Mitigating IoT Privacy Concerns
This chapter provides the reader with an understanding of privacy principles and concerns introduced by the IoT through implementation and deployment.
An exercise and guidance in creating a privacy impact assessment (PIA) is also provided. PIAs address the causes and fallout of leaking privacy protected information (PPI). We will discuss privacy by design (PbD) approaches for integrating privacy controls within the IoT engineering process. The goal of PbD is to integrate privacy controls (in technology and processes) throughout the IoT engineering lifecycle to enhance end-to-end security, visibility, transparency, and respect for user privacy. Finally, we will discuss recommendations for instituting privacy engineering activities within your organization.
This chapter examines privacy in our IoT-connected world in the following sections:
Privacy challenges introduced by the IoT
Guide to performing an IoT PIA
PbD principles
Privacy engineering recommendations
As your family sits down after dinner and a long day of work, one of the children starts up a conversation with her new connected play doll, while the other begins to watch a movie on the new smart television. The smart thermostat is keeping the living area a steady 22 degrees Celsius, while diverting energy from the rooms that aren't being used at the moment. Father is making use of the home computer's voice control features, while Mother is installing new smart light bulbs that can change color on command or based on variations in the home environment. In the background, the smart refrigerator is transmitting an order for the next-day delivery of groceries.
This setting tells a great story of the consumer Internet of Things in that there are exciting new capabilities and convenience. It also begins to make clear the soon-to-be hyper-connected nature of our homes and environments. If we start to examine these new smart products, we can begin to see the concern surrounding privacy within the IoT.
The privacy challenges with the Internet of Things are enormous, given the gargantuan quantities of data collected, distributed, stored and, ahem, sold every day. Pundits will argue that privacy is dead today. They argue that consumers' willingness to eagerly click through so-called end user privacy agreements compromises their privacy with barely a notion as to what they just agreed to. The pundits are not far off, as privacy concerns are something of a moving target given the fickle nature of consumer sentiment.
Our ability to grasp and find ways of preserving privacy with the IoT represents a monumental challenge. The increased volume and types of data able to be collected and distilled through technical and business analytics systems can produce frighteningly detailed and accurate profiles of end users. Even if the end user carefully reads and agrees to their end user privacy agreement, they are unlikely to imagine the downstream, multiplicative, compromising effect of accepting two, three, or four of them, to say nothing of 30 or 40 privacy agreements. While an improved targeted advertising experience may have been the superficial rationale for agreeing to privacy agreements, it is no understatement that advertisers are not the only entities procuring this data. Governments, organized crime syndicates, potential stalkers, and others can either directly or indirectly access the information to perform sophisticated analytical queries that ascertain patterns about end users. Combined with other public data sources, data mining is a powerful and dangerous tool. Privacy laws have not kept up with the data science that thwarts them.
Privacy protection is a challenge no matter the organization or industry that needs to protect it. Communications within a privacy-conscious and privacy-protecting organization are vital to ensuring that customers' interests are addressed. Later in this chapter, we identify corporate departments and individual qualifications needed to address privacy policies and privacy engineering.
Some privacy challenges are unique to the IoT, but not all. One of the primary differences between IoT and traditional IT privacy is the pervasive capture and sharing of sensor-based data, whether medical, home energy, transportation-related, and so on. This data may be authorized or may not. Systems must be designed to make determinations as to whether that authorization exists for the storage and sharing of data that is collected.
Take, for example, video captured by cameras strewn throughout a smart city. These cameras may be set up to support local law enforcement efforts to reduce crime; however, they capture images and video of everyone in their field of view. These people caught on film have not given their consent to be video-recorded.
As such, policies must exist that:
Notify people coming into view that they are being recorded
Determine what can be done with the video captured (for example, do people need to be blurred in images that are published?)
The amount of data actively or passively generated by (or for) a single individual is already large. By 2020, the amount of data generated by each of us will increase dramatically. If we consider that our wearable devices, our vehicles, our homes, and even our televisions are constantly collecting and transmitting data, it becomes obvious that trying to restrict the types and amounts of data shared with others is challenging to say the least.
Now, if we consider the lifecycle of data, we must be aware of where data is collected, where it is sent, and how. The purposes for collecting data are diverse. Some smart machine vendors will lease equipment to an organization and collect data on the usage of that equipment for billing purposes. The usage data may include time of day, duty cycle (usage patterns), number and type of operations performed, and who was operating the machine. The data will likely be transmitted through a customer organization's firewall to some Internet-based service application that ingests and processes the information. Organizations in this position should consider researching exactly what data is transmitted in addition to the usage information, and ascertain whether any of the information is shared with third parties.
Data associated with wearables is frequently sent to applications in the cloud for storage and analysis. Such data is already being used to support corporate wellness and similar programs, the implication being that someone other than the device manufacturer or user is collecting and storing the data. In the future, this data may also be passed on to healthcare providers. Will the healthcare providers pass that data on to insurance companies as well? Are there regulations in the works that restrict the ability of insurance companies to make use of data that has not been explicitly shared by the originator?
