
Introduction to Regular Expression in Python
Regular expressions are the expression which contains characters that are used to find this sequence of character pattern in the given sentence or file or strings. In general regular expressions play a major role in pattern searching or string matching. Regular expressions are abbreviated to regex or regexp. Along with Python, many different programming languages have been embedded with this search engine using regular expression for finding or matching the given string or characters.
In Python, regular expressions are used in the same way the other languages do for searching the patterns using the given specialized syntax as a regular expression. As regular expressions are used more popularly in UNIX, whereas in Python, it has re as regular expression module which has Perl like support in Python.
This article gives the basic knowledge of how and where the regular expressions are used for Python examples.
Working of Regular Expression in Python
In Python, a regular expression which is a sequence of characters for pattern matching, has re module that gives the use of regular in Python. This re module in Python must be imported before we start with the use of the regular expression in any string matching.
In Python, the regular expressions are written as shown below:
Syntax:
import re
re.match (pattern, string or character)Parameters:
- pattern: In this, a sequence of character or regular expression is given that has to be matched with a given string or character.
- String or character: This contains a string of character that has to be searched to match the pattern specified in the pattern argument from the start of the string till the end or as specified.
When we want to find the string or match the pattern given, we use a regular expression. In Python or any other programming languages, some characters are specially used as regular expressions, which are known as metacharacters that support the implementation of Python’s regular expressions.
The below list gives a complete list of Metacharacters:
- \s => this used to match whitespaces.
- \S => this is used match non-whitespaces.
- \d => this is used to match numerical or decimal digits.
- \D => this is used to match the non-numerical or non-digit character.
- \w => this is used to match the alphabets and numbers, also known as alphanumeric characters.
- \W => this is used to match the non-alphanumeric characters.
The characters in this above are used have whitespaces specified like “\t \n \r \v \f”, numerical characters ranges from “0 – 9”, and alphanumeric characters range from “A – Za – z0 – 9”. For not specifying these characters, we can just use “^” before any of the above ranges specified, like if we want to specify non-numerical, then we can write it as “^0 – 9”, similarly it applies to all other Meta characters.
In this regular expression, there are some symbols used with this sequence of characters; they are as follows:
1. “^” this symbolizes starts with.
Ex: “^educab,” this expression says to match the strings that start with the alphabet “e”.
2. “$” this symbolizes for the sequence that ends with.
Ex: e…b$ this says to match the string that ends with b.
3. “+” this symbolizes the occurrences of character for one or more times.
Ex: “ed+u this searches for the string that has at least one or more occurrence of alphabet “d”.
4. “?” this symbolizes to have zero or one occurrence of the character after this symbol.
Ex: “ma? n” this searches for the string having no or one time the alphabet “n”.
5. “*” this symbolizes the occurrences of characters for zero or more times.
Ex: “ma*n” this searches with a string having no or any number of occurrences of the alphabet “n”.
6. “{}” this symbolizes the characters are matched by the number of times that is specified within the braces.
Ex: a{2,3} it searches in the string to have at least 2 ‘a’, and at the most 3 ‘a’ repetitions to match the pattern given.
7. “|” this symbolizes similarly to or operator.
Ex: a|b this searches for the string having either alphabet ‘ a’ or alphabet ‘b’.
8. “()” this symbolizes to group sub-patterns.
Ex: (a | b | c)at this searches in the string having either of these alphabets means any string having either “a” or “b” or “c” followed by alphabets “at”.
Methods of Regular Expression in Python
In Python with re module, it has many different methods like:
1. re.match()
This method is used to match the sequence of characters to the string given. Suppose the regular expression is “(e\w+)\W(e\w+)” so by this, we can say we have to match the string which has the starting alphabet as “e” followed by any alphanumerical characters but not ending with alphabet “e”.
Below is the Python code:
Syntax:
re. match(pattern, string, flag =0)Code:
lst = "Educab is the best online training portal"
r = re. match( '(E\w+)\w', lst)
if r:
print( r.group())
else:
print "No match"Output:
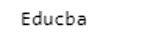
2. search()
This method is also similar to the match method; this also has two arguments to search for the given string’s first pattern.
Syntax:
re.search (pattern, string)Code:
import re
str = "Educab is the best online training portal"
r = re.search ('^Educab', str)
if r:
print ("match found")
else:
print ("match not found")Output:

3. findall()
Is the method of re module that returns all the matches in the list of strings.
Syntax:
re.findall (pattern, str)Code:
import re
str = "Educab 1 is 2 the 3 best 4 online 5 training 6 portal 7"
p = '\d+'
r = re.findall ( p, str)
print (r )Output:
![]()
Conclusion
A regular expression is a small piece of code used in any programming language for pattern matching. The regular expression in Python plays the same role as in Perl. In Python, it has its own regular expression module embedded like other languages have. There are several re modules which will help us to find the patterns quickly.
Many different metacharacters are also used to create regular expressions for finding the character or string in the given lists. Thus Python also has the regular expression, which is mainly used in checking for the credentials like reentering of email id in any of the forms, etc.