IoT Incident Response
Incident management is an enormous topic and many excellent and thorough volumes have been written about its utility and execution in the traditional IT enterprise. At its core, incident management is a lifecycle-driven set of activities that range from planning, detection, containment, eradication, and recovery, to ultimately the learning process about what went wrong and how to improve one's posture to prevent similar future incidents. This chapter provides guidance for organizations—corporate or otherwise—who plan to integrate IoT systems into their enterprises and who need to develop or update their incident response plans to suit.
Incident management for IoT systems follows the same frameworks that are already familiar to us. There are simply new considerations and questions to answer when trying to plan for effectively responding to compromised IoT-related systems. To distinguish the IoT from conventional IT, we postulate the following incidents:
In the near future, a utility company purchases a fleet of connected vehicles to enhance driver safety and increase savings related to fuel consumption and liability (for example, guarding against aggressive driving). One day, one of the utility vehicles crashes into another car, causing damage and injury. When speaking with the driver, it was noted that the vehicle simply stopped responding to their controls.
A heart patient with an implanted pacemaker and diseased heart dies suddenly. The coroner notes that the patient had a pacemaker, but also notes that it was supposedly operating correctly. The case is ruled a myocardial infarction, death by natural causes.
Both of these device types—connected vehicles and pacemakers—will be supported by different types of enterprises, some on-premises and some in the cloud. Both also demonstrate the blurred lines between a potential IoT security incident and normal, everyday occurrences. This drives a need to examine incident management in a manner that focuses on the underlying business/mission processes of the IoT devices and systems, to understand how attackers might use the guise of everyday happenstance to mask their malicious intent and actions. This should be accomplished by making sure the security engineers charged with the operational protection of IoT systems have a fundamental understanding of the threat models that underlie those systems.
IRPs will vary for different enterprise types. For example, if your organization has no intent to operate industrial IoT systems, but has recently adopted a bring your own IoT device policy, your IRP may stop at the point that a compromise has been identified, contained, and eradicated. It may not in this case extend into deep, intrusive forensics on the nature of the IoT device vulnerability (you can simply ban the device type from your networks going forward). If, however, your enterprise utilizes consumer and industrial IoT devices/apps for routine business functions, your IRP may need to include more sophisticated forensics after containing and eradicating the compromise.
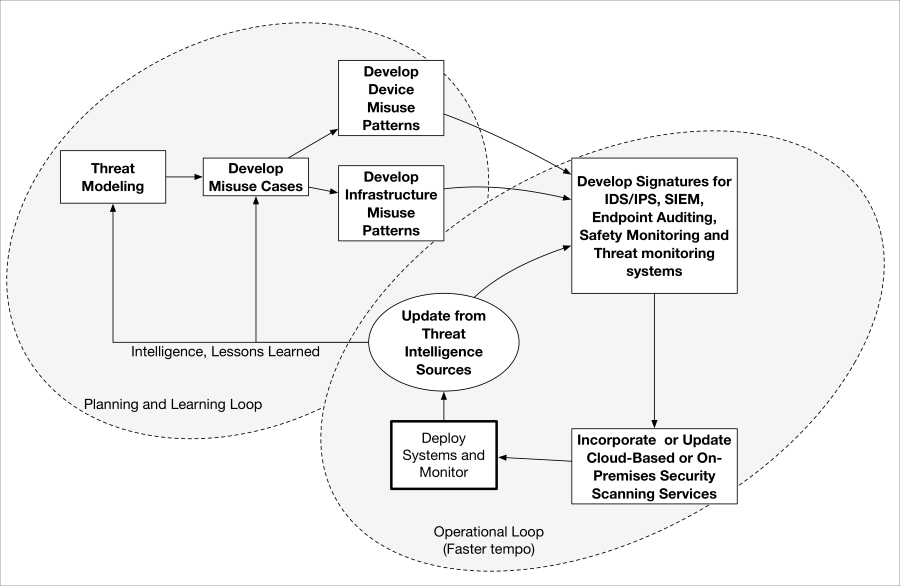
Ideally, misuse cases will be created during the upfront threat modeling process. Many specific misuse patterns can then be generated for each misuse case. Misuse patterns should be low-level enough that they can be decomposed into signature sets applicable to the monitoring technology (for example, IDS/IPS, SIEM, and so on) that will be used both on-premises and in your cloud environment. Patterns can include device patterns, network patterns, service performance, and just about anything that indicates potential misuse, malfunction or outright compromise.
