
Hadoop Tutorial: Master BigData
BigData is the latest buzzword in the IT Industry. Apache’s Hadoop is a leading Big Data platform used by IT giants Yahoo, Facebook & Google. This course is geared to make a Hadoop Expert.
This is an absolute beginner guide to Hadoop. But knowledge of 1) Java 2) Linux will help
| Tutorial | Introduction to BIG DATA: Types, Characteristics & Benefits |
| Tutorial | Hadoop Tutorial: Features, Components, Cluster & Topology |
| Tutorial | Hadoop Setup Tutorial - Installation & Configuration |
| Tutorial | HDFS Tutorial: Read & Write Commands using Java API |
| Tutorial | What is MapReduce? How it Works - Hadoop MapReduce Tutorial |
| Tutorial | Hadoop & Mapreduce Examples: Create your First Program |
| Tutorial | Hadoop MapReduce Tutorial: Counters & Joins with Example |
| Tutorial | What is Sqoop? What is FLUME - Hadoop Tutorial |
| Tutorial | Sqoop vs Flume vs HDFS in Hadoop |
| Tutorial | Create Your First FLUME Program - Beginner's Tutorial |
| Tutorial | Hadoop PIG Tutorial: Introduction, Installation & Example |
| Tutorial | Learn OOZIE in 5 Minutes - Hadoop Tutorial |
| Tutorial | Big Data Testing: Functional & Performance |
| Tutorial | Hadoop & MapReduce Interview Questions & Answers |
Check!
| Tutorial | Top 15 Big Data Tools |
| Tutorial | 11 Best Big Data Analytics Tools |
In order to understand 'Big Data', we first need to know what 'data' is. Oxford dictionary defines 'data' as -
"The quantities, characters, or symbols on which operations are performed by a computer, which may be stored and transmitted in the form of electrical signals and recorded on magnetic, optical, or mechanical recording media. "
In this tutorial we will learn,
So, 'Big Data' is also a data but with a huge size. 'Big Data' is a term used to describe collection of data that is huge in size and yet growing exponentially with time.In short, such a data is so large and complex that none of the traditional data management tools are able to store it or process it efficiently.
Following are some the examples of 'Big Data'-
 |
The New York Stock Exchange generates about one terabyte of new trade data per day. |
|
• Social Media Impact Statistic shows that 500+terabytes of new data gets ingested into the databases of social media site Facebook, every day. This data is mainly generated in terms of photo and video uploads, message exchanges, putting comments etc. |
 |
 |
Single Jet engine can generate 10+terabytes of data in 30 minutes of a flight time. With many thousand flights per day, generation of data reaches up to many Petabytes. |
Big data' could be found in three forms:
Any data that can be stored, accessed and processed in the form of fixed format is termed as a 'structured' data. Over the period of time, talent in computer science have achieved greater success in developing techniques for working with such kind of data (where the format is well known in advance) and also deriving value out of it. However, now days, we are foreseeing issues when size of such data grows to a huge extent, typical sizes are being in the rage of multiple zettabyte.
Do you know? 1021 bytes equals to 1 zettabyte or one billion terabytes forms a zettabyte.
Looking at these figures one can easily understand why the name 'Big Data' is given and imagine the challenges involved in its storage and processing.
Do you know? Data stored in a relational database management system is one example of a 'structured' data.
Examples Of Structured Data
An 'Employee' table in a database is an example of Structured Data
| Employee_ID | Employee_Name | Gender | Department | Salary_In_lacs |
|---|---|---|---|---|
| 2365 | Rajesh Kulkarni | Male | Finance | 650000 |
| 3398 | Pratibha Joshi | Female | Admin | 650000 |
| 7465 | Shushil Roy | Male | Admin | 500000 |
| 7500 | Shubhojit Das | Male | Finance | 500000 |
| 7699 | Priya Sane | Female | Finance | 550000 |
Any data with unknown form or the structure is classified as unstructured data. In addition to the size being huge, un-structured data poses multiple challenges in terms of its processing for deriving value out of it. Typical example of unstructured data is, a heterogeneous data source containing a combination of simple text files, images, videos etc. Now a day organizations have wealth of data available with them but unfortunately they don't know how to derive value out of it since this data is in its raw form or unstructured format.
Examples Of Un-structured Data
Output returned by 'Google Search'

Semi-structured data can contain both the forms of data. We can see semi-structured data as a strcutured in form but it is actually not defined with e.g. a table definition in relational DBMS. Example of semi-structured data is a data represented in XML file.
Examples Of Semi-structured Data
Personal data stored in a XML file-
<rec><name>Prashant Rao</name><sex>Male</sex><age>35</age></rec> <rec><name>Seema R.</name><sex>Female</sex><age>41</age></rec> <rec><name>Satish Mane</name><sex>Male</sex><age>29</age></rec> <rec><name>Subrato Roy</name><sex>Male</sex><age>26</age></rec> <rec><name>Jeremiah J.</name><sex>Male</sex><age>35</age></rec>
Data Growth over years

Please note that web application data, which is unstructured, consists of log files, transaction history files etc. OLTP systems are built to work with structured data wherein data is stored in relations (tables).
(i)Volume – The name 'Big Data' itself is related to a size which is enormous. Size of data plays very crucial role in determining value out of data. Also, whether a particular data can actually be considered as a Big Data or not, is dependent upon volume of data. Hence, 'Volume' is one characteristic which needs to be considered while dealing with 'Big Data'.
(ii)Variety – The next aspect of 'Big Data' is its variety.
Variety refers to heterogeneous sources and the nature of data, both structured and unstructured. During earlier days, spreadsheets and databases were the only sources of data considered by most of the applications. Now days, data in the form of emails, photos, videos, monitoring devices, PDFs, audio, etc. is also being considered in the analysis applications. This variety of unstructured data poses certain issues for storage, mining and analysing data.
(iii)Velocity – The term 'velocity' refers to the speed of generation of data. How fast the data is generated and processed to meet the demands, determines real potential in the data.
Big Data Velocity deals with the speed at which data flows in from sources like business processes, application logs, networks and social media sites, sensors, Mobile devices, etc. The flow of data is massive and continuous.
(iv)Variability – This refers to the inconsistency which can be shown by the data at times, thus hampering the process of being able to handle and manage the data effectively.
Ability to process 'Big Data' brings in multiple benefits, such as-
• Businesses can utilize outside intelligence while taking decisions
Access to social data from search engines and sites like facebook, twitter are enabling organizations to fine tune their business strategies.
• Improved customer service
Traditional customer feedback systems are getting replaced by new systems designed with 'Big Data' technologies. In these new systems, Big Data and natural language processing technologies are being used to read and evaluate consumer responses.
• Early identification of risk to the product/services, if any
• Better operational efficiency
'Big Data' technologies can be used for creating staging area or landing zone for new data before identifying what data should be moved to the data warehouse. In addition, such integration of 'Big Data' technologies and data warehouse helps organization to offload infrequently accessed data.
Apache HADOOP is a framework used to develop data processing applications which are executed in a distributed computing environment.
In this tutorial we will learn,
Similar to data residing in a local file system of personal computer system, in Hadoop, data resides in a distributed file system which is called as a Hadoop Distributed File system.
Processing model is based on 'Data Locality' concept wherein computational logic is sent to cluster nodes(server) containing data.
This computational logic is nothing but a compiled version of a program written in a high level language such as Java. Such a program, processes data stored in Hadoop HDFS.
HADOOP is an open source software framework. Applications built using HADOOP are run on large data sets distributed across clusters of commodity computers.
Commodity computers are cheap and widely available. These are mainly useful for achieving greater computational power at low cost.
Do you know? Computer cluster consists of a set of multiple processing units (storage disk + processor) which are connected to each other and acts as a single system.
Below diagram shows various components in Hadoop ecosystem-

Apache Hadoop consists of two sub-projects –
Although Hadoop is best known for MapReduce and its distributed file system- HDFS, the term is also used for a family of related projects that fall under the umbrella of distributed computing and large-scale data processing. Other Hadoop-related projects at Apache include are Hive, HBase, Mahout, Sqoop , Flume and ZooKeeper.
• Suitable for Big Data Analysis
As Big Data tends to be distributed and unstructured in nature, HADOOP clusters are best suited for analysis of Big Data. Since, it is processing logic (not the actual data) that flows to the computing nodes, less network bandwidth is consumed. This concept is called as data locality concept which helps increase efficiency of Hadoop based applications.
• Scalability
HADOOP clusters can easily be scaled to any extent by adding additional cluster nodes, and thus allows for growth of Big Data. Also, scaling does not require modifications to application logic.
• Fault Tolerance
HADOOP ecosystem has a provision to replicate the input data on to other cluster nodes. That way, in the event of a cluster node failure, data processing can still proceed by using data stored on another cluster node.
Topology (Arrangment) of the network, affects performance of the Hadoop cluster when size of the hadoop cluster grows. In addition to the performance, one also needs to care about the high availability and handling of failures. In order to achieve this Hadoop cluster formation makes use of network topology.