Smart home data can be collected by many different devices and sent to many different places. A smart meter, for example, may transmit data to a gateway that then relays it to the utility company for billing purposes. Emergent smart grid features such as demand response will enable the smart meter to collect and forward information from the home's individual appliances that consume electricity from the power grid. Absent any privacy protections, an eavesdropper could theoretically begin to piece together a puzzle that shows when certain appliances are used within a home, and whether homeowners are home or not. The merging of electronic data corresponding to physical-world state and events is a serious concern related to privacy in the IoT.
A striking report by Open Effect (https://openeffect.ca/reports/Every_Step_You_Fake.pdf) documented the metadata that is collected by today's consumer wearable devices. In one of the cases they explored, the researchers analyzed the Bluetooth discovery features of different manufacturers' wearable products. The researchers attempted to determine whether the vendors had enabled new privacy features that were designed into the Bluetooth 4.2 specification. They found that only one of the manufacturers (Apple) had implemented them, leaving open the possibility of the exploitation of the static media access control (MAC) address for persistent tracking of a person wearing one of the products. Absent the new privacy feature, the MAC addresses never change, creating an opportunity for adversarial tracking of the devices people are wearing. Frequent updates to a device's MAC address limit an adversary's ability to track a device in space and time as its owner goes about their day.
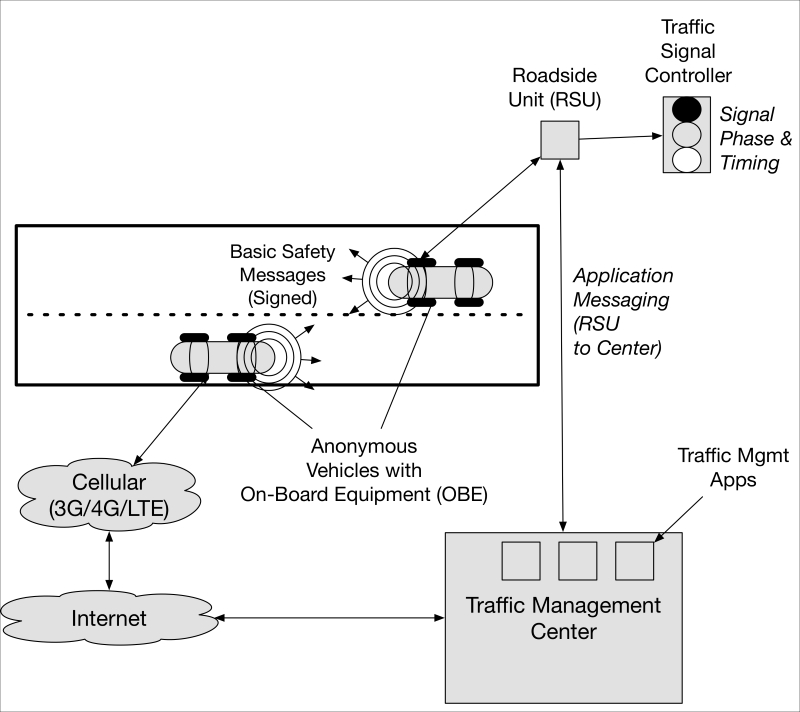
Another worthy example of the need to rethink privacy for the IoT comes from the connected vehicle market. Just as with the wearables discussed previously, the ability to track someone's vehicle persistently is a cause for concern.
A problem arises, however, when we look at the need to digitally sign all messages transmitted by a connected vehicle. Adding digital signatures to messages such as basic safety messages (BSMs) or infrastructure-generated messages (for example, traffic signal controller signal phase and timing (SPaT) messages) is essential to ensure public safety and the performance of our surface transportation systems. Messages must be integrity protected and verified to originate from trusted sources. In some cases, they must also be confidentiality protected. But privacy? That's needed, too. The transportation industry is developing interesting privacy solutions for connected vehicles:
Privacy in connected vehicles and infrastructure
For example, when a connected vehicle transmits a message, there is concern that using the same credentials to sign messages over a period of time could expose the vehicle and owner to persistent tracking. To combat this, security engineers have specified that vehicles will be provisioned with certificates that:
Have short lifespans
Are provisioned in batches to allow a pool of credentials to be used for signing operations
In the connected vehicle environment, vehicles will be provisioned with a large pool of constantly rotated pseudonym certificates to sign messages transmitted by on-board equipment (OBE) devices within the vehicle. This pool of certificates may only be valid for a week, at which point another batch will take effect for the next time period. This reduces the ability to track the location of a vehicle throughout a day, week or any larger time period based on the certificates it has attached to its own transmissions.
Ironically, however, a growing number of transportation departments are beginning to take advantage of widespread vehicle and mobile device Bluetooth by deploying Bluetooth probes along congested freeway and arterial roadways. Some traffic agencies use the probes to measure the time it takes for a passing Bluetooth device (indicated by its MAC address) to traverse a given distance between roadside mounted probes. This provides data needed for adaptive traffic system control (for example, dynamic or staged signal timing patterns). Unless traffic agencies are careful and wipe any short- or long-term collection of Bluetooth MAC addresses, correlative data analytics can be used potentially to discern individual vehicle (or its owner) movement in a region. Increased use of alternating Bluetooth MAC addresses may render useless future Bluetooth probe systems and their use by traffic management agencies.
Continuing with the connected vehicle example, we can also see that infrastructure operators should not be able to map provisioned certificates to the vehicles either. This requires changes to the traditional PKI security design, historically engineered to provide certificates that specifically identify and authenticate individuals and organizations (for example, for identity and access management) through X.509 distinguished name, organization, domain, and other attribute types. In the connected vehicle area, the PKI that will provision credentials to vehicles in the United States is known as the security credential management system (SCMS) and is currently being constructed for various connected vehicle pilot deployments around the country. The SCMS has built-in privacy protections ranging from the design of the pseudonym IEEE 1609.2 certificate to internal organizational separations aimed at thwarting insider PKI attacks on drivers' privacy.
One example of SCMS privacy protections is the introduction of a gateway component known as a location obscurer proxy (LOP). The LOP is a proxy gateway that vehicle OBEs can connect to instead of connecting directly to a registration authority (RA). This process, properly implemented with request shuffling logic, would help thwart an insider at the SCMS attempting to locate the network or geographic source of the requests (https://www.wpi.edu/Images/CMS/Cybersecurity/Andre_V2X_WPI.PDF).
The potential for a dystopian society where everything that anyone does is monitored is often invoked as a potential future aided by the IoT. When we bundle things like drones (aka SUAS) into the conversation, the concerns are validated. Drones with remarkably high resolution cameras and a variety of other pervasive sensors all raise privacy concerns, therefore it is clear there is much work to be done to ensure that drone operators are not sued due to lack of clear guidance on what data can be collected, how, and what the treatment of the data needs to address.
To address these new surveillance methods, new legislation related to the collection of imagery and other data by these platforms may be needed to provide rules, and penalties in instances where those rules are broken. For example, even if a drone is not directly overflying a private or otherwise controlled property, its camera may view at slant range angles into private property due to its high vantage point and zoom capabilities. Laws may need to be established that require immediate or 'as soon as practical' geospatial scrubbing and filtering of raw imagery according to defined, private-property-aligned geofences. Pixel-based georeferencing of images is already in today's capabilities and is used in a variety of image post-processing functions related to drone-based photogrammetry, production of orthomosaics, 3D models, and other geospatial products. Broad pixel-based georeferencing within video frames may not be far off. Such functionality would provide for consent-based rules to be established so that no drone operator could preserve or post in public online forums imagery containing any private property regions beyond a specific per-pixel resolution. Without such technical and policy controls, there is little other than strong penalties or lawsuits to prevent peeping Toms from peering into backyards and posting their results on YouTube. Operators need specificity in rules so that companies can build compliance solutions.
New technologies that allow law-abiding collectors of information to respect the wishes of citizens who want their privacy protected are needed in our sensor-rich Internet of Things.
An IoT PIA is crucial for understanding how IoT devices, within the context of a larger system or system-of-systems, may impact end user privacy. This section will provide you with a reference example of how to perform a PIA for your own deployment, by walking through a hypothetical IoT system PIA. Since consumer privacy is such a sensitive topic, we provide a consumer-level PIA for a connected toy.
Privacy impact assessments are necessary to provide as complete a risk analysis as possible. Beyond basic safety and security tenets, unmitigated privacy losses can have substantial impacts and result in severe financial or legal consequences to a manufacturer or operator of IT and IoT systems. For example, consider a child's toy fitted with Wi-Fi capabilities, smart phone management, and connectivity to backend system servers. Assume the toy possesses a microphone and speaker, along with voice capture and recognition capabilities. Now consider the security features of the device, its storage of sensitive authentication parameters, and other attributes necessary for secure communication to backend systems. If a device were physically or logically hacked, would it expose any common or default security parameters that could be used to compromise other toys from the same manufacturer? Are the communications adequately protected in the first place through encryption, authentication, and integrity controls? Should they be? What is the nature of the data and what could it possibly contain? Is user data aggregated in backend systems for any analytics processing? Is the overall security of the infrastructure and development process sufficient to protect consumers?
These questions need to be asked in the context of a privacy impact assessment. Questions must address the severity of impact from a breach of information or misuse of the information once it enters the device and backend systems. For example, might it be possible to capture the child's audio commands and hear names and other private information included? Could the traffic be geolocated by an adversary, potentially disclosing the location of the child (for example, their address)? If so, impacts could possibly include the malicious stalking of the child or family members. These types of problems in the IoT have precedence http://fortune.com/2015/12/04/hello-barbie-hack/) and it is therefore vital that a complete PIA be performed to understand the user base, types of privacy impact, their severity, probability, and other factors to gauge overall risk.
Identified privacy risks need to then be factored into the privacy engineering process described later. While the example we provide is hypothetical, it is analogous to one of the hacks elucidated by security researcher Marcus Richerson at RSA 2016 (https://www.rsaconference.com/writable/presentations/file_upload/sbx1-r08-barbie-vs-the-atm-lock.pdf).
This section will utilize a hypothetical talking doll example and make reference to the following system architecture. The architecture will be needed to visualize the flow and storage of private information between the IoT endpoint (the doll), a smartphone, and connected online services. The private information, people, devices, and systems involved will be explored in more detail later, when we discuss privacy by design and the security properties inherent in it:
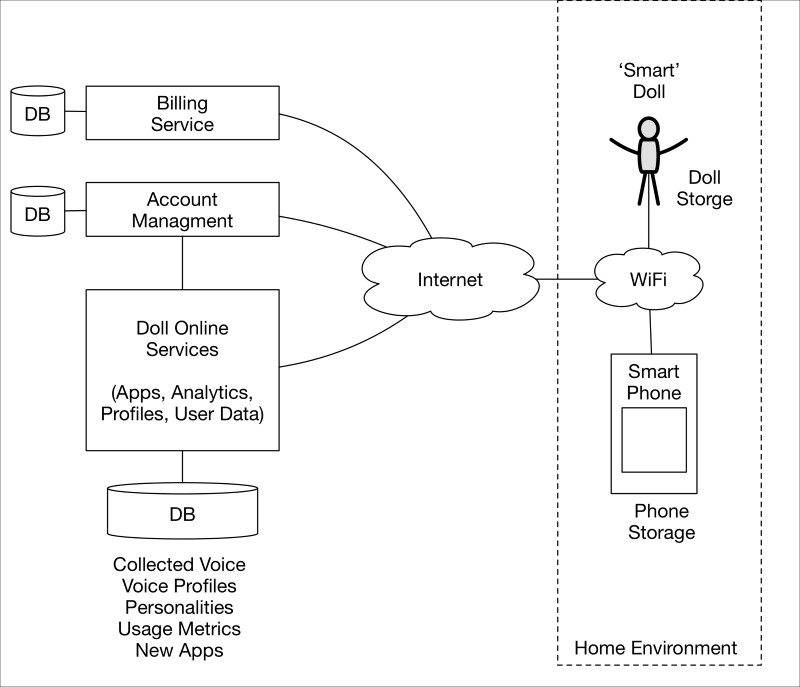
Talking doll IoT system reference architecture
Authorities deal with the entities that create and enforce laws and regulations that may impact an organization's collection and use of private information. In the case of the talking doll example, a variety of laws may be at work. For example, the European Union Article 33 rules, the US Children's Online Privacy Protection Act (COPPA), and others may come into play. Under the authorities question, an IoT organization should identify all legal authorities, and the applicable laws and regulations each imposes on the operation. Authorities may also have the ability to issue waivers and allow certain information collection and use based on certain conditions. These should be identified as well.
If your IoT organization, like many IT operations, is operating across international borders, then your PIA should also raise the issue of how data can and might be treated outside of your country. For example, if more lax rules are applied overseas, some data may be more vulnerable to foreign government inspection, regardless of your desired privacy policy in your own country. Or, the foreign rules may be stricter than those mandated by your nation, possibly preventing you from using certain overseas data centers. The process of privacy by design should address the geographical architecture early and ensure that the geographical design does not violate the privacy needed for your deployment.
The lifecycle and scope of information pertinent to an IoT device can be narrowly defined or quite broad. In a PIA, one of the first activities is to identify information that will originate, terminate in or pass through the IoT-enabled system. At this point, one should create tables for the different lifecycle phases and the data relevant to each. In addition, it is useful to use at least three different first order ratings to give each information type based on sensitivity. For simplicity, in the following examples we use:
Not sensitive
Moderately sensitive
Very sensitive
Other rating types can be used depending on your organization, industry, or any regulatory requirements. Keep in mind that some types of data, even if marked not sensitive or moderately sensitive, can become very sensitive when grouped together. Such data aggregation risks need to be evaluated whenever pulling together data within application processing or storage environments. The eventual security controls (for example, encryption) applied to aggregated datasets may be higher than what may initially be determined for small sets or single data types.
In the case of the talking doll, once the doll has left the manufacturing environment, it is shipped to wholesalers or retailers awaiting purchase by end users. No end user personally identifiable information (PII) has yet entered the system. Once purchased by a parent, the doll is taken home to be bootstrapped, connected to a newly created account, and connected to smartphone applications. Now, PII enters the picture.
Assuming there is a subscription service to download new apps to the doll, we now begin to delineate the PII. The following hypothetical data elements and the lifecycle phases to which they apply are listed to illustrate the data identification process. Each is listed and described; for each the source of the data (application + device) and the consumers of the data are identified so that we understand the endpoint that will have varying degrees of access to the information.
The following example information is identified as being created or consumed during the creation of the doll owner's account:
|
Account creation |
|||
|
Parameter |
Description/Sensitivity |
Origin |
Consumer/User(s) |
|
Login |
User identifier (not sensitive) |
Created by user |
User Application server Billing server Smart phone app |
|
Password |
User password (high sensitivity) |
Created by user (minimum password length/quality enforced) |
User App server Billing server Smart phone app |
|
Name, address, phone number |
Account holder's (doll owner's) name, address, and phone number |
Doll owner |
Application server Billing server |
|
Age |
Age of child using doll (not sensitive) |
Doll owner |
Application server |
|
Gender |
Account holder's or doll owner's gender (not sensitive) |
Doll owner |
Application server |
|
Account number |
Unique account number for this doll owner |
Application server |
Doll owner Application server Smartphone app Billing server |
The following example information is identified as being created or consumed during the creation of the doll owner's subscription:
|
Subscription creation |
|||
|
Parameter |
Description/Sensitivity |
Origin |
Consumer |
|
Doll type and serial number |
Doll information (low sensitivity) |
Packaging |
Application server (for subscription profile) |
|
Subscription package |
Subscription type and term, expiration, and so on (low sensitivity) |
Doll owner selected via web page |
Application server |
|
Name |
First and last name (high sensitivity when combined with financial information) |
Doll owner |
Billing server |
|
Address |
Street, city, state, country (moderate sensitivity) |
Doll owner |
Billing server and application server |
|
Credit card information |
Credit card number, CVV, expiration date (high sensitivity) |
Doll owner |
Billing server |
|
Phone number |
Phone number of doll owner (moderate sensitivity) |
Doll owner |
Billing server and application server |
The following example information is identified as being created or consumed during the pairing of the downloaded smartphone application that will connect with the talking doll and backend application server:
|
Attachment to smartphone application |
|||
|
Parameter |
Description/Sensitivity |
Origin |
Consumer(s) |
|
Account number |
Account number that was created by the account server upon doll owner account creation (moderate sensitivity) |
Account server via doll owner |
Smartphone application Application server |
|
Doll serial number |
Unique identifier for the doll (not sensitive) |
Doll's packaging from manufacturer |
Doll owner Application server Smartphone app |
|
Doll settings and configs |
Day-to-day settings and configurations made on the doll via the smartphone application or web client not sensitive, or moderate sensitivity (depending on attributes) |
Doll owner |
Doll Application server |
The following example information is identified as being created or consumed during the normal daily use of the talking doll:
|
Daily usage |
|||
|
Parameter |
Description/Sensitivity |
Origin |
Consumer |
|
Doll speech profiles |
Downloadable speech patterns and behaviors (not sensitive) |
Application server |
Doll user |
|
Doll microphone data (voice recordings) |
Recorded voice communication with doll (high sensitivity) |
Doll and environment |
Application server and doll owner via smartphone |
|
Transcribed Microphone Data |
Derived voice-to-text transcriptions of voice communication with doll (high sensitivity) |
Application server (transcription engine) |
Application server and doll owner via smartphone |
Acceptable use policies need to be established in accordance with national, local, and industry regulation, as applicable.
Use of collected information refers to how different entities (that are being given access to the IoT data) will use data collected from different sources, in accordance with a privacy policy. In the case of the talking doll, the doll manufacturer itself owns and operates the Internet services that interact with the doll and collect its owner's and user's information. Therefore, it alone will be the collector of information that may be useful for:
Viewing the data
Studies or analytics performed on the data for research purposes
Analysis of the data for marketing purposes
Reporting on the data to the end user
Selling or onward transfer of the data
Distillation and onward transfer of any processed metadata that originated with the user's raw data
Ideally, the manufacturer would not provide the data (or metadata) to any third party; the sole participants in using the data would be the doll owner and the manufacturer. The doll is configured by its owner, collects voice data from its environment, has its voice data converted to text for keyword interpretation by the manufacturer's algorithms, and provides usage history, voice files, and application updates to the doll owner.
Smart devices rely upon many parties, however. In addition to the doll manufacturer, there are suppliers that support various functions and benefit from analyzing portions of the data. In cases where data or transcribed data is sent to third parties, agreements between each party must be in force to ensure the third parties agree to not pass on or make the data available for other than agreed-upon uses.
Security is privacy's step-sibling and a critical element of realizing privacy by design. Privacy is not achievable without data, communications, applications, device, and system level security controls. The security primitives of confidentiality (encryption), integrity, authentication, non-repudiation, and data availability need to be implemented to support the overarching privacy goals for the deployment.
In order to specify the privacy-related security controls, the privacy data needs to be mapped to the security controls and security parameters necessary for protection. It is useful at this stage to identify all endpoints in the architecture in which the PII is:
Originated
Transmitted through
Processed
Stored
Each PII data element then needs to be mapped to a relevant security control that is either implemented or satisfied by endpoints that touch it. For example, credit card information may originate on either the doll owner's home computer or mobile device web browser and be sent to the billing service application. Assigning the security control of confidentiality, integrity, and server authentication, we will likely use the common HTTPS (HTTP over TLS) protocol to maintain the encryption, integrity, and server authentication while transmitting the credit card information from the end user.