In many IoT use cases, SIEMs can be telemetry-enhanced. We say telemetry-enhanced SIEMs, because physically interacting IoT devices have many additional properties that may be monitorable and important for detecting misbehavior or misuse. Temperature, time of day, event correlation with other neighboring IoT device states: almost any kind of available data can be envisioned to enable a power, detection, containment, and forensic posture beyond traditional SIEM use.
In the case of the connected utility vehicle incident described in the introduction, the culprit may have been a disgruntled employee who instigated a remote attack against the connected vehicle subsystems responsible for controlling the braking system (for example, injecting ECU communications into the network-connected CAN bus). Without proper forensics capabilities, it may be difficult or impossible to identify this individual. What is even more concerning is that in most cases, the insurance investigators would not even know that they should consider exploring the possibility of a security-compromised system!
In the case of the pacemaker patient, the culprit may have been a former employee trying to force the victim to pay money by adapting and packaging an attack learned on the Internet—the delivery of ransomware to close-range medical devices that have a specific microcontroller and interface set. Without an understanding that this is even a possible attack vector, there is no in-depth investigation. Moreover, the ransomware can be designed to self-wipe right after the event to destroy any evidence of the malfeasance.
These scenarios show that IoT incident management takes a few twists and turns from conventional IT enterprises, as follows:
The physical nature of the networked things, their locations, and who owns or operates them. The cyber-physical aspects of incident response may include a safety factor—even life and death—especially for medical, transportation, and other industrial IoT use cases.
The cloud aspects of managing the physical things (as per the previous chapter), including the fact that many of the direct incident response activities may be out of the immediate control of one's organization.
The ease with which attackers can mask their intentions and actions by disguising the results in the noise of everyday happenings. The timing of an attack puts defenders at a serious disadvantage. The goals of an IoT attack, especially against cyber-physical systems, can often be as simple as crashing a car or causing traffic lights to stop working. A skilled attacker may be able to pull these types of attacks off relatively quickly to meet their end goals, leaving defenders with limited ability to stop the attacks.
The possibility that other seemingly unrelated IoT things that are connected to common hubs and gateways in the proximity of the compromise may provide interesting new datasets contributing to incident detection and forensics.
The example situations also illustrate the need to be able to perform comprehensive incident management and forensics on deployed IoT products in order to understand and respond when there is a potential ongoing campaign against an IoT system or a class of IoT product. Forensics can also be leveraged to determine and assign liability for IoT product malfunctions (whether malicious or not), and bring to justice those that would cause adverse effects within IoT systems. This is even more important in CPS, whether medical devices, industrial control, smart home appliances, or others that involve physical-world detection and actuation.
This chapter focuses on building, maintaining, and executing an incident response plan for your organization so that you may promote improved situational awareness and response to the various operational IoT hazards (ranging from low-level incidents to full-scale compromises). This is accomplished in the following subsections:
Defining IoT incident response and management: Here we will define and establish the goals of IoT incident response and what it needs to accommodate.
Planning and executing IoT incident response: In this section, we will explore how to incorporate the right facets of incident response into your organization as a structured plan. We will detail how to categorize and plan for different incidents/events, as well as plan for triage and forensics operations (as per an IRP). Within forensics, we will discuss how to acquire forensic firmware images of the IoT devices. Lastly, we will provide some practical instruction in operationalizing and executing your incident response plan. The IoT aspects of executing incident response may also pertain to your cloud provider (assuming you support CSP-hosted subsystems). Using your incident response plan addresses methods of detecting compromises and other incidents, executing post-incident forensics, and, very importantly, integrating lessons learned into your security lifecycle.