Typically, network bandwidth is an important factor to consider while forming any network. However, as measuring bandwidth could be difficult, in Hadoop, network is represented as a tree and distance between nodes of this tree (number of hops) is considered as important factor in the formation of Hadoop cluster. Here, distance between two nodes is equal to sum of their distance to their closest common ancestor.
Hadoop cluster consists of data center, the rack and the node which actually executes jobs. Here, data center consists of racks and rack consists of nodes. Network bandwidth available to processes varies depending upon location of the processes. That is, bandwidth available becomes lesser as we go away from-
Prerequisites:
You must have Ubuntu installed and running
You must have Java Installed.
Step 1) Add a Hadoop system user using below command
sudo addgroup hadoop_

sudo adduser --ingroup hadoop_ hduser_
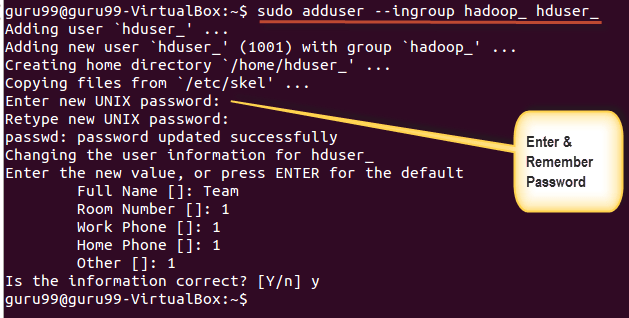
Enter your password , name and other details.
NOTE:
There is a possibility of below mentioned error in this setup and installation process.
"hduser is not in the sudoers file. This incident will be reported."

This error can be resolved by
Login as a root user

Execute the command
sudo adduser hduser_ sudo

Re-login as hduser_

Step 2) . Configure SSH
In order to manage nodes in a cluster, Hadoop require SSH access
First, switch user, enter following command
su - hduser_

This command will create a new key.
ssh-keygen -t rsa -P ""

Enable SSH access to local machine using this key.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

Now test SSH setup by connecting to locahost as 'hduser' user.
ssh localhost

Note:
Please note, if you see below error in response to 'ssh localhost', then there is a possibility that SSH is not available on this system-

To resolve this -
Purge SSH using,
sudo apt-get purge openssh-server
It is good practice to purge before start of installation

Install SSH using command-
sudo apt-get install openssh-server

Step 3) Next step is to Download Hadoop

Select Stable

Select the tar.gz file ( not the file with src)

Once download is complete, navigate to the directory containing the tar file

Enter , sudo tar xzf hadoop-2.2.0.tar.gz

Now, rename rename hadoop-2.2.0 as hadoop
sudo mv hadoop-2.2.0 hadoop

sudo chown -R hduser_:hadoop_ hadoop

Step 4) Modify ~/.bashrc file
Add following lines to end of file ~/.bashrc
#Set HADOOP_HOME export HADOOP_HOME=<Installation Directory of Hadoop> #Set JAVA_HOME export JAVA_HOME=<Installation Directory of Java> # Add bin/ directory of Hadoop to PATH export PATH=$PATH:$HADOOP_HOME/bin
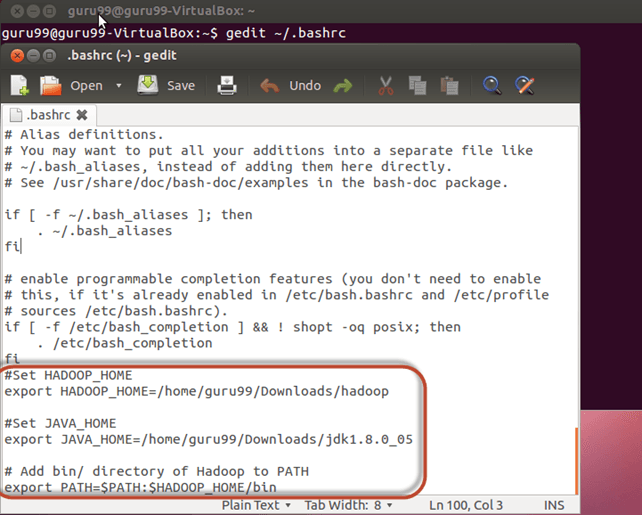
Now, source this environment configuration using below command
. ~/.bashrc

Step 5) Configurations related to HDFS
Set JAVA_HOME inside file $HADOOP_HOME/etc/hadoop/hadoop-env.sh


With

There are two parameters in $HADOOP_HOME/etc/hadoop/core-site.xml which need to be set-
1. 'hadoop.tmp.dir' - Used to specify directory which will be used by Hadoop to store its data files.
2. 'fs.default.name' - This specifies the default file system.
To set these parameters, open core-site.xml
sudo gedit $HADOOP_HOME/etc/hadoop/core-site.xml

Copy below line in between tags <configuration></configuration>
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>Parent directory for other temporary directories.</description> </property> <property> <name>fs.defaultFS </name> <value>hdfs://localhost:54310</value> <description>The name of the default file system. </description> </property>

Navigate to the directory $HADOOP_HOME/etc/Hadoop

Now, create the directory mentioned in core-site.xml
sudo mkdir -p <Path of Directory used in above setting>

Grant permissions to the directory
sudo chown -R hduser_:Hadoop_ <Path of Directory created in above step>

sudo chmod 750 <Path of Directory created in above step>

Step 6) Map Reduce Configuration
Before you begin with these configurations, lets set HADOOP_HOME path
sudo gedit /etc/profile.d/hadoop.sh
And Enter
export HADOOP_HOME=/home/guru99/Downloads/Hadoop

Next enter
sudo chmod +x /etc/profile.d/hadoop.sh

Exit the Terminal and restart again
Type echo $HADOOP_HOME. To verify the path

Now copy files
sudo cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml

Open the mapred-site.xml file
sudo gedit $HADOOP_HOME/etc/hadoop/mapred-site.xml

Add below lines of setting in between tags <configuration> and </configuration>
<property> <name>mapreduce.jobtracker.address</name> <value>localhost:54311</value> <description>MapReduce job tracker runs at this host and port. </description> </property>

Open $HADOOP_HOME/etc/hadoop/hdfs-site.xml as below,
sudo gedit $HADOOP_HOME/etc/hadoop/hdfs-site.xml

Add below lines of setting between tags <configuration> and </configuration>
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication.</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser_/hdfs</value> </property>

Create directory specified in above setting-
sudo mkdir -p <Path of Directory used in above setting>
sudo mkdir -p /home/hduser_/hdfs

sudo chown -R hduser_:hadoop_ <Path of Directory created in above step>
sudo chown -R hduser_:hadoop_ /home/hduser_/hdfs

sudo chmod 750 <Path of Directory created in above step>
sudo chmod 750 /home/hduser_/hdfs

Step 7) Before we start Hadoop for the first time, format HDFS using below command
$HADOOP_HOME/bin/hdfs namenode -format

Step 8) Start Hadoop single node cluster using below command
$HADOOP_HOME/sbin/start-dfs.sh
Output of above command

$HADOOP_HOME/sbin/start-yarn.sh

Using 'jps' tool/command, verify whether all the Hadoop related processes are running or not.
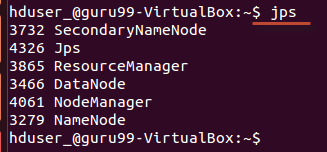
If Hadoop has started successfully then output of jps should show NameNode, NodeManager, ResourceManager, SecondaryNameNode, DataNode.
Step 9) Stopping Hadoop
$HADOOP_HOME/sbin/stop-dfs.sh

$HADOOP_HOME/sbin/stop-yarn.sh

Hadoop comes with a distributed file system called HDFS (HADOOP Distributed File Systems) HADOOP based applications make use of HDFS. HDFS is designed for storing very large data files, running on clusters of commodity hardware. It is fault tolerant, scalable, and extremely simple to expand.
Do you know? When data exceeds the capacity of storage on a single physical machine, it becomes essential to divide it across number of separate machines. File system that manages storage specific operations across a network of machines is called as distributed file system.
In this tutorial we will learn,
HDFS cluster primarily consists of a NameNode that manages the file system Metadata and a DataNodes that stores the actual data.
Read/write operations in HDFS operate at a block level. Data files in HDFS are broken into block-sized chunks, which are stored as independent units. Default block-size is 64 MB.
HDFS operates on a concept of data replication wherein multiple replicas of data blocks are created and are distributed on nodes throughout a cluster to enable high availability of data in the event of node failure.
Do you know? A file in HDFS, which is smaller than a single block, does not occupy a block's full storage.
Data read request is served by HDFS, NameNode and DataNode. Let's call reader as a 'client'. Below diagram depicts file read operation in Hadoop.

In this section, we will understand how data is written into HDFS through files.