Once a complete picture is developed for the security-in-transit protections of all PII throughout the system, security needs to focus on the protection of data-at-rest. Data-at-rest protection of PII will focus on other traditional IT security controls, such as database encryption, access controls between web servers, databases, personnel access control, physical protection of assets, separation of duties, and so on.
Notice pertains to the notification given to the end user(s) on what scope of information is collected, any consent that the user must provide, and the user's right to decline to provide the information. Notice is almost exclusively handled in privacy policies to which the end user must agree prior to obtaining services.
In the case of our talking doll, the notice is provided in two places:
Printed product instruction sheet (provided within the packaging)
User privacy agreement presented by the doll's application server upon account creation
Data retention addresses how the service stores and retains any data from the device or device's user(s). A data retention policy should be summarized in the overall privacy policy, and should clearly indicate:
What data is stored/collected and archived
When and how the data will be pushed or pulled from the device or mobile application
When and how data is destroyed
Any metadata or derived information that may be stored (aside from the IoT raw data)
How long the information will be stored (both during and after the life of the account to which it pertains)
If any controls/services are available to the end user to scrub any data they generate
Any special mechanisms for data handling in the event of legal issues or law enforcement requests
In our talking doll example, the data in question is the PII identified previously, particularly the microphone-recorded voice, transcriptions, metadata associated with the recorded information, and subscription information. The sensitivity of data recorded within one's home, whether a child's musings, captured dialog between parent and child, or a group of children at play, can be exceedingly sensitive (indicating names, ages, location, indication of who is at home, and so on). The type of information the system is collecting can amount to what is available using classic eavesdropping and spying; the sensitivity of the information and its potential for misuse is enormous. Clearly, data ownership belongs to the doll owner(s); the company whose servers pick up, process, and record the data needs to be explicitly clear on how the data is retained or not.
Information sharing, also called onward transfer in the US and European Safe Harbor privacy principle, refers to the scope of sharing information within the enterprise that collects it, and with organizations external to it. It is common in business enterprises to share or sell information to other entities (https://en.wikipedia.org/wiki/International_Safe_Harbor_Privacy_Principles).
In general, the PIA should list and describe (Toward a Privacy Impact Assessment (PIA) Companion to the CIS Critical Security Controls; Center for Internet Security, 2015) the following:
Organizations with whom information is shared, and what types of agreement either exist or need to be formed between them. Agreements can take the form of contracted adherence to general policies and service level agreements (SLAs).
Types of information that are transferred to each external organization.
Privacy risks of transferring the listed information (for example, aggregation risks or risks of combining with publicly available sources of information).
How sharing is in alignment with the established data use and collection policy.
Note that at the time of writing this, the Safe Harbor agreement between the US and Europe remains invalidated by the Court of Justice of the European Union (CJEU), thanks to a legal complaint that ensued from Edward Snowden's leaks concerning NSA spying. Issues related to data residency—where cloud-enabled data centers actually store data—pose additional complications for US corporations (http://curia.europa.eu/jcms/upload/docs/application/pdf/2015-10/cp150117en.pdf).
Redress addresses the policies and procedures for end users to seek redress for possible violations and disclosure of their sensitive information. For example, if the talking doll owner starts receiving phone messages indicating that an unwanted person has somehow eavesdropped in on the child's conversation with the doll, he/she should have a process to contact the manufacturer and alert them to the problem. The data loss could be from non-adherence to the company's privacy protections (for example, an insider threat) or a basic security flaw in the system's design or operation.
In addition to actual privacy losses, redress should also include provisions for addressing end users' complaints and concerns about documented and disclosed policies affecting their data. In addition, procedures should also be available for end users to voice concerns about how their data could be used for other purposes without their knowledge.
Each of the policies and procedures for redress should be checked when performing the PIA. They will need to be periodically re-evaluated and updated when changes are made either to policies, the data types collected, or the privacy controls implemented.
Auditing and accountability checks within a PIA are to ascertain what safeguards and security controls are needed, and when, from the following perspectives:
Insider and third-party auditing addresses what organizations and/or agencies provide oversight
Forensics
Technical detection of information (or information system) misuse (for example, a host auditing tool detects database access and a large query not emanating from the application server)
Security awareness, training processes, and supporting policies for those with direct or indirect access to the PII
Modifications to information sharing processes, organizations with whom information is shared, and approval of any changes to policy (for example, if the doll manufacturer were to begin selling e-mail addresses and doll users' demographics to third-party marketers)
Asking pointed questions about each of the preceding points, and determining the sufficiency and detail of the answers, is necessary in the PIA.
Today's IoT-enabled businesses and infrastructures can no longer afford to incrementally bolt on privacy enforcement mechanisms as a reactionary afterthought. That is why privacy engineering and design has evolved as a necessity and gained significant traction in recent years. This section discusses privacy design and engineering related to the Internet of Things.
Privacy engineering is driven completely by policy. It ensures that:
Policy leads to privacy-related requirements and controls
Underlying system-level design, interfaces, security patterns, and business processes support these
Privacy engineering satisfies the policies (clarified by an organization's legal department) at a technical level in every facet of technical interpretation and implementation. Security engineering and privacy engineering are closely intertwined. One can think of the system and security engineering as implementing the device and system level security functions that satisfy higher-level privacy needs, as specified by privacy policies and laws.
Privacy embedded into design means that there is a concrete mapping between the privacy protected data and the system functions, security functions, policies, and enforcements that enable that data to be protected.
The positive-sum principle of privacy engineering and design specifies that privacy improves the functionality (provides full functionality) and security of the system, not the other way around.
A zero-sum privacy approach would result in one of the following:
No improvement to security and functionality
Some type of reduction in functionality (or lost business processes)
Potentially a loss of some type of non-functional business or security need
In other words, a zero-sum approach necessarily means some types of trade-off are taking place, as opposed to a win-win approach (https://www.ipc.on.ca/images/resources/7foundationalprinciples.pdf).
End-to-end security is a frequently over-used term, but in the context of privacy it implies that data is protected throughout the lifecycle of the data—generation, ingestion, copying, distribution, redistribution, local and remote storage, archiving, and destruction. In other words, it is not a mere communications-level perspective on end-to-end as in encrypting and authenticating data in transit from one network endpoint to another. Rather, it takes into account the protected data and its treatment in and through all business processes, applications, systems, hardware, and people that touch it. End-to-end security addresses all of the technical and policy controls in place to ensure that the PPI is protected.
Privacy by design implies that any and all stakeholders (whether the system operator, device manufacturer, or affiliates) are operating by the rules, processes, procedures, and policies that they claim to be.
This principle is meant to satisfy any gaps in the auditing and accountability needs raised by the PIA. In essence, how would an end user be able to verify that your IoT privacy objectives or regulatory compliance goals are actually being met? Conversely, how could you as an IoT organization verify that your own affiliate providers' SLAs are being adhered to, especially those concerning privacy? One manner of providing visibility and transparency is for an IoT implementation or deployment organization to subject itself to independent third-party audits, for example, either publishing or making results available to requesters. Industry-specific audits may also satisfy certain facets of visibility and transparency. The old axiom trust but verify is the principle at work in this control.
A PbD solution will absolutely have built-in controls that allow respect for user privacy. Respect for user privacy entails providing users with knowledge and control with respect to privacy, notice of privacy policies and events, and the ability to opt out. The following fair information practices (FIPs) privacy principles address this topic in detail:
Consent: Consent shows respect for user privacy by ensuring that end users have the opportunity to understand how their data is being used and treated, and provide consent for its use based on that knowledge. The specificity of the consent given needs to be proportionate to the sensitivity of the data being provided. For example, use of medical charts, X-rays, and blood test data will require much greater detail and clarity in the consent notice than just use of one's age, gender, and food preferences.
Accuracy: Accuracy refers to the private information being kept current and accurate for whatever its intended purpose. Part of maintaining this FIP is to ensure that strong integrity controls are being enforced throughout the system. For example, high integrity controls may require digital signatures to be part of the record-keeping process, whereas less sensitive or impactful information may simply require cryptographic integrity in transit or checksums at rest.
Access: The access FIP addresses end users' ability to both access their personal information and ensure its accuracy (and have the ability to correct inaccurate information that has been detected).
Compliance: Compliance deals with how organizations provide the controls and mechanisms to end users to rectify problems in the accuracy or use of their data. For example, does the smart doll manufacturer in the earlier example have a process to:
Issue complaints?
Appeal any decisions made?
Escalate to an external organization or agency?
Privacy engineering is a relatively new discipline that seeks to ensure systems, applications, and devices are engineered to conform to privacy policies. This section provides some recommendations for setting up and operating a privacy engineering capability in your IoT organization.
Whether a small start-up or a large Silicon Valley tech company, chances are you are developing products and applications that will require PbD capabilities built in from the ground up. It is crucial that the engineering processes are followed to engineer a privacy-respecting IoT system from the outset and not bolt the protections on later. The right people and processes are first needed to accomplish this.
