What is AI?
Artificial intelligence is imparting a cognitive ability to a machine. The benchmark for AI is the human intelligence regarding reasoning, speech, and vision. This benchmark is far off in the future.

AI has three different levels:
- Narrow AI: A artificial intelligence is said to be narrow when the machine can perform a specific task better than a human. The current research of AI is here now
- General AI: An artificial intelligence reaches the general state when it can perform any intellectual task with the same accuracy level as a human would
- Active AI: An AI is active when it can beat humans in many tasks
Early AI systems used pattern matching and expert systems.
What is ML?
Machine learning is the best tool so far to analyze, understand and identify a pattern in the data. One of the main ideas behind machine learning is that the computer can be trained to automate tasks that would be exhaustive or impossible for a human being. The clear breach from the traditional analysis is that machine learning can take decisions with minimal human intervention.
Machine learning uses data to feed an algorithm that can understand the relationship between the input and the output. When the machine finished learning, it can predict the value or the class of new data point.
What is Deep Learning?
Deep learning is a computer software that mimics the network of neurons in a brain. It is a subset of machine learning and is called deep learning because it makes use of deep neural networks. The machine uses different layers to learn from the data. The depth of the model is represented by the number of layers in the model. Deep learning is the new state of the art in term of AI. In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other

Machine Learning Process
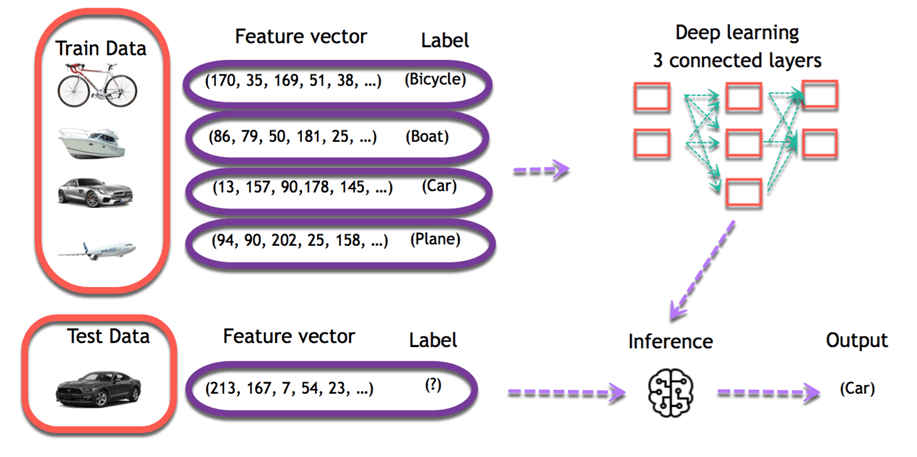
Imagine you are meant to build a program that recognizes objects. To train the model, you will use a classifier. A classifier uses the features of an object to try identifying the class it belongs to.
In the example, the classifier will be trained to detect if the image is a:
- Bicycle
- Boat
- Car
- Plane
The four objects above are the class the classifier has to recognize. To construct a classifier, you need to have some data as input and assigns a label to it. The algorithm will take these data, find a pattern and then classify it in the corresponding class.
This task is called supervised learning. In supervised learning, the training data you feed to the algorithm includes a label.
Training an algorithm requires to follow a few standard steps:
- Collect the data
- Train the classifier
- Make predictions
The first step is necessary, choosing the right data will make the algorithm success or a failure. The data you choose to train the model is called a feature. In the object example, the features are the pixels of the images.
Each image is a row in the data while each pixel is a column. If your image is a 28x28 size, the dataset contains 784 columns (28x28). In the picture below, each picture has been transformed into a feature vector. The label tells the computer what object is in the image.

The objective is to use these training data to classify the type of object. The first step consists of creating the feature columns. Then, the second step involves choosing an algorithm to train the model. When the training is done, the model will predict what picture corresponds to what object.
After that, it is easy to use the model to predict new images. For each new image feeds into the model, the machine will predict the class it belongs to. For example, an entirely new image without a label is going through the model. For a human being, it is trivial to visualize the image as a car. The machine uses its previous knowledge to predict as well the image is a car.
Deep Learning Process
In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other.
Consider the same image example above. The training set would be fed to a neural network
Each input goes into a neuron and is multiplied by a weight. The result of the multiplication flows to the next layer and become the input. This process is repeated for each layer of the network. The final layer is named the output layer; it provides an actual value for the regression task and a probability of each class for the classification task. The neural network uses a mathematical algorithm to update the weights of all the neurons. The neural network is fully trained when the value of the weights gives an output close to the reality. For instance, a well-trained neural network can recognize the object on a picture with higher accuracy than the traditional neural net.
Automate Feature Extraction using DL
A dataset can contain a dozen to hundreds of features. The system will learn from the relevance of these features. However, not all features are meaningful for the algorithm. A crucial part of machine learning is to find a relevant set of features to make the system learns something.
One way to perform this part in machine learning is to use feature extraction. Feature extraction combines existing features to create a more relevant set of features. It can be done with PCA, T-SNE or any other dimensionality reduction algorithms.
For example, an image processing, the practitioner needs to extract the feature manually in the image like the eyes, the nose, lips and so on. Those extracted features are feed to the classification model.
Deep learning solves this issue, especially for a convolutional neural network. The first layer of a neural network will learn small details from the picture; the next layers will combine the previous knowledge to make more complex information. In the convolutional neural network, the feature extraction is done with the use of the filter. The network applies a filter to the picture to see if there is a match, i.e., the shape of the feature is identical to a part of the image. If there is a match, the network will use this filter. The process of feature extraction is therefore done automatically.

Difference between Machine Learning and Deep Learning
|
Machine Learning |
Deep Learning |
|
|
Data Dependencies |
Excellent performances on a small/medium dataset |
Excellent performance on a big dataset |
|
Hardware dependencies |
Work on a low-end machine. |
Requires powerful machine, preferably with GPU: DL performs a significant amount of matrix multiplication |
|
Feature engineering |
Need to understand the features that represent the data |
No need to understand the best feature that represents the data |
|
Execution time |
From few minutes to hours |
Up to weeks. Neural Network needs to compute a significant number of weights |
|
Interpretability |
Some algorithms are easy to interpret (logistic, decision tree), some are almost impossible (SVM, XGBoost) |
Difficult to impossible |
When to use ML or DL?
In the table below, we summarize the difference between machine learning and deep learning.
| Machine learning | Deep learning | |
| Training dataset | Small | Large |
| Choose features | Yes | No |
| Number of algorithms | Many | Few |
| Training time | Short | Long |
With machine learning, you need fewer data to train the algorithm than deep learning. Deep learning requires an extensive and diverse set of data to identify the underlying structure. Besides, machine learning provides a faster-trained model. Most advanced deep learning architecture can take days to a week to train. The advantage of deep learning over machine learning is it is highly accurate. You do not need to understand what features are the best representation of the data; the neural network learned how to select critical features. In machine learning, you need to choose for yourself what features to include in the model.

Summary
Artificial intelligence is imparting a cognitive ability to a machine. Early AI systems used pattern matching and expert systems.
The idea behind machine learning is that the machine can learn without human intervention. The machine needs to find a way to learn how to solve a task given the data.
Deep learning is the breakthrough in the field of artificial intelligence. When there is enough data to train on, deep learning achieves impressive results, especially for image recognition and text translation. The main reason is the feature extraction is done automatically in the different layers of the network.