In this section, we try to understand Java interface used for accessing Hadoop's file system.
In order to interact with Hadoop's filesytem programmatically, Hadoop provides multiple JAVA classes. Package named org.apache.hadoop.fs contains classes useful in manipulation of a file in Hadoop's filesystem. These operations include, open, read, write, and close. Actually, file API for Hadoop is generic and can be extended to interact with other filesystems other than HDFS.
Reading a file from HDFS, programmatically
Object java.net.URL is used for reading contents of a file. To begin with, we need to make Java recognize Hadoop's hdfs URL scheme. This is done by calling setURLStreamHandlerFactory method on URL object and an instance of FsUrlStreamHandlerFactory is passed to it. This method needs to be executed only once per JVM, hence it is enclosed in a static block.
An example code is-
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStream();
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}
This code opens and reads contents of a file. Path of this file on HDFS is passed to the program as a commandline argument.
This is one of the simplest way to interact with HDFS. Command-line interface has support for filesystem operations like read file, create directories, moving files, deleting data, and listing directories.
We can run '$HADOOP_HOME/bin/hdfs dfs -help' to get detailed help on every command. Here, 'dfs' is a shell command of HDFS which supports multiple subcommands.
Some of the widely used commands are listed below along with some details of each one.
1. Copy a file from local filesystem to HDFS
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal temp.txt /

This command copies file temp.txt from local filesystem to HDFS.
2. We can list files present in a directory using -ls
$HADOOP_HOME/bin/hdfs dfs -ls /

We can see a file 'temp.txt' (copied earlier) being listed under ' / ' directory.
3. Command to copy a file to local filesystem from HDFS
$HADOOP_HOME/bin/hdfs dfs -copyToLocal /temp.txt

We can see temp.txt copied to local filesystem.
4. Command to create new directory
$HADOOP_HOME/bin/hdfs dfs -mkdir /mydirectory

Check whether directory is created or not. Now, you should know how to do it ;-)
MapReduce is a programming model suitable for processing of huge data. Hadoop is capable of running MapReduce programs written in various languages: Java, Ruby, Python, and C++. MapReduce programs are parallel in nature, thus are very useful for performing large-scale data analysis using multiple machines in the cluster.
MapReduce programs work in two phases:
Input to each phase are key-value pairs. In addition, every programmer needs to specify two functions: map function and reduce function.
The whole process goes through three phase of execution namely,
Lets understand this with an example –
Consider you have following input data for your MapReduce Program
Welcome to Hadoop Class
Hadoop is good
Hadoop is bad

The final output of the MapReduce task is
| bad | 1 |
| Class | 1 |
| good | 1 |
| Hadoop | 3 |
| is | 2 |
| to | 1 |
| Welcome | 1 |
The data goes through following phases
Input Splits:
Input to a MapReduce job is divided into fixed-size pieces called input splits Input split is a chunk of the input that is consumed by a single map
Mapping
This is very first phase in the execution of map-reduce program. In this phase data in each split is passed to a mapping function to produce output values. In our example, job of mapping phase is to count number of occurrences of each word from input splits (more details about input-split is given below) and prepare a list in the form of <word, frequency>
Shuffling
This phase consumes output of Mapping phase. Its task is to consolidate the relevant records from Mapping phase output. In our example, same words are clubed together along with their respective frequency.
Reducing
In this phase, output values from Shuffling phase are aggregated. This phase combines values from Shuffling phase and returns a single output value. In short, this phase summarizes the complete dataset.
In our example, this phase aggregates the values from Shuffling phase i.e., calculates total occurrences of each words.
Hadoop divides the job into tasks. There are two types of tasks:
as mentioned above.
The complete execution process (execution of Map and Reduce tasks, both) is controlled by two types of entities called a
For every job submitted for execution in the system, there is one Jobtracker that resides on Namenode and there are multiple tasktrackers which reside on Datanode.

Problem Statement:
Find out Number of Products Sold in Each Country.
Prerequisites:
Before we start with the actual process, change user to 'hduser' (user used for Hadoop ).
su - hduser_

| Transaction date | Product | Price | Payment Type | Name | City | State | Country | Account Created | Last Login | Latitude | Longitude |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 01-02-2009 6:17 | Product1 | 1200 | Mastercard | carolina | Basildon | England | United Kingdom | 01-02-2009 6:00 | 01-02-2009 6:08 | 51.5 | -1.1166667 |
| 01-02-2009 4:53 | Product1 | 1200 | Visa | Betina | Parkville | MO | United States | 01-02-2009 4:42 | 01-02-2009 7:49 | 39.195 | -94.68194 |
| 01-02-2009 13:08 | Product1 | 1200 | Mastercard | Federica e Andrea | Astoria | OR | United States | 01-01-2009 16:21 | 01-03-2009 12:32 | 46.18806 | -123.83 |
| 01-03-2009 14:44 | Product1 | 1200 | Visa | Gouya | Echuca | Victoria | Australia | 9/25/05 21:13 | 01-03-2009 14:22 | -36.1333333 | 144.75 |
| 01-04-2009 12:56 | Product2 | 3600 | Visa | Gerd W | Cahaba Heights | AL | United States | 11/15/08 15:47 | 01-04-2009 12:45 | 33.52056 | -86.8025 |
| 01-04-2009 13:19 | Product1 | 1200 | Visa | LAURENCE | Mickleton | NJ | United States | 9/24/08 15:19 | 01-04-2009 13:04 | 39.79 | -75.23806 |
Create a new directory with name MapReduceTutorial
sudo mkdir MapReduceTutorial

Give permissions
sudo chmod -R 777 MapReduceTutorial
 SalesMapper.java
SalesMapper.java
package SalesCountry;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesMapper extends MapReduceBase implements Mapper <LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
public void map(LongWritable key, Text value, OutputCollector <Text, IntWritable> output, Reporter reporter) throws IOException {
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
output.collect(new Text(SingleCountryData[7]), one);
}
}
SalesCountryReducer.java
package SalesCountry;
import java.io.IOException;
import java.util.*;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.*;
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text t_key, Iterator<IntWritable> values, OutputCollector<Text,IntWritable> output, Reporter reporter) throws IOException {
Text key = t_key;
int frequencyForCountry = 0;
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
output.collect(key, new IntWritable(frequencyForCountry));
}
}
SalesCountryDriver.java
package SalesCountry;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapred.*;
public class SalesCountryDriver {
public static void main(String[] args) {
JobClient my_client = new JobClient();
// Create a configuration object for the job
JobConf job_conf = new JobConf(SalesCountryDriver.class);
// Set a name of the Job
job_conf.setJobName("SalePerCountry");
// Specify data type of output key and value
job_conf.setOutputKeyClass(Text.class);
job_conf.setOutputValueClass(IntWritable.class);
// Specify names of Mapper and Reducer Class
job_conf.setMapperClass(SalesCountry.SalesMapper.class);
job_conf.setReducerClass(SalesCountry.SalesCountryReducer.class);
// Specify formats of the data type of Input and output
job_conf.setInputFormat(TextInputFormat.class);
job_conf.setOutputFormat(TextOutputFormat.class);
// Set input and output directories using command line arguments,
//arg[0] = name of input directory on HDFS, and arg[1] = name of output directory to be created to store the output file.
FileInputFormat.setInputPaths(job_conf, new Path(args[0]));
FileOutputFormat.setOutputPath(job_conf, new Path(args[1]));
my_client.setConf(job_conf);
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}
}
}
If you want to understand the code in these files refer this Guide
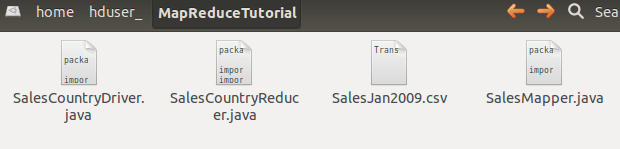
Check the file permissions of all these files

and if 'read' permissions are missing then grant the same-

Export classpath
export CLASSPATH="$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.2.0.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.2.0.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.2.0.jar:~/MapReduceTutorial/SalesCountry/*:$HADOOP_HOME/lib/*"

Compile Java files (these files are present in directory Final-MapReduceHandsOn). Its class files will be put in the package directory
javac -d . SalesMapper.java SalesCountryReducer.java SalesCountryDriver.java

This warning can be safely ignored.
This compilation will create a directory in a current directory named with package name specified in the java source file (i.e. SalesCountry in our case) and put all compiled class files in it.

Create a new file Manifest.txt
sudo gedit Manifest.txt
add following lines to it,
Main-Class: SalesCountry.SalesCountryDriver

SalesCountry.SalesCountryDriver is name of main class. Please note that you have to hit enter key at end of this line.
Create a Jar file
jar cfm ProductSalePerCountry.jar Manifest.txt SalesCountry/*.class

Check that the jar file is created

Start Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Copy the File SalesJan2009.csv into ~/inputMapReduce
Now Use below command to copy ~/inputMapReduce to HDFS.
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/inputMapReduce /

We can safely ignore this warning.
Verify whether file is actually copied or not.
$HADOOP_HOME/bin/hdfs dfs -ls /inputMapReduce

Run MapReduce job
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

This will create an output directory named mapreduce_output_sales on HDFS. Contents of this directory will be a file containing product sales per country.
Result can be seen through command interface as,
$HADOOP_HOME/bin/hdfs dfs -cat /mapreduce_output_sales/part-00000
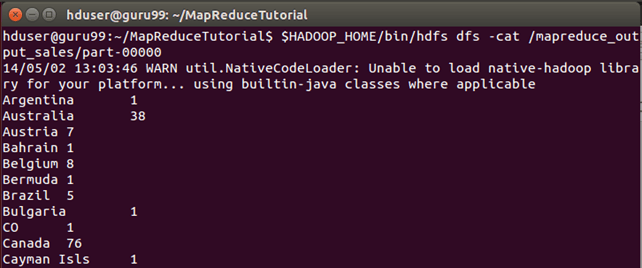
o/p of above
OR
Results can also be seen via web interface as-
Results through web interface-
Open r in web browser.

Now select 'Browse the filesystem' and navigate upto /mapreduce_output_sales
o/p of above

Open part-r-00000

In this section we will understand implementation of SalesMapper class.
1. We begin by specifying name of package for our class. SalesCountry is name of out package. Please note that output of compilation, SalesMapper.class will go into directory named by this package name: SalesCountry.
Followed by this, we import library packages.
Below snapshot shows implementation of SalesMapper class-

Code Explanation:
1. SalesMapper Class Definition-
public class SalesMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
Every mapper class must be extended from MapReduceBase class and it must implement Mapper interface.
2. Defining 'map' function-
public void map(LongWritable key,
Text value,
OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException
Main part of Mapper class is a 'map()' method which accepts four arguments.
At every call to 'map()' method, a key-value pair ('key' and 'value' in this code) is passed.
'map()' method begins by splitting input text which is received as an argument. It uses tokenizer to split these lines into words.
String valueString = value.toString();
String[] SingleCountryData = valueString.split(",");
Here, ',' is used as a delimiter.
After this, a pair is formed using a record at 7th index of array 'SingleCountryData' and a value '1'.
output.collect(new Text(SingleCountryData[7]), one);
We are choosing record at 7th index because we need Country data and it is located at 7th index in array 'SingleCountryData'.
Please note that our input data is in the below format (where Country is at 7th index, with 0 as a starting index)-
Transaction_date,Product,Price,Payment_Type,Name,City,State,Country,Account_Created,Last_Login,Latitude,Longitude
Output of mapper is again a key-value pair which is outputted using 'collect()' method of 'OutputCollector'.
In this section we will understand implementation of SalesCountryReducer class.
1. We begin by specifying name of package for our class. SalesCountry is name of out package. Please note that output of compilation, SalesCountryReducer.class will go into directory named by this package name: SalesCountry.
Followed by this, we import library packages.
Below snapshot shows implementation of SalesCountryReducer class-
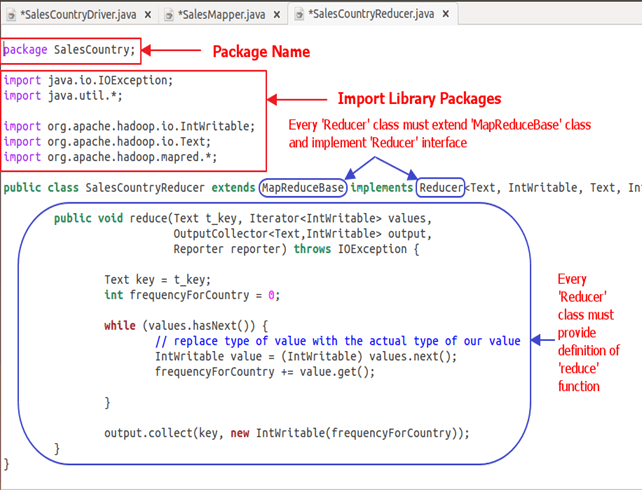
Code Explanation:
1. SalesCountryReducer Class Definition-
public class SalesCountryReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
Here, first two data types, 'Text' and 'IntWritable' are data type of input key-value to the reducer.
Output of mapper is in the form of <CountryName1, 1>, <CountryName2, 1>. This output of mapper becomes input to the reducer. So, to align with its data type, Text and IntWritable are used as data type here.
The last two data types, 'Text' and 'IntWritable' are data type of output generated by reducer in the form of key-value pair.
Every reducer class must be extended from MapReduceBase class and it must implement Reducer interface.
2. Defining 'reduce' function-
public void reduce( Text t_key,
Iterator<IntWritable> values,
OutputCollector<Text,IntWritable> output,
Reporter reporter) throws IOException {
Input to the reduce() method is a key with list of multiple values.
For example, in our case it will be-
<United Arab Emirates, 1>, <United Arab Emirates, 1>, <United Arab Emirates, 1>,<United Arab Emirates, 1>, <United Arab Emirates, 1>, <United Arab Emirates, 1>.
This is given to reducer as <United Arab Emirates, {1,1,1,1,1,1}>
So, to accept arguments of this form, first two data types are used, viz., Text and Iterator<IntWritable>. Text is a data type of key and Iterator<IntWritable> is a data type for list of values for that key.
The next argument is of type OutputCollector<Text,IntWritable> which collects output of reducer phase.
reduce() method begins by copying key value and initializing frequency count to 0.
Text key = t_key;
int frequencyForCountry = 0;
Then, using 'while' loop, we iterate through the list of values associated with the key and calculate the final frequency by summing up all the values.
while (values.hasNext()) {
// replace type of value with the actual type of our value
IntWritable value = (IntWritable) values.next();
frequencyForCountry += value.get();
}
Now, we push the result to the output collector in the form of key and obtained frequency count.
Below code does this-
output.collect(key, new IntWritable(frequencyForCountry));
In this section we will understand implementation of SalesCountryDriver class
1. We begin by specifying name of package for our class. SalesCountry is name of out package. Please note that output of compilation, SalesCountryDriver.class will go into directory named by this package name: SalesCountry.
Here is a line specifying package name followed by code to import library packages.

2. Define a driver class which will create a new client job, configuration object and advertise Mapper and Reducer classes.
The driver class is responsible for setting our MapReduce job to run in Hadoop. In this class, we specify job name, data type of input/output and names of mapper and reducer classes.
3. In below code snippet, we set input and output directories which are used to consume input dataset and produce output, respectively.
arg[0] and arg[1] are the command-line arguments passed with a command given in MapReduce hands-on, i.e.,
$HADOOP_HOME/bin/hadoop jar ProductSalePerCountry.jar /inputMapReduce /mapreduce_output_sales

4. Trigger our job
Below code start execution of MapReduce job-
try {
// Run the job
JobClient.runJob(job_conf);
} catch (Exception e) {
e.printStackTrace();
}
A counter in MapReduce is a mechanism used for collecting statistical information about the MapReduce job. This information could be useful for diagnosis of a problem in MapReduce job processing. Counters are similar to putting log message in the code for map or reduce.
In this tutorial we will learn,
Typically, these counters are defined in a program (map or reduce) and are incremented during execution when a particular event or condition (specific to that counter) occurs. A very good application of counters is to track valid and invalid records from an input dataset.
1. Hadoop Built-In counters: There are some built-in counters which exist per job. Below are built-in counter groups-
2. User Defined Counters
In addition to built-in counters, user can define his own counters using similar functionalities provided by programming languages. For example, in Java 'enum' are used to define user defined counters.
An example MapClass with Counters to count the number of missing and invalid values:
public static class MapClass
extends MapReduceBase
implements Mapper<LongWritable, Text, Text, Text>
{
static enum SalesCounters { MISSING, INVALID };
public void map ( LongWritable key, Text value,
OutputCollector<Text, Text> output,
Reporter reporter) throws IOException
{
//Input string is split using ',' and stored in 'fields' array
String fields[] = value.toString().split(",", -20);
//Value at 4th index is country. It is stored in 'country' variable
String country = fields[4];
//Value at 8th index is sales data. It is stored in 'sales' variable
String sales = fields[8];
if (country.length() == 0) {
reporter.incrCounter(SalesCounters.MISSING, 1);
} else if (sales.startsWith("\"")) {
reporter.incrCounter(SalesCounters.INVALID, 1);
} else {
output.collect(new Text(country), new Text(sales + ",1"));
}
}
}
Above code snippet shows an example implementation of counters in Map Reduce.
Here, SalesCounters is a counter defined using 'enum'. It is used to count MISSING and INVALID input records.
In the code snippet, if 'country' field has zero length then its value is missing and hence corresponding counter SalesCounters.MISSING is incremented.
Next, if 'sales' field starts with a " then the record is considered INVALID. This is indicated by incrementing counter SalesCounters.INVALID.
Joining two large dataset can be achieved using MapReduce Join. However, this process involves writing lots of code to perform actual join operation.
Joining of two datasets begin by comparing size of each dataset. If one dataset is smaller as compared to the other dataset then smaller dataset is distributed to every datanode in the cluster. Once it is distributed, either Mapper or Reducer uses smaller dataset to perform lookup for matching records from large dataset and then combine those records to form output records.
Depending upon the place where actual join is performed, this join is classified into-
1. Map-side join - When the join is performed by the mapper, it is called as map-side join. In this type, the join is performed before data is actually consumed by the map function. It is mandatory that the input to each map is in the form of a partition and is in sorted order. Also, there must be an equal number of partitions and it must be sorted by the join key.
2. Reduce-side join - When the join is performed by the reducer, it is called as reduce-side join. There is no necessity in this join to have dataset in a structured form (or partitioned).
Here, map side processing emits join key and corresponding tuples of both the tables. As an effect of this processing, all the tuples with same join key fall into the same reducer which then joins the records with same join key.
Overall process flow is depicted in below diagram.

Problem Statement:
There are 2 Sets of Data in 2 Different Files
|
|
|
The Key Dept_ID is common in both files.
The goal is to use MapReduce Join to combine these files
Input: Our input data set is a txt file, DeptName.txt & DepStrength.txt
Download Input Files From Here
Prerequisites:
Before we start with the actual process, change user to 'hduser' (user used for Hadoop ).
su - hduser_

Steps:
Step 1) Copy the zip file to location of your choice

Step 2) Uncompress the Zip File
sudo tar -xvf MapReduceJoin.tar.gz

Step 3)
Go to directory MapReduceJoin/
cd MapReduceJoin/

Step 4) Start Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh

Step 5) DeptStrength.txt and DeptName.txt are the input files used for this program.
These file needs to be copied to HDFS using below command-
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /

Step 6) Run the program using below command-
$HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar MapReduceJoin/JoinDriver/DeptStrength.txt /DeptName.txt /output_mapreducejoin


Step 7)
After execution, output file (named 'part-00000') will stored in the directory /output_mapreducejoin on HDFS
Results can be seen using the command line interface
$HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

Results can also be seen via web interface as-

Now select 'Browse the filesystem' and navigate upto /output_mapreducejoin

Open part-r-00000

Results are shown

NOTE: Please note that before running this program for the next time, you will need to delete output directory /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
Alternative is to use different name for output directory.
Before we learn more about Flume and Sqoop , lets study
Issues with Data Load into Hadoop
Analytical processing using Hadoop requires loading of huge amounts of data from diverse sources into Hadoop clusters.
This process of bulk data load into Hadoop, from heterogeneous sources and then processing it, comes with certain set of challenges.
Maintaining and ensuring data consistency and ensuring efficient utilization of resources, are some factors to consider before selecting right approach for data load.
Major Issues:
1. Data load using Scripts
Traditional approach of using scripts to load data, is not suitable for bulk data load into Hadoop; this approach is inefficient and very time consuming.
2. Direct access to external data via Map-Reduce application
Providing direct access to the data residing at external systems(without loading into Hadopp) for map reduce applications complicates these applications. So, this approach is not feasible.
3.In addition to having ability to work with enormous data, Hadoop can work with data in several different forms. So, to load such heterogeneous data into Hadoop, different tools have been developed. Sqoop and Flume are two such data loading tools.
Apache Sqoop (SQL-to-Hadoop) is designed to support bulk import of data into HDFS from structured data stores such as relational databases, enterprise data warehouses, and NoSQL systems. Sqoop is based upon a connector architecture which supports plugins to provide connectivity to new external systems.
An example use case of Sqoop, is an enterprise that runs a nightly Sqoop import to load the day's data from a production transactional RDBMS into a Hive data warehouse for further analysis.
Sqoop Connectors
All the existing Database Management Systems are designed with SQL standard in mind. However, each DBMS differs with respect to dialect to some extent. So, this difference poses challenges when it comes to data transfers across the systems. Sqoop Connectors are components which help overcome these challenges.
Data transfer between Sqoop and external storage system is made possible with the help of Sqoop's connectors.
Sqoop has connectors for working with a range of popular relational databases, including MySQL, PostgreSQL, Oracle, SQL Server, and DB2. Each of these connectors knows how to interact with its associated DBMS. There is also a generic JDBC connector for connecting to any database that supports Java's JDBC protocol. In addition, Sqoop provides optimized MySQL and PostgreSQL connectors that use database-specific APIs to perform bulk transfers efficiently.

In addition to this, Sqoop has various third party connectors for data stores,
ranging from enterprise data warehouses (including Netezza, Teradata, and Oracle) to NoSQL stores (such as Couchbase). However, these connectors do not come with Sqoop bundle ;those need to be downloaded separately and can be added easily to an existing Sqoop installation.
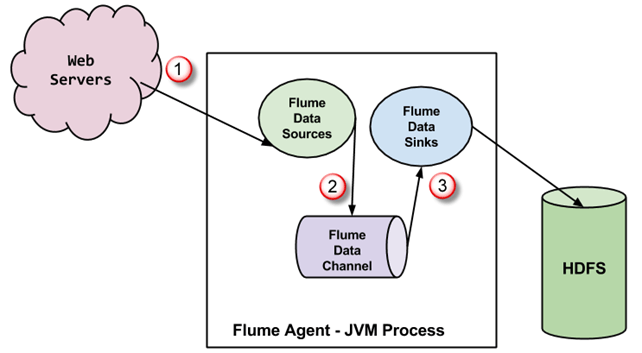
Apache Flume is a system used for moving massive quantities of streaming data into HDFS. Collecting log data present in log files from web servers and aggregating it in HDFS for analysis, is one common example use case of Flume.
Flume supports multiple sources like –
Data Flow in Flume
A Flume agent is a JVM process which has 3 components -Flume Source, Flume Channel and Flume Sink- through which events propagate after initiated at an external source .
| Sqoop | Flume | HDFS |
| Sqoop is used for importing data from structured data sources such as RDBMS. | Flume is used for moving bulk streaming data into HDFS. | HDFS is a distributed file system used by Hadoop ecosystem to store data. |
| Sqoop has a connector based architecture. Connectors know how to connect to the respective data source and fetch the data. | Flume has an agent based architecture. Here, code is written (which is called as 'agent') which takes care of fetching data. | HDFS has a distributed architecture where data is distributed across multiple data nodes. |
| HDFS is a destination for data import using Sqoop. | Data flows to HDFS through zero or more channels. | HDFS is an ultimate destination for data storage. |
| Sqoop data load is not event driven. | Flume data load can be driven by event. | HDFS just stores data provided to it by whatsoever means. |
| In order to import data from structured data sources, one has to use Sqoop only, because its connectors know how to interact with structured data sources and fetch data from them. | In order to load streaming data such as tweets generated on Twitter or log files of a web server, Flume should be used. Flume agents are built for fetching streaming data. | HDFS has its own built-in shell commands to store data into it. HDFS can not import streaming data |
Prerequisites:
This tutorial is developed on Linux - Ubuntu operating System.
You should have Hadoop (version 2.2.0 used for this tutorial) already installed and is running on the system.
You should have Java(version 1.8.0 used for this tutorial) already installed on the system.
You should have set JAVA_HOME accordingly.
Before we start with the actual process, change user to 'hduser' (user used for Hadoop ).
su - hduser

Steps :
Flume, library and source code setup
sudo mkdir FlumeTutorial
Download Input Files From Here
Check the file permissions of all these files and if 'read' permissions are missing then grant the same-

2. Download 'Apache Flume' from site- https://flume.apache.org/download.html
Apache Flume 1.4.0 has been used in this tutorial.

Next Click

3. Copy the downloaded tarball in the directory of your choice and extract contents using the following command
sudo tar -xvf apache-flume-1.4.0-bin.tar.gz

This command will create a new directory named apache-flume-1.4.0-bin and extract files into it. This directory will be referred to as <Installation Directory of Flume> in rest of the article.
4. Flume library setup
Copy twitter4j-core-4.0.1.jar, flume-ng-configuration-1.4.0.jar, flume-ng-core-1.4.0.jar, flume-ng-sdk-1.4.0.jar to
<Installation Directory of Flume>/lib/
It is possible that either or all of the copied JAR will have execute permission. This may cause issue with the compilation of code. So, revoke execute permission on such JAR.
In my case, twitter4j-core-4.0.1.jar was having execute permission. I revoked it as below-
sudo chmod -x twitter4j-core-4.0.1.jar

After this command give 'read' permission on twitter4j-core-4.0.1.jar to all.
sudo chmod +rrr /usr/local/apache-flume-1.4.0-bin/lib/twitter4j-core-4.0.1.jar
Please note that I have downloaded-
- twitter4j-core-4.0.1.jar from http://mvnrepository.com/artifact/org.twitter4j/twitter4j-core
- Allflume JARs i.e., flume-ng-*-1.4.0.jar from http://mvnrepository.com/artifact/org.apache.flume
Load data from Twitter using Flume
1. Go to directory containing source code files in it.
2. Set CLASSPATH to contain <Flume Installation Dir>/lib/* and ~/FlumeTutorial/flume/mytwittersource/*
export CLASSPATH="/usr/local/apache-flume-1.4.0-bin/lib/*:~/FlumeTutorial/flume/mytwittersource/*"

3. Compile source code using command-
javac -d . MyTwitterSourceForFlume.java MyTwitterSource.java

4.Create jar
First,create Manifest.txt file using text editor of your choice and add below line in it-
Main-Class: flume.mytwittersource.MyTwitterSourceForFlume
.. here flume.mytwittersource.MyTwitterSourceForFlume is name of the main class. Please note that you have to hit enter key at end of this line.

Now, create JAR 'MyTwitterSourceForFlume.jar' as-
jar cfm MyTwitterSourceForFlume.jar Manifest.txt flume/mytwittersource/*.class

5. Copy this jar to <Flume Installation Directory>/lib/
sudo cp MyTwitterSourceForFlume.jar <Flume Installation Directory>/lib/

6. Go to configuration directory of Flume, <Flume Installation Directory>/conf
If flume.conf does not exist, then copy flume-conf.properties.template and rename it to flume.conf
sudo cp flume-conf.properties.template flume.conf

If flume-env.sh does not exist, then copy flume-env.sh.template and rename it to flume-env.sh
sudo cp flume-env.sh.template flume-env.sh

7. Create a Twitter application by signing in to https://dev.twitter.com/


a. Go to 'My applications' (This option gets dropped down when 'Egg'
button at top right corner is clicked)

b. Create a new application by clicking 'Create New App'
c. Fill up application details by specifying name of application, description
and website. You may refer to the notes given underneath each input box.
d. Scroll down the page and accept terms by marking 'Yes, I agree' and click on button 'Create your Twitter application'

e. On window of newly created application, go to tab, 'API Keys' scroll down the page and click button 'Create my access token'


f. Refresh the page.
g. Click on 'Test OAuth'. This will display 'OAuth' settings of application.

h. Modify 'flume.conf' (created in Step 6) using these OAuth settings. Steps to modify 'flume.conf' are given in step 8 below.

We need to copy Consumer key, Consumer secret, Access token and Access token secret to update 'flume.conf'.
Note: These values belongs to the user and hence are confidential, so should not be shared.
8. Open 'flume.conf' in write mode and set values for below parameters-
[A]
sudo gedit flume.conf
- Copy below contents-
- MyTwitAgent.sources = Twitter
- MyTwitAgent.channels = MemChannel
- MyTwitAgent.sinks = HDFS
- MyTwitAgent.sources.Twitter.type = flume.mytwittersource.MyTwitterSourceForFlume
- MyTwitAgent.sources.Twitter.channels = MemChannel
- MyTwitAgent.sources.Twitter.consumerKey = <Copy consumer key value from Twitter App>
- MyTwitAgent.sources.Twitter.consumerSecret = <Copy consumer secret value from Twitter App>
- MyTwitAgent.sources.Twitter.accessToken = <Copy access token value from Twitter App>
- MyTwitAgent.sources.Twitter.accessTokenSecret = <Copy access token secret value from Twitter App>
- MyTwitAgent.sources.Twitter.keywords = guru99
- MyTwitAgent.sinks.HDFS.channel = MemChannel
- MyTwitAgent.sinks.HDFS.type = hdfs
- MyTwitAgent.sinks.HDFS.hdfs.path = hdfs://localhost:54310/user/hduser/flume/tweets/
- MyTwitAgent.sinks.HDFS.hdfs.fileType = DataStream
- MyTwitAgent.sinks.HDFS.hdfs.writeFormat = Text
- MyTwitAgent.sinks.HDFS.hdfs.batchSize = 1000
- MyTwitAgent.sinks.HDFS.hdfs.rollSize = 0
- MyTwitAgent.sinks.HDFS.hdfs.rollCount = 10000
- MyTwitAgent.channels.MemChannel.type = memory
- MyTwitAgent.channels.MemChannel.capacity = 10000
- MyTwitAgent.channels.MemChannel.transactionCapacity = 1000

[B]
Also, set TwitterAgent.sinks.HDFS.hdfs.path as below,
TwitterAgent.sinks.HDFS.hdfs.path = hdfs://<Host Name>:<Port Number>/<HDFS Home Directory>/flume/tweets/

To know <Host Name>, <Port Number> and <HDFS Home Directory> , see value of parameter 'fs.defaultFS' set in $HADOOP_HOME/etc/hadoop/core-site.xml

[C]
In order to flush the data to HDFS, as an when it comes, delete below entry if it exists,
TwitterAgent.sinks.HDFS.hdfs.rollInterval = 600
9. Open 'flume-env.sh' in write mode and set values for below parameters,
JAVA_HOME=<Installation directory of Java>
FLUME_CLASSPATH="<Flume Installation Directory>/lib/MyTwitterSourceForFlume.jar"

10. Start Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
11. Two of the JAR files from the Flume tar ball are not compatible with Hadoop 2.2.0. So, we will need to follow below steps to make Flume compatible with Hadoop 2.2.0.
a. Move protobuf-java-2.4.1.jar out of '<Flume Installation Directory>/lib'.
Go to '<Flume Installation Directory>/lib'
cd <Flume Installation Directory>/lib
sudo mv protobuf-java-2.4.1.jar ~/

b. Find for JAR file 'guava' as below
find . -name "guava*"

Move guava-10.0.1.jar out of '<Flume Installation Directory>/lib'.
sudo mv guava-10.0.1.jar ~/

c. Download guava-17.0.jar from http://mvnrepository.com/artifact/com.google.guava/guava/17.0

Now, copy this downloaded jar file to '<Flume Installation Directory>/lib'
12. Go to '<Flume Installation Directory>/bin' and start Flume as-
./flume-ng agent -n MyTwitAgent -c conf -f <Flume Installation Directory>/conf/flume.conf

Command prompt window where flume is fetching Tweets-

From command window message we can see that the output is written to /user/hduser/flume/tweets/ directory.
Now, open this directory using web browser.
13. To see the result of data load, using a browser open http://localhost:50070/ and browse file system, then go to the directory where data has been loaded, that is-
<HDFS Home Directory>/flume/tweets/

In this tutorial we will discuss Pig & Hive
In Map Reduce framework, programs need to be translated into a series of Map and Reduce stages. However, this is not a programming model which data analysts are familiar with. So, in order to bridge this gap, an abstraction called Pig was built on top of Hadoop.
Pig is a high level programming language useful for analyzing large data sets. Pig was a result of development effort at Yahoo!
Pig enables people to focus more on analyzing bulk data sets and to spend less time in writing Map-Reduce programs.
Similar to Pigs, who eat anything, the Pig programming language is designed to work upon any kind of data. That's why the name, Pig!

Pig consists of two components:
A Pig Latin program consist of a series of operations or transformations which are applied to the input data to produce output. These operations describe a data flow which is translated into an executable representation, by Pig execution environment. Underneath, results of these transformations are series of MapReduce jobs which a programmer is unaware of. So, in a way, Pig allows programmer to focus on data rather than the nature of execution.
PigLatin is a relatively stiffened language which uses familiar keywords from data processing e.g., Join, Group and Filter.

Execution modes:
Pig has two execution modes:
Problem Statement:
Find out Number of Products Sold in Each Country.
Input: Our input data set is a CSV file, SalesJan2009.csv
Prerequisites:
This tutorial is developed on Linux - Ubuntu operating System.
You should have Hadoop (version 2.2.0 used for this tutorial) already installed and is running on the system.
You should have Java (version 1.8.0 used for this tutorial) already installed on the system.
You should have set JAVA_HOME accordingly.
This guide is divided into 2 parts
Before we start with the actual process, change user to 'hduser' (user used for Hadoop configuration).

Step 1) Download stable latest release of Pig (version 0.12.1 used for this tutorial) from any one of the mirrors sites available at
http://pig.apache.org/releases.html

Select tar.gz (and not src.tar.gz) file to download.
Step 2) Once download is complete, navigate to the directory containing the downloaded tar file and move the tar to the location where you want to setup Pig. In this case we will move to /usr/local

Move to directory containing Pig Files
cd /usr/local
Extract contents of tar file as below
sudo tar -xvf pig-0.12.1.tar.gz

Step 3). Modify ~/.bashrc to add Pig related environment variables
Open ~/.bashrc file in any text editor of your choice and do below modifications-
export PIG_HOME=<Installation directory of Pig>
export PATH=$PIG_HOME/bin:$HADOOP_HOME/bin:$PATH

Step 4) Now, source this environment configuration using below command
. ~/.bashrc

Step 5) We need to recompile PIG to support Hadoop 2.2.0
Here are the steps to do this-
Go to PIG home directory
cd $PIG_HOME
Install ant
sudo apt-get install ant
 Note: Download will start and will consume time as per your internet speed.
Note: Download will start and will consume time as per your internet speed.
Recompile PIG
sudo ant clean jar-all -Dhadoopversion=23

Please note that, in this recompilation process multiple components are downloaded. So, system should be connected to internet.
Also, in case this process stuck somewhere and you dont see any movement on command prompt for more than 20 minutes then press ctrl + c and rerun the same command.
In our case it takes 20 minutes

Step 6) Test the Pig installation using command
pig -help

Step 7) Start Hadoop
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
Step 8) Pig takes file from HDFS in MapReduce mode and stores the results back to HDFS.
Copy file SalesJan2009.csv (stored on local file system, ~/input/SalesJan2009.csv) to HDFS (Hadoop Distributed File System) Home Directory
Here the file is in Folder input. If the file is stored in some other location give that name
$HADOOP_HOME/bin/hdfs dfs -copyFromLocal ~/input/SalesJan2009.csv /

Verify whether file is actually copied of not.
$HADOOP_HOME/bin/hdfs dfs -ls /

Step 9) Pig Configuration
First navigate to $PIG_HOME/conf
cd $PIG_HOME/conf
sudo cp pig.properties pig.properties.original

Open pig.properties using text editor of your choice, and specify log file path using pig.logfile
sudo gedit pig.properties

Loger will make use of this file to log errors.
Step 10) Run command 'pig' which will start Pig command prompt which is an interactive shell Pig queries.
pig

Step 11) In Grunt command prompt for Pig, execute below Pig commands in order.
-- A. Load the file containing data.
salesTable = LOAD '/SalesJan2009.csv' USING PigStorage(',') AS (Transaction_date:chararray,Product:chararray,Price:chararray,Payment_Type:chararray,Name:chararray,City:chararray,State:chararray,Country:chararray,Account_Created:chararray,Last_Login:chararray,Latitude:chararray,Longitude:chararray);
Press Enter after this command.

-- B. Group data by field Country
GroupByCountry = GROUP salesTable BY Country;

-- C. For each tuple in 'GroupByCountry', generate the resulting string of the form-> Name of Country : No. of products sold
CountByCountry = FOREACH GroupByCountry GENERATE CONCAT((chararray)$0,CONCAT(':',(chararray)COUNT($1)));
Press Enter after this command.

-- D. Store the results of Data Flow in the directory 'pig_output_sales' on HDFS
STORE CountByCountry INTO 'pig_output_sales' USING PigStorage('\t');

This command will take some time to execute. Once done, you should see following screen

Step 12) Result can be seen through command interface as,
$HADOOP_HOME/bin/hdfs dfs -cat pig_output_sales/part-r-00000

OR
Results can also be seen via web interface as-
Results through web interface-
Open http://localhost:50070/ in web browser.

Now select 'Browse the filesystem' and navigate upto /user/hduser/pig_output_sales

Open part-r-00000

Apache Oozie is a workflow scheduler for Hadoop. It is a system which runs workflow of dependent jobs. Here, users are permitted to create Directed Acyclic Graphs of workflows, which can be run in parallel and sequentially in Hadoop. In this tutorial we will learn,
It consists of two parts:
Oozie is scalable and can manage timely execution of thousands of workflows (each consisting of dozens of jobs) in a Hadoop cluster.

Oozie is very much flexible, as well. One can easily start, stop, suspend and rerun jobs. Oozie makes it very easy to rerun failed workflows. One can easily understand how difficult it can be to catch up missed or failed jobs due to downtime or failure. It is even possible to skip a specific failed node.
Oozie runs as a service in the cluster and clients submit workflow definitions for immediate or later processing.
Oozie workflow consists of action nodes and control-flow nodes.
An action node represents a workflow task, e.g., moving files into HDFS, running a MapReduce, Pig or Hive jobs, importing data using Sqoop or running a shell script of a program written in Java.
A control-flow node controls the workflow execution between actions by allowing constructs like conditional logic wherein different branches may be followed depending on the result of earlier action node.
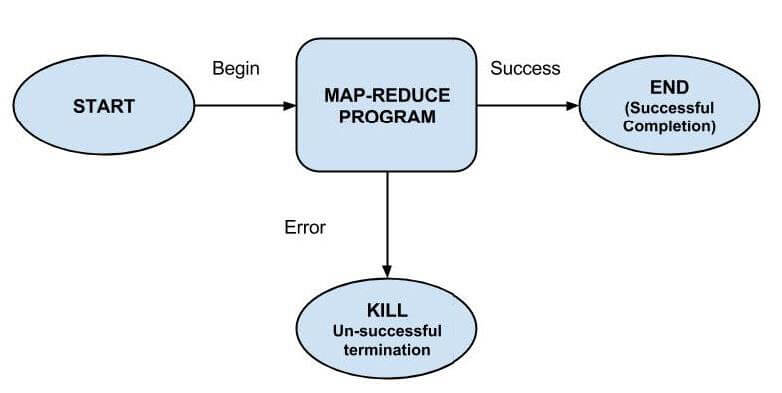
Start Node, End Node and Error Node fall under this category of nodes.
Start Node, designates start of the workflow job.
End Node, signals end of the job.
Error Node, designates an occurrence of error and corresponding error message to be printed.
At the end of execution of workflow, HTTP callback is used by Oozie to update client with the workflow status. Entry-to or exit-from an action node may also trigger callback.
A workflow application consists of the workflow definition and all the associated resources such as MapReduce Jar files, Pig scripts etc. Applications need to follow a simple directory structure and are deployed to HDFS so that Oozie can access them.
An example directory structure is shown below-
/
??? lib/
? ??? hadoop-examples.jar
??? workflow.xml
It is necessary to keep workflow.xml (a workflow definition file) in the top level directory (parent directory with workflow name). Lib directory contains Jar files containing MapReduce classes. Workflow application conforming to this layout can be built with any build tool e.g., Ant or Maven.
Such a build need to be copied to HDFS using command, for example -
% hadoop fs -put hadoop-examples/target/ name of workflow Steps for Running an Oozie workflow job
In this section we will see how to run a workflow job. To run this, we will use Oozie command-line tool (a client program which communicates with the Oozie server).
1. Export OOZIE_URL environment variable which tells the oozie command which Oozie server to use (here we’re using one running locally):
% export OOZIE_URL="http://localhost:11000/oozie"
2. Run workflow job using-
% oozie job -config ch05/src/main/resources/max-temp-workflow.properties -run
The -config option refers to a local Java properties file containing definitions for the parameters in the workflow XML file, as well as oozie.wf.application.path, which tells Oozie the location of the workflow application in HDFS.
Example contents of the properties file:
nameNode=hdfs://localhost:8020 jobTracker=localhost:8021 oozie.wf.application.path=${nameNode}/user/${user.name}/
3. Get the status of workflow job-
Status of workflow job can be seen using subcommand 'job' with '-info' option and specifying job id after '-info'.
e.g., % oozie job -info
Output shows status which is one of: RUNNING, KILLED, or SUCCEEDED.
4. Results of successful workflow execution can be seen using Hadoop command like-
% hadoop fs -cat
Main purpose of using Oozie is to manage different type of jobs being processed in Hadoop system.
Dependencies between jobs are specified by user in the form of Directed Acyclic Graphs. Oozie consumes this information and takes care of their execution in correct order as specified in a workflow. That way user's time to manage complete workflow is saved. In addition, Oozie has a provision to specify frequency of execution of a particular job.
Big data is a collection of large datasets that cannot be processed using traditional computing techniques. Testing of these datasets involves various tools, techniques and frameworks to process. Big data relates to data creation, storage, retrieval and analysis that is remarkable in terms of volume, variety, and velocity. You can learn more about Big Data, Hadoop and Mapreduce here
In this tutorial we will learn,
Testing Big Data application is more a verification of its data processing rather than testing the individual features of the software product. When it comes to Big data testing, performance and functional testing are the key.
In Big data testing QA engineers verify the successful processing of terabytes of data using commodity cluster and other supportive components. It demands a high level of testing skills as the processing is very fast. Processing may be of three types

Along with this, data quality is also an important factor in big data testing. Before testing the application, it is necessary to check the quality of data and should be considered as a part of database testing. It involves checking various characteristics like conformity, accuracy, duplication, consistency, validity, data completeness, etc.
The following figure gives a high level overview of phases in Testing Big Data Applications

Big Data Testing can be broadly divided into three steps
The first step of big data testing, also referred as pre-Hadoop stage involves process validation.
Tools like Talend, Datameer, can be used for data staging validation
The second step is a validation of "MapReduce". In this stage, the tester verifies the business logic validation on every node and then validating them after running against multiple nodes, ensuring that the
The final or third stage of Big Data testing is the output validation process. The output data files are generated and ready to be moved to an EDW (Enterprise Data Warehouse) or any other system based on the requirement.
Activities in third stage includes
Hadoop processes very large volumes of data and is highly resource intensive. Hence, architectural testing is crucial to ensure success of your Big Data project. Poorly or improper designed system may lead to performance degradation, and the system could fail to meet the requirement. Atleast, Performance and Failover test services should be done in a Hadoop environment.
Performance testing includes testing of job completion time, memory utilization, data throughput and similar system metrics. While the motive of Failover test service is to verify that data processing occurs seamlessly in case of failure of data nodes
Performance Testing for Big Data includes two main action
Performance testing for big data application involves testing of huge volumes of structured and unstructured data, and it requires a specific testing approach to test such massive data.

Performance Testing is executed in this order
Various parameters to be verified for performance testing are
Test Environment needs depend on the type of application you are testing. For Big data testing, test environment should encompass
|
Properties |
Traditional database testing |
Big data testing |
|
Data |
|
|
|
|
|
|
|
|
|
Infrastructure |
|
|
|
Validation Tools |
Tester uses either the Excel based macros or UI based automation tools |
No defined tools, the range is vast from programming tools like MapReduce to HIVEQL |
|
Testing Tools can be used with basic operating knowledge and less training. |
It requires a specific set of skills and training to operate testing tool. Also, the tools are in their nascent stage and overtime it may come up with new features. |
|
Big Data Cluster |
Big Data Tools |
|
NoSQL: |
|
|
MapReduce: |
|
|
Storage: |
|
|
Servers: |
|
|
Processing |
|
Automation testing for Big data requires someone with a technical expertise. Also, automated tools are not equipped to handle unexpected problems that arise during testing
It is one of the integral phases of testing. Virtual machine latency creates timing problems in real time big data testing. Also managing images in Big data is a hassle.
Performance testing challenges
Summary
1) What is Hadoop Map Reduce ?
For processing large data sets in parallel across a hadoop cluster, Hadoop MapReduce framework is used. Data analysis uses a two-step map and reduce process.
2) How Hadoop MapReduce works?
In MapReduce, during the map phase it counts the words in each document, while in the reduce phase it aggregates the data as per the document spanning the entire collection. During the map phase the input data is divided into splits for analysis by map tasks running in parallel across Hadoop framework.
3) Explain what is shuffling in MapReduce ?
The process by which the system performs the sort and transfers the map outputs to the reducer as inputs is known as the shuffle
4) Explain what is distributed Cache in MapReduce Framework ?
Distributed Cache is an important feature provided by map reduce framework. When you want to share some files across all nodes in Hadoop Cluster, DistributedCache is used. The files could be an executable jar files or simple properties file.
5) Explain what is NameNode in Hadoop?
NameNode in Hadoop is the node, where Hadoop stores all the file location information in HDFS (Hadoop Distributed File System). In other words, NameNode is the centrepiece of an HDFS file system. It keeps the record of all the files in the file system, and tracks the file data across the cluster or multiple machines
6) Explain what is JobTracker in Hadoop? What are the actions followed by Hadoop?
In Hadoop for submitting and tracking MapReduce jobs, JobTracker is used. Job tracker run on its own JVM process
Job Tracker performs following actions in Hadoop
7) Explain what is heartbeat in HDFS?
Heartbeat is referred to a signal used between a data node and Name node, and between task tracker and job tracker, if the Name node or job tracker does not respond to the signal, then it is considered there is some issues with data node or task tracker
8) Explain what combiners is and when you should use a combiner in a MapReduce Job?
To increase the efficiency of MapReduce Program, Combiners are used. The amount of data can be reduced with the help of combiner’s that need to be transferred across to the reducers. If the operation performed is commutative and associative you can use your reducer code as a combiner. The execution of combiner is not guaranteed in Hadoop
9) What happens when a datanode fails ?
When a datanode fails
10) Explain what is Speculative Execution?
In Hadoop during Speculative Execution a certain number of duplicate tasks are launched. On different slave node, multiple copies of same map or reduce task can be executed using Speculative Execution. In simple words, if a particular drive is taking long time to complete a task, Hadoop will create a duplicate task on another disk. Disk that finish the task first are retained and disks that do not finish first are killed.
11) Explain what are the basic parameters of a Mapper?
The basic parameters of a Mapper are
12) Explain what is the function of MapReducer partitioner?
The function of MapReducer partitioner is to make sure that all the value of a single key goes to the same reducer, eventually which helps evenly distribution of the map output over the reducers
13) Explain what is difference between an Input Split and HDFS Block?
Logical division of data is known as Split while physical division of data is known as HDFS Block
14) Explain what happens in textinformat ?
In textinputformat, each line in the text file is a record. Value is the content of the line while Key is the byte offset of the line. For instance, Key: longWritable, Value: text
15) Mention what are the main configuration parameters that user need to specify to run Mapreduce Job ?
The user of Mapreduce framework needs to specify
16) Explain what is WebDAV in Hadoop?
To support editing and updating files WebDAV is a set of extensions to HTTP. On most operating system WebDAV shares can be mounted as filesystems , so it is possible to access HDFS as a standard filesystem by exposing HDFS over WebDAV.
17) Explain what is sqoop in Hadoop ?
To transfer the data between Relational database management (RDBMS) and Hadoop HDFS a tool is used known as Sqoop. Using Sqoop data can be transferred from RDMS like MySQL or Oracle into HDFS as well as exporting data from HDFS file to RDBMS
18) Explain how JobTracker schedules a task ?
The task tracker send out heartbeat messages to Jobtracker usually every few minutes to make sure that JobTracker is active and functioning. The message also informs JobTracker about the number of available slots, so the JobTracker can stay upto date with where in the cluster work can be delegated
19) Explain what is Sequencefileinputformat?
Sequencefileinputformat is used for reading files in sequence. It is a specific compressed binary file format which is optimized for passing data between the output of one MapReduce job to the input of some other MapReduce job.
20) Explain what does the conf.setMapper Class do ?
Conf.setMapperclass sets the mapper class and all the stuff related to map job such as reading data and generating a key-value pair out of the mapper
21) Explain what is Hadoop?
It is an open-source software framework for storing data and running applications on clusters of commodity hardware. It provides enormous processing power and massive storage for any type of data.
22) Mention what is the difference between an RDBMS and Hadoop?
| RDBMS | Hadoop |
| RDBMS is relational database management system | Hadoop is node based flat structure |
| It used for OLTP processing whereas Hadoop | It is currently used for analytical and for BIG DATA processing |
| In RDBMS, the database cluster uses the same data files stored in shared storage | In Hadoop, the storage data can be stored independently in each processing node. |
| You need to preprocess data before storing it | you don’t need to preprocess data before storing it |
23) Mention Hadoop core components?
Hadoop core components include,
24) What is NameNode in Hadoop?
NameNode in Hadoop is where Hadoop stores all the file location information in HDFS. It is the master node on which job tracker runs and consists of metadata.
25) Mention what are the data components used by Hadoop?
Data components used by Hadoop are
26) Mention what is the data storage component used by Hadoop?
The data storage component used by Hadoop is HBase.
27) Mention what are the most common input formats defined in Hadoop?
The most common input formats defined in Hadoop are;
28) In Hadoop what is InputSplit?
It splits input files into chunks and assign each split to a mapper for processing.
29) For a Hadoop job, how will you write a custom partitioner?
You write a custom partitioner for a Hadoop job, you follow the following path
30) For a job in Hadoop, is it possible to change the number of mappers to be created?
No, it is not possible to change the number of mappers to be created. The number of mappers is determined by the number of input splits.
31) Explain what is a sequence file in Hadoop?
To store binary key/value pairs, sequence file is used. Unlike regular compressed file, sequence file support splitting even when the data inside the file is compressed.
32) When Namenode is down what happens to job tracker?
Namenode is the single point of failure in HDFS so when Namenode is down your cluster will set off.
33) Explain how indexing in HDFS is done?
Hadoop has a unique way of indexing. Once the data is stored as per the block size, the HDFS will keep on storing the last part of the data which say where the next part of the data will be.
34) Explain is it possible to search for files using wildcards?
Yes, it is possible to search for files using wildcards.
35) List out Hadoop’s three configuration files?
The three configuration files are
36) Explain how can you check whether Namenode is working beside using the jps command?
Beside using the jps command, to check whether Namenode are working you can also use
/etc/init.d/hadoop-0.20-namenode status.
37) Explain what is “map” and what is "reducer" in Hadoop?
In Hadoop, a map is a phase in HDFS query solving. A map reads data from an input location, and outputs a key value pair according to the input type.
In Hadoop, a reducer collects the output generated by the mapper, processes it, and creates a final output of its own.
38) In Hadoop, which file controls reporting in Hadoop?
In Hadoop, the hadoop-metrics.properties file controls reporting.
39) For using Hadoop list the network requirements?
For using Hadoop the list of network requirements are:
40) Mention what is rack awareness?
Rack awareness is the way in which the namenode determines on how to place blocks based on the rack definitions.
41) Explain what is a Task Tracker in Hadoop?
A Task Tracker in Hadoop is a slave node daemon in the cluster that accepts tasks from a JobTracker. It also sends out the heartbeat messages to the JobTracker, every few minutes, to confirm that the JobTracker is still alive.
42) Mention what daemons run on a master node and slave nodes?
43) Explain how can you debug Hadoop code?
The popular methods for debugging Hadoop code are:
44) Explain what is storage and compute nodes?
45) Mention what is the use of Context Object?
The Context Object enables the mapper to interact with the rest of the Hadoop
system. It includes configuration data for the job, as well as interfaces which allow it to emit output.
46) Mention what is the next step after Mapper or MapTask?
The next step after Mapper or MapTask is that the output of the Mapper are sorted, and partitions will be created for the output.
47) Mention what is the number of default partitioner in Hadoop?
In Hadoop, the default partitioner is a “Hash” Partitioner.
48) Explain what is the purpose of RecordReader in Hadoop?
In Hadoop, the RecordReader loads the data from its source and converts it into (key, value) pairs suitable for reading by the Mapper.
49) Explain how is data partitioned before it is sent to the reducer if no custom partitioner is defined in Hadoop?
If no custom partitioner is defined in Hadoop, then a default partitioner computes a hash value for the key and assigns the partition based on the result.
50) Explain what happens when Hadoop spawned 50 tasks for a job and one of the task failed?
It will restart the task again on some other TaskTracker if the task fails more than the defined limit.
51) Mention what is the best way to copy files between HDFS clusters?
The best way to copy files between HDFS clusters is by using multiple nodes and the distcp command, so the workload is shared.
52) Mention what is the difