There are a couple of architecture patterns that I tend to use over and over again when I build new solutions. In this post I will give an overview why I use them and how I implement them in a serverless, and often event-driven, way on AWS.
Storage-First
Storage-First is one of the patterns I use the most. I would say that there is not a single architecture that I have designed that doesn't take advantage of this. Just as then name suggest this pattern is all about storing / capturing incoming request/data using AWS managed services. This is a strong pattern if no data is needed to be returned from the API.
By storing the data we have an exact copy in case of our processing fails. Examples of failures could be, but not limited to.
- Failure to process the data
- Failure storing the data to persisting storage
- Failure when calling a downstream 3rd party service or API.
This is standard way to handle requests using Amazon API Gateway where we like to process the incoming request and store the data in Amazon S3, it could look something like this.


If the AWS Lambda function now fail to process the data, is lacking permissions to call Amazon S3 or any other failure, the data would be lost. The client would get an 4XX error back and would need to retry calling the API. This can become some very complex logic in the client and can be very frustrating. Instead our API implementation could handle this problem with the Storage-First approach, that would then look something like this.

The request and data would be stored in Amazon SQS using a service integration in API Gateway, and even if our Lambda functions fail the request is secure in SQS and can be processed again later.
Now it doesn't have to be an API Gateway and SQS queue to implement this pattern in serverless way. We can use API gateway with DynamoDB, IoT Core with SQS and many other different approaches. The important part is that the request and data is stored prior to processing.

Circuit breaker
I use the Circuit breaker pattern in so many distributed systems I have been working with. It gives the possibility to fail fast in case of a downstream service becoming unavailable. This can be a service in the same application or a 3rd party service. By not calling a service, that the system know is unavailable, it can prevent performance problems and also plays nice in the distributed echo system, by not overwhelming the unavailable service with requests.
When I'm using the circuit breaker I normally do that from a AWS StepFunction, so in case of a single Lambda function integration I would instead integrate with StepFunction and do the work inside the StepFunction. Since StepFunctions integrate with so many services it is actually possible to wrap all work inside the Circuit breaker. The Lambda Invoke step, in the image, would be replaced with the service that do the actual work, if that is an other StepFunction, ECS Task, API, doesn't really matter.
The circuit breaker implementation looks something like this.

What we do is first of all get the circuit status from DynamoDB via a getItem call. Then it's possible to check if the circuit is open or closed, the circuit is considered closed if there is no record in the DynamoDB table or if the value is CLOSED. If the circuit is closed the work is carried out. If the circuit would be open there is a check to see if the last update of the circuit status was more than X seconds ago. If time has passed the work is carried out to see if the service has healed. Otherwise no work is carried out and we fail fast.
When work is carried out, the Lambda function will retry three times with the built in retry mechanism. If the work still failed after the retries the status of the circuit is updated to OPEN which lead to consecutive invocation failing fast. If the work is successful the circuit is updated to CLOSED.
If we now combine this with a health check implementation it would be possible to almost get an fully automated circuit that will open and close on its own. It could look something like this.

In this example our downstream service is implemented in Lambda function(s) that if fronted by an API Gateway. The Lambda function write logs and metrics to CloudWatch. We can the use Log event filters to create additional metrics from the application logs, in combination with Lambda function metrics we can create smart Cloudwatch Alarms. When an alarm changes state that is sent to Amazon EventBridge that can invoke a StepFunction that open or close the circuit based on the alarm.
If we also combine this with a shallow health check, that is called from a scheduled Lambda function, that then sends the health check result to EventBridge. Once again the StepFunction is invoked and based on the health check the circuit is opened or closed.
This way we get automated circuit breaker.
Storage-First and Circuit breaker
After looking at both Storage-First and Circuit breaker pattern, we can create a combination of them both. This combination of patterns almost become a "super pattern". By making sure we store our requests first we can process them later when the circuit once again is closed. While the circuit is still open we save on processing power and just don't call the downstream service. We just let the request stay in the storage without any risk of loosing anything.
Feature flags
"Feature flag everything all the time" must be one of the best statements I have ever heard a colleague say. It's so very true, by making sure all new features and functionality can be controlled by feature flags there is a possibility to turn it off if problems should appear. Now don't get me wrong, I don't say that you should keep feature flags forever, that is really bad practice. However, I strongly believe that if all new features are flagged from the start the development of them will be so much easier. Also releasing new versions to production will benefit from this approach. When the feature then has been released to production and is stable, the flags can be removed.
I have already written about how to use AppConfig for your feature flags in AWS StepFunctions, check out this post to read more and get more details.
Step Functions CRUD
As stated in the start of this post, none of the patterns mentioned has been invented by me in any means. This last pattern is no exception, but as I think this is so brilliant and something I have started to investigate. So I just have to include it. The first time I saw this was when James Beswick spoke about building serverless espresso at re:Invent. This is a brilliant talk and you view it here.
Many of you are probably familiar with the following patter, API Gateway with Lambda integrations. Where each method has a separate integration. This is what I have been using for several years and also what I have been advocating. One Lambda function per method, keep the Lambda function clean and with one single task. However, just as James mentions in his re:Invent talk this can become design that is very hard to get an easy overview of. If you have many paths and methods there will be a massive amount of Lambda functions, getting an quick overview, monitoring, and debugging can be an overwhelming task.

I would never recommend any form of method routing being implemented in an Lambda function. However, with StepFunctions integration with API Gateway it's a completely different story. By utilizing StepFunctions powerful choice state we can route the different methods down different paths. This will give an easy to overview method handling, it will also be so much easier to debug in case of a failure.
So how does it work? Lets start by looking at an example state machine.

We pick up the request from API Gateway and start by using a choice state to determine the method and sending the request down different paths depending on the method. In each of the paths we can use the stepFunction built in error handling and retry mechanism. This creates a very powerful and simple API integration with excellent debugging and error handling. In the above example I illustrate this with a single Lambda function. In real life the flows would of course be longer.
A different option instead of having each of the flows in the sate state machine would be to create separate state machines for each flow and use the support in StepFunctions to start execution of a separate state machine. That way it would be possible to break out and isolate each flow, which would create a "One StepFunction one job" kind of approach.
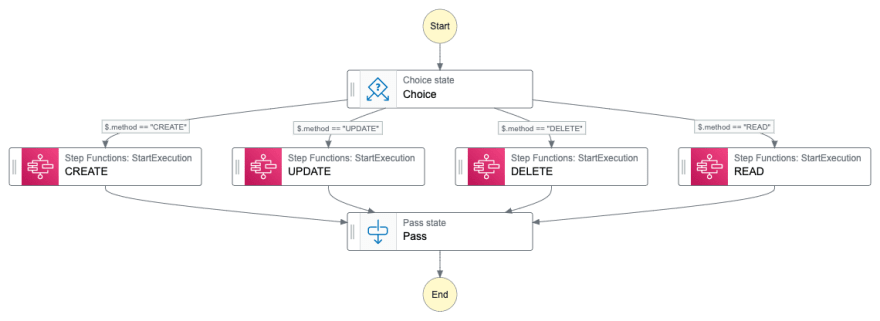
I'm still to use this pattern in a live project but as I see it, this is just a matter of time. I think this is a excellent pattern and way to create an API integration. The only risk I can see is if the number of paths explode and it's not only used for a couple of different methods. But it's like that with everything, if you misuse things they becomes hard to handle.
huge shout-out and thank you to James and the rest of the Serverless Espresso Team for creating this!!
Final Words
This was a high level overview of some different architecture patterns I use and how I have implemented them in AWS using serverless technologies. Stay tuned for more in depth posts in the future.