner of the library. They provide extra documentation for image and text classification.
Summary
Below is a list of some useful command with scikit learn version >=0.20
|
create train/test dataset |
trainees split |
|
Build a pipeline |
|
|
select the column and apply the transformation |
makecolumntransformer |
|
type of transformation |
|
|
standardize |
StandardScaler |
|
min max |
MinMaxScaler |
|
Normalize |
Normalizer |
|
Impute missing value |
Imputer |
|
Convert categorical |
OneHotEncoder |
|
Fit and transform the data |
fit_transform |
|
Make the pipeline |
make_pipeline |
|
Basic model |
|
|
logistic regression |
LogisticRegression |
|
XGBoost |
XGBClassifier |
|
Neural net |
MLPClassifier |
|
Grid search |
GridSearchCV |
|
Randomized search |
RandomizedSearchCV |