IoT incident response and management can be broken into four phases:
Planning
Detection and analysis
Containment, eradication, and recovery
Post-incident activity
The following figure provides a view into the processes and how they relate to each other:
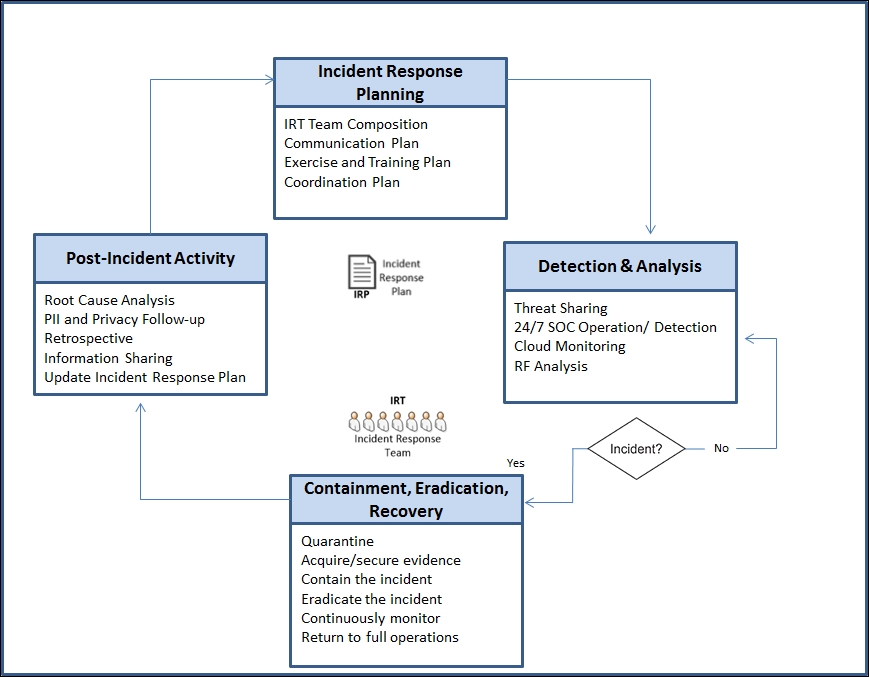
Any organization should have, at a minimum, these processes well documented and tailored for its unique system(s), technologies, and deployment approaches.
Planning (sometimes called incident response preparation) is composed of those activities that are, figuratively speaking, designed to keep you from behaving like a deer in headlights when disaster strikes. If your company were to experience a massive denial of service attack that your load balancers and gateway couldn't keep up with, do you know what to do? Does your cloud provider handle this automatically, or are you expected to intervene by escalating services? If you find evidence that some of your web servers have been compromised, do you simply take them down and refresh them with golden images? What do you do with the compromised images? Who do you give them to, and how? What about record-keeping, rules, who gets involved and when, how to communicate, and so on? These and many other questions should be answered with the utmost precision in a detailed incident response plan.
NIST SP 800-62r2 provides a template and discussion of the contents of an incident response plan (IRP) and procedures. This template can be augmented for IoT-specific characteristics, such as determining what additional data should be collected (for example, physical sensor data in concert with specific message sets and times) in response to incidents ranging from erroneous behavior to full-scale compromise. Having a plan in place allows you to focus on critical analysis tasks during an incident, such as identifying the types and severity of the compromise.
The act of categorizing systems is strongly emphasized in the federal government space to identify whether specific systems are mission critical and to identify the impact of compromised data. From an enterprise IoT perspective, it is useful to categorize your systems, when possible, in a similar manner. The categorization of IoT systems allows for the tailoring of response procedures based on the business/mission impact of an incident, the safety impacts of an incident, and the need for near-real-time handling to stop imminent damage/harm.
NIST FIPS 199 (http://csrc.nist.gov/publications/fips/fips199/FIPS-PUB-199-final.pdf) provides some useful approaches for the categorization of information systems. We can borrow from and augment that framework to help us categorize IoT systems. The following table is borrowed from FIPS 199 to show the potential impact on the security objectives of confidentiality, integrity, and availability:
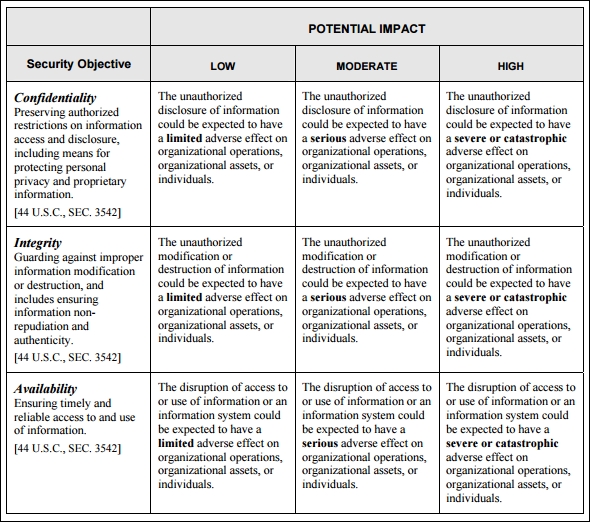
The impact is then analyzed in terms of impact on organizations or individuals. In FIPS 199, we can see that the impact on organizations and individuals can be low, medium, or high depending on the effect of confidentiality, integrity, or availability loss.