Privacy touches a variety of professions in the corporate and government world; attorneys and other legal professionals, engineers, QA, and other disciplines become involved in different capacities in the creation and adoption of privacy policies, their implementation, or their enforcement. The following diagram shows a high-level organization and what concerns each sub-organization has from a privacy perspective:
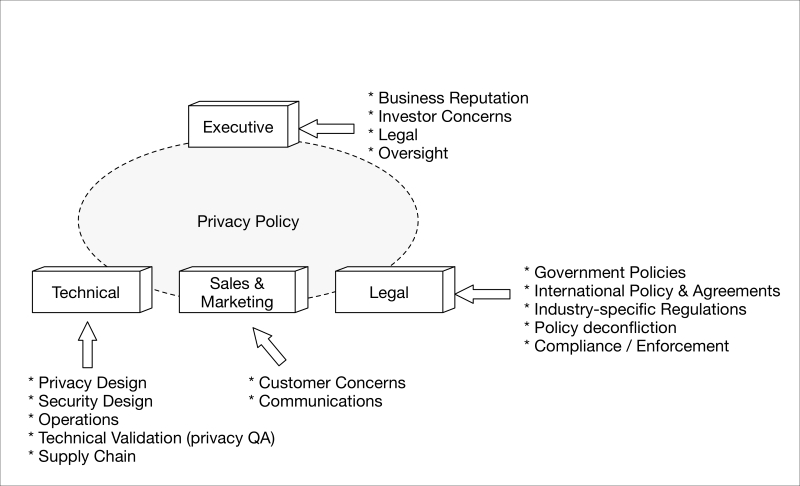
Privacy initiatives and working groups should be established within any organization that develops frontline IoT products and services which collect, process, view, or store any privacy information. The executive level should provide the holistic direction and ensure the different sub-organizations are accountable for their roles. Each department should have one or more privacy champions who put themselves in the shoes of end customers to ensure their interests—not only the dry, regulatory policies—are fully taken into account.
For all of the departments involved, the role of the privacy engineer is to understand and participate in both the policy and technical lifecycle of privacy management and implementation. Privacy engineering, a relatively new discipline, requires a different capability set than what is typically found in a single corporate department. We suggest the following attributes for individuals performing privacy engineering:
They are engineers, preferably ones with a security background. Lawyers and non-technical privacy professionals can and should be available for reference and consulting, but privacy engineering itself is an engineering discipline.
They ideally have privacy-related qualifications such as an IAPP (International Association of Privacy Professionals) certification (https://iapp.org/certify).
They have a strong knowledge of the following:
Privacy policy
System development processes and lifecycle
Functional and nonfunctional requirements, including security functional and security assurance requirements
Source code and software engineering practices, in the language(s) the systems are being developed in
Interface design (APIs)
Data storage design and operations
Application of security controls to networks, software, and hardware, as appropriate
Cryptography and proper use of cryptographic primitives and protocols, given their importance in protecting PII throughout device and information lifecycles
These are suggestions only; the needs of your organization may impose a number of other minimum requirements. In general, we have found that security engineers who have a development background and have obtained privacy professional training tend to be individuals optimally suited for privacy engineering.
Privacy engineering in a larger organization should consist of a dedicated department of individuals with the minimum qualifications listed above. Smaller organizations may not have dedicated departments, but may need to improvise by cross-training and adding privacy engineering duties to individuals engaged in other facets of the engineering process. Security engineers tend to be naturally adept at this. Regardless, depending on the size and scope of a project or program, at least one dedicated privacy engineer should be allocated at the inception of program to ensure that privacy needs are addressed. Ideally, this individual or set of individuals will be associated with the project throughout its development.
The assigned privacy engineer should:
Maintain a strong association with the development team, participating in:
Design reviews
Code reviews
Test activities and other validation/verification steps
Function as the end user advocate in the development of IoT capability. For example, when performing code reviews with the development team, this individual should ask probing questions about the treatment of each identified PII element (and verify each in code).
Where did it come from (verify in code)?
Is the code creating any metadata using the PII that we need to add to our list of PII?
How was it passed from function to function (by reference, by value) and how and where was it written to a database?
When a function did not need it anymore, was the value destroyed in memory? If so, how? Was it simply de-referenced or was it actively overwritten (understandably bound to the capabilities of the programming language)?
What security parameters (for example, used for encryption, authentication, or integrity) is the application or device depending on to protect the PII? How are they being treated from a security perspective, so that they are appropriately available to protect the PII?
If the code was inherited from another application or system, what do we need to do to verify that the inherited libraries are treating the PII we have identified appropriately?
In server applications, what type of cookies are we dropping into end users' web browsers? What are we tracking with them?
Is anything in the code violating the privacy policy we established at the beginning? If so, it needs to be re-engineered, otherwise privacy policy issues will have to be escalated to higher levels in the organization.
This list of activities is by no means exhaustive. The most important point is that privacy engineering activity is a dedicated function performed in conjunction with the other engineering disciplines (software engineering, firmware, and even hardware when necessary). The privacy engineer should absolutely be involved with the project from inception, requirements gathering, development, testing, and through deployment to ensure that the lifecycle of PII protection is engineered into the system, application, or device according to a well-defined policy.
Protecting privacy is a serious endeavor made even more challenging with the IoT's myriad forms, systems of systems, countless organizations, and the differences in which they are addressed across international borders. In addition, the gargantuan amount of data being collected, indexed, analyzed, redistributed, re-analyzed, and sold provides challenges for controlling data ownership, onward transfer, and acceptable use. In this section, we've learned about privacy principles, privacy engineering, and how to perform privacy impact assessments in support of an IoT deployment.