With IoT systems, we can continue to use this framework; however, it is also important to understand the impact of time and how time can drive the critical need for a response such as in safety-impacting systems. Looking back at our earlier examples, if we identify that someone has been attempting unsuccessfully to access an automotive fleet's systems, some potential responses may seem overly drastic. But given the potentially catastrophic nature of the compromise, combined with the motivation and intent of the attacker (for example, crashing a car), drastic responses may well be warranted. For example, the incident response plan may call for the manufacturer to temporarily disable all of the connected vehicle systems or comprehensively check the integrity of other electronic control units in the entire fleet.
The question to ask is whether there is the potential for imminent danger to employees, customers, or others if an identified attack pattern against IoT assets becomes known. If a company's security leadership is aware that someone was actively trying to compromise their fleet's connected IoT system, and yet the company continued to let those systems operate with a resulting injury/death, what are the potential liabilities and resultant legal claims against the organization?
The European Union Agency for Network and Information Security (ENISA) recently examined threat trends (https://www.enisa.europa.eu/publications/strategies-for-incident-response-and-cyber-crisis-cooperation/at_download/fullReport) in emerging technology areas. The report noted growth trends that have some bearing on the Internet of Things, namely:
Malicious code: worms/Trojans
Web-based attacks
Web application attacks/injection attacks
Denial of service
Phishing
Exploit kits
Physical damage/theft/loss
Insider threat
Information leakage
Identity theft/fraud
Organizations need to be ready to respond to each of these types of threats. The incident response plan will lay out the procedures that must be followed by various roles within the organization. These procedures may be tailored slightly depending on the impact of a compromise to the business or stakeholders. At a minimum, the procedures should outline when to escalate the identification of an incident to more senior or specialized personnel.
Procedures should also detail when to notify stakeholders of a suspected compromise of their data and what exactly to tell them as part of that notification. They should also specify whom to communicate with during the response, the steps to take to reach a compromise, and how to preserve an evidence chain of custody during the ensuing investigation. With respect to chain of custody, if there is a third-party cloud service provider involved, the cloud service plan (or SLA) needs to specify how that provider will support maintaining a chain of custody during incidents (in compliance with local or national laws).
Chances are you are leveraging at least one cloud service provider to support your IoT services. Cloud SLAs are extremely important in your incident response plan; unfortunately, Cloud SLA objectives and contents are not well streamlined across the industry. In other words, be aware that some CSPs may not provide adequate IR support when it's most needed.
The Cloud Security Alliance's Security Guidance for Critical Areas of Focus in Cloud Computing V3.0 (https://cloudsecurityalliance.org/guidance/csaguide.v3.0.pdf, Section 9.3.1) states that the following aspects of IR should be addressed in your cloud provider's SLA:
Points of contact, communication channels, and availability of IR teams for each party
Incident definitions and notification criteria, both from provider to customer and to any external parties
CSP support to customers for incident detection (for example, available event data, notification about suspicious events, and so on)
Definition of roles/responsibilities during a security incident, explicitly specifying support for incident handling provided by the CSP (for example, forensic support via collection of incident data/artifacts, participation/support in incident analysis, and so on)
Specification of regular IR testing carried out by the parties to the contract and whether results will be shared
Scope of post-mortem activities (for example, root cause analysis, IR report, integration of lessons learned into security management, and so on)
Clear identification of responsibilities around IR between provider and consumer as part of the SLA
Finding the right technical resources to staff an incident response team is always a challenge. Carnegie Mellon's CERT organization (http://www.cert.org/incident-management/csirt-development/csirt-staffing.cfm) notes that team staffing depends on a number of factors, including:
Mission and goals
Available staff expertise
Anticipated incident load
Constituency size and technology base
Funding
Typically, an incident manager will be chosen to bring together a number of team members, based on the scope of the incident and the response required. It is crucial to keep a cadre of staff well trained in incident response and ready to assist as necessary when an incident does occur. The incident manager must be fully versed in the local IR procedures, as well as the cloud provider's SLAs.
Proper planning up front will enable the right pairing of staff with the specifically required roles needed for each incident. Teams responding to IoT-related incidents will need to include some unique skill sets driven by the specific IoT implementations and deployment use cases involved. In addition, staff need to have a deep understanding of the underlying business purpose of the compromised IoT system. Keep an emergency point of contact (POC) list for each type of incident within your organization.
The act of responding to an incident is often confusing and fast-paced; details can quite easily be overlooked in the fog of war. Teams need a pre-created communication plan to remember to involve the appropriate stakeholders and even partners. The communication plan should detail when to elevate the incident to higher-tier engineering staff, management, or executive leadership. The plan should also detail what should be communicated, by whom, and when, to outside stakeholders such as customers, government, law enforcement, and even the press when necessary. Finally, the communication plan should detail what information can be shared with different information-sharing services and social media (for example, if making announcements via Twitter, Facebook, and others).
From an internal response perspective, the communication plan should include POCs and alternatives for each IoT system in the organization, as well as POCs at suppliers, such as CSPs or other partners with whom you share IoT data. For example, if you support data-sharing APIs with analytics companies, it is possible that an IoT data breach could result in privacy-protected data unknowingly traversing those APIs, that is, unwanted onward transfer of PII.
All potential IRT members should learn the incident response plan. The plan should be integrated into the organization with executive buy-in and oversight. Roles and responsibilities should be established and exercises should be conducted that include engagement with third parties, such as CSPs. Training should be provided, not only on the technical aspects of the systems being supported, but also on the business and mission objectives of the systems.
Regular exercises should be conducted to validate not only the plan but the organization's efficiency and skill in executing it. These exercises will also help ensure that the incident response plan is kept up to date and that the staff involved are well versed and can act competently in a real incident. Finally, make sure that systems are fully documented. Knowing where sensitive data resides (and when it resides there) will substantially improve the reliability and confidence in findings from the incident response team.
Today's security information and event management (SIEM) systems are powerful tools that allow correlation between any type of observable event to flag possible incidents. These same systems can of course be configured to monitor the infrastructure that supports IoT devices; however, there are considerations that will affect the ability to maintain a sufficient degree of situational awareness across a deployed IoT system:
IoT systems are heavily dependent on cloud-hosted infrastructures
IoT systems may include highly constrained (that is, limited processing, storage, or communication ability) devices that often lack the ability to capture and forward event logs
These considerations drive a need to architect the monitoring infrastructure to capture instrumentation data from CSPs that support the system, as well as anything that is possible from the devices themselves.
Although there are limited options available in this regard, some small start-up companies are attempting to close the gap. Bastille (https://www.bastille.net/) is an example of a company that is working toward a comprehensive RF-monitoring solution for the IoT. Their product monitors the RF spectrum from 60 MHz to 6 GHz, covering all of the major IoT communication protocols. Most importantly, Bastille's wireless monitoring solution integrates with SIEM systems to allow proper situational awareness in a wireless, connected IoT deployment.
Routine scanning (along with SIEM event correlations) should also be employed, as well as cloud-based or edge-situated behavioral analytics (appropriate for device gateways, for example). Solutions such as Splunk are good for these types of activities.
Any discussion on the types of tools needed for IoT-specific digital forensics and incident response (DFIR) needs to begin with an understanding of the types of incidents that can be encountered by an organization. Again, tools such as Splunk are effective in looking for such patterns and indicators. Possible indicators may include the following:
We may see rogue sensor data injected to try and cause confusion within analytics systems
We may see attempts at using rogue IoT devices to exfiltrate data from enterprise networks in which they are situated
We may see attempts at compromising privacy controls to determine where individuals are located and what they are doing at any given time
We may see attempts at injecting malware into control systems by exploiting trust relationships between individuals and organizations, or between connected devices and control system networks
We may see attempts to disrupt business operations by launching denial of service attacks against IoT infrastructure
We may see attempts at causing damage through unauthorized access to IoT devices (physical or logical)
We may see attempts at compromising the confidentiality of data that flows across the entire IoT system by compromising device, gateway, and cloud-hosted cryptographic modules and key material
We may see attempts to take advantage of trusted autonomous transactions for financial gain
It becomes clear when responding to possible incidents in an IoT deployment that the ability to understand whether an IoT device has been compromised becomes vitally important. These devices often possess trusted credentials that support interactions with upstream infrastructure, and in many cases interactions with other devices. The compromise of a trusted relationship such as this can lead to horizontal, pivoted movement throughout a system, as well as the ability to access virtualized, supporting infrastructure in the data center/cloud. Absent sophisticated monitoring capabilities for relevant system endpoints, these movements can be accomplished very quietly.
This tells us that by the time an analyst detects an incident underway, the perpetrator may have already established widespread hooks into important subsystems throughout the enterprise. This understanding should drive the incident response process to focus heavily on immediately analyzing other devices, compute resources, and even other systems to determine whether they are still operating according to an established secure baseline. Unfortunately, today's tools for quickly determining the security status of thousands or even millions of connected devices during an incident response is lacking.
Although there are gaps in the tools available for an optimal IoT-based incident response action, there are still standard tools that teams should have available to them.
The first step toward being able to successfully analyze an incident is having good, current knowledge of the latest threats and indicators. Effective threat intelligence tools and processes are capabilities that responders should have in their arsenal. As enterprise IoT systems become increasingly attractive targets, these platforms will undoubtedly share indicators and defensive patterns with their membership. Some examples of today's threat-sharing platforms include:
DHS Automated Indicator Sharing (AIS) initiative: Today, this focuses on the energy and technology sectors (https://www.us-cert.gov/ais)
Alienvault Open Threat Exchange (OTX) (https://www.alienvault.com/open-threat-exchange)
IBM X-Force Exchange: This is a cloud-based threat intelligence service (http://www-03.ibm.com/software/products/en/xforce-exchange)
Information technology Information Sharing and Analysis Center (ISAC)
ISACs that lean more toward mission-specific threat intelligence exist as well. Examples include:
Industrial Control System (ICS) ISAC (http://ics-isac.org/blog/home/about/)
Electricity sector ISAC
Public transportation/surface transportation ISAC
Water ISAC
Once a possible incident is identified, additional analysis is performed to begin determining the scope and activity of the suspected compromise. Analysts should begin to assemble a timeline of activities. Keep this timeline handy and update it as new information is found. The timeline should include the presumed start time, and document any other significant times in the investigation. One can use audit/log data to correlate the activities that occurred. Something to consider in this regard is the need to keep and propagate an accurate source of time. Utilization of the network time protocol (NTP), when available for IoT systems, can help. The timeline is created and elaborated as the team identifies the actions that the adversary may have performed.
Analysis can also entail activities that include attempts at attribution (that is, identifying who is attacking us). Tools that are useful for these activities would usually include the WHOIS databases from the various Internet registries that provide the ability to look up owners of IP address blocks. Unfortunately, there are easy-to-use methods that can be employed against IoT and any other IT systems, which provide anonymity for attackers. If one inserts a rogue IoT device into a network to transmit bogus readings, identifying the IP address of the device does little to help the analysis, because the device rides on the victim network. Even worse, the device may not have an IP address. Attacks from outside the organization can make use of command and control servers, botnets and just about any compromised host, VPN, Tor network, or some combination of mechanisms to mask the true source and source address of the attacker. Dynamic pivoting and rapid clearing of one's tracks is the norm whether it's a nation state, criminal organization (or both), or script kiddie that is attacking. The latter just may not be quite as skilled in how to thwart the forensics capabilities of their adversary.
A more thorough examination of the compromised device is in order to try and determine the characteristics of the attacker based on the files loaded, or even lifting fingerprints from the device itself. In addition, IoT Incident response may include forensic analysis of device gateways—gateways may be located at the network edge, or centrally within a CSP. Typically, a response team would capture images of the compromised systems for offline evaluation. This is where infrastructure tools that can be adapted and applied to IoT systems can become very useful.
Comparison between good behavioral and security baselines and compromised systems is valuable for identifying malicious artifacts and aiding in investigations. Tools that support the offline configuration of IoT devices can be used for this. For example, Docker images, when used to deploy IoT devices, can provide the good baseline example needed for a comparison.
If authentication services are set up for IoT device authentication, the logs from those authentication servers should also provide a valuable data source for an investigation. One should be diligent in looking for failed logins to systems and devices, as well as suspicious successful logins and authorizations from abnormal source IPs, times of day, and so on. Enterprise SIEM correlation rules will provide this functionality based on the use of threat intelligence feeds and reputational databases.
Another aspect of an investigation is determining what data has actually been compromised. Identifying exfiltrated data is the first step, but then you also must understand whether that exfiltrated data has been protected (at rest) using strong cryptographic measures. Exfiltration of gigabytes of ciphertext doesn't benefit the attacker unless he also acquires the cryptographic private key needed for the decryption. If your organization is unable to know the state of data (plaintext or ciphertext) at every point in the system, every host, every network, application, gateway, and so on, you will have a difficult time ascertaining the extent of the data breach. An accurate characterization of the data breach is crucial for informing the investigation as to whether data breach notifications need to be made, as per legal and regulatory mandates.
Forensic tools are also needed to help piece together information on the attack. There are a number of tools available that can be leveraged, such as:
GRR
Bit9
Mastiff
Encase
FTK
Norman Shark G2
Cuckoo Sandbox
Although these tools are often used in terms of a traditional forensics effort, they have some gaps when dealing with actual IoT devices. Researchers (Oriwoh, et al. Internet of Things Forensics: Challenges and Approaches,https://www.researchgate.net/publication/259332114_Internet_of_Things_Forensics_Challenges_and_Approaches) outline a Next Best Thing approach to IoT forensics evidence collection. They argue convincingly that often the devices themselves will not provide sufficiently useful information and that instead one must look to the devices and servers to which data is sent within a system. For example, an MQTT client may not actually store any data, but instead may automatically send data to upstream MQTT servers. In this case, the server will most likely provide the next best thing to analyze.
In cases where the devices themselves may yield critical data in the investigation, IoT devices may need to be reversed to extract firmware for analysis. Given the enormous variety of potential IoT devices, the specific tools and processes will vary. This section provides some example methods of extracting and analyzing firmware images of devices that may have been compromised or were otherwise involved in an incident and may yet yield clues by analyzing memory. In practice, organizations may need to outsource these activities to a reputable security firm; if this is the case, find firms that have a firm background in forensics and have a good working knowledge of, and policies regarding, chain of custody and chain of evidence (should the data become necessary in courts of law).
Embedded devices can be challenging to analyze. Many commercial vendors provide USB interfaces to memory, but frequently restrict what areas of memory can be accessed. If the embedded device does support a *nix type of OS kernel, and the analyst is able to get a command line to the device, a simple dd command may be all that is necessary to extract the device's image, specific volumes, partitions, or master boot record to a remote location.
Absent a convenient interface, you'll likely need to extract memory directly, and that's typically through a JTAG or UART interface. In many cases, security-conscious vendors go to great lengths to mask or disable JTAG interfaces. To get physical access, it might be necessary to cut, grind or find some other method of removing a physical layer from the connector. If the JTAG test access ports are accessible and there's a JTAG connector already there, tools such as Open On-Chip Debugger (http://openocd.org/) or UrJTAG (http://urjtag.org/) can be useful in communicating with flash chips, CPUs and other embedded architectures and memory types. It may also be necessary to solder a connector to the ports to gain access.
Absent an accessible JTAG or UART interface, more advanced chip-off (also called chip de-capping) techniques may be in order to extract data. Chip-off forensics is generally destructive in nature, because the analyst has to physically remove the chip by de-soldering or chemically removing adhesives, whatever the manufacturer used to attach the chip in the first place. Once removed, chip programmers can be used to extract the binary data from the memory type that was employed. Chip-off is generally an advanced process performed by specifically outfitted laboratories.
Whatever procedure was used to access and extract the full memory of the device, the next step involves the analysis of the binary. Depending on the chip or architecture in question, a number of tools are available for performing raw binary analysis. Examples include:
Binwalk (http://binwalk.org): Very useful for scanning a binary for specific signatures related to files, filesystems, and so on. Once identified, files can be extracted for downstream inspection and analysis.
IDA-Pro (https://www.hex-rays.com/products/ida/index.shtml): Used by many security researchers (and anyone looking to find and exploit vulnerabilities in well-known OS architectures), IDA is a powerful disassembly and debugging tool that can target a variety of operating systems for reverse engineering.
Firmwalker (https://github.com/craigz28/firmwalker): A script-based tool for searching files and filesystems in firmware.
Know how and when to perform incident escalation. This is where good threat intelligence becomes especially valuable. Compromises are usually not single events, but rather small pieces of a larger campaign. As new information is learned, the methods of detection and response need to escalate and adapt to handle the incident.
Finally, something to consider is that cybersecurity staff deploying IoT systems in industries such as transportation and utilities should keep an eye on national and international threats above and beyond the local organization. This is the normal course of business for US and other national intelligence-related agencies. Nation-state, terrorist, organized crime and other international-related security considerations can have direct bearing on IoT systems in terms of nationalistic or criminal attack motivations, desired impacts, and the possible actors who may carry out the actions. This type of awareness tends to be more applicable to critical energy, utilities, and transportation infrastructure, but targeted attacks can come from anywhere and target just about anything.
There is a significant need for information to be shared between operational and technology teams even within organizations. In terms of public/private partnerships that facilitate such information sharing, one is InfraGard:
"InfraGard is a partnership between the FBI and the private sector. It is an association of persons who represent businesses, academic institutions, state and local law enforcement agencies, and other participants dedicated to sharing information and intelligence to prevent hostile acts against the U.S."
Source: https://www.infragard.org/
Another valuable information-sharing resource is the High Tech Crime Investigation Association (HTCIA). HTCIA is a non-profit that hosts yearly international conferences and promotes partnerships with public and private entities. Regional chapters exist in many parts of the world.
Other more sensitive partnerships, such as the US Department of Homeland Security's (DHS) Enhanced Cybersecurity Services (ECS), exist between government and industry to improve threat intelligence and sharing across commercial and government boundaries. These types of programs typically invoke access to classified information outside the realm of most non-government contracting organizations today. We may very well see such programs undergo significant enhancement over the years to better accommodate IoT-related threat intelligence, given the large government and military interest in IoT-enabled systems and CPS.
One of the most important questions to answer during an incident response is the level at which systems can be taken offline without disrupting critical business/mission processes. Often within IoT systems, the process of swapping out a new device for an old device is relatively trivial; this needs to be taken into account when determining the right course of action. This is not always the case, of course, but if it is feasible to quickly swap out infected devices then that path should be taken.
In any case, compromised devices should be removed from the operational network as quickly as possible. The state of those devices should be strictly preserved so that the devices can be further analyzed using traditional forensics tools and processes. Even here though, there are challenges, as some constrained devices may overwrite data important to the analysis (https://www.cscan.org/openaccess/?id=231).
More complicated issues arise when an IoT gateway has been compromised. Organizations should keep on hand preconfigured spare gateways ready to be deployed should a gateway be compromised. If possible, a re-flashing of all IoT devices may also be in order if the gateway is compromised. Today, this can be quite a challenge, unfortunately. Automated software/firmware provisioning services (not unlike the Microsoft Windows Server Update Services (WSUS) application) represent an enormous gap in today's IoT. The ability to patch any device, anywhere, over the wire or over the air, is definitely needed, and it's a capability that needs to function regardless of who owns a device and whether or how it is transferred to other owners, other cloud-based provider services, and so on.
Infrastructure compute platforms must also be considered. Remove servers or server images (cloud) from the operational network and replace them with new, baselined images to keep services up and running (much easier and faster in a cloud deployment). An incident response plan should include each of the discrete steps to do this. If you utilize a cloud management interface, include the specific management URI at which to perform the action, the specific steps (button presses), everything. Determine by what means IoT images in your system can be acquired. Isolate the infected images to begin forensics analysis, where you will attempt to identify the malware and the vulnerability/vulnerabilities that the malware is attempting to exploit.
One thing to note is that it is always desirable to track what an adversary is doing on your network. If the required resources are available, it would be beneficial to set up logical rules gateway devices that, upon command or pattern, segment off compromised IoT devices to make an attacker or malware unaware of the discovery. Dynamically reconfiguring these devices to talk to a parallel dummy infrastructure (either at the gateway or in the cloud) can allow for closer observation and study of the actions being taken by the malicious actor(s). Alternatively, you can re-route traffic for the affected device(s) to a sandbox environment for further analysis.
Sometimes called recovery, this phase includes steps for performing root cause analysis, after-incident forensics, privacy health checks, and a determination of which PII items, if any, were compromised.
Root cause analysis should be used to understand exactly how the defensive posture failed and determine what steps should be taken in order to keep the incident from reoccurring. Active scanning of related IoT devices and systems should also occur post-incident, to proactively hunt for the same or similar intruders.
It is important to employ retrospective meetings for sharing lessons learned among team members. This can be explicitly stated in your incident response plan by calling for one-day, one-week, and one-month follow-up meetings with the entire IR team. Over the course of that time, many details from follow-up forensics and analysis will shed new light on the source of the incident, its actors, the vulnerabilities exploited, and, equally important, how well your team did in the response. Retrospective meetings should be handled like group therapy—no pointing fingers, blame, or harsh criticism of individuals or processes, just an honest assessment of 1) what happened, 2) how it happened, 3) how well or poorly your response went (and why), and 4) how you can respond better next time. The retrospectives should have a moderator to ensure that things flow well, time is not wasted, and that the most salient lessons learned are captured.
Finally, all of the lessons learned should be evaluated for:
Necessary changes to the IRP plan
Necessary changes to the network access control (NAC) plan
Any need for new tools, resources, or training required to safeguard the enterprise
Any deficiencies in the cloud service provider's IR plan that would have helped in the incident response (indeed, you may need to determine if you need to migrate to a different cloud provider, or add additional services with your current one)
This chapter provided guidance on building, maintaining, and executing an incident response plan. We defined IoT incident response and management, and discussed the unique details related to executing IoT incident response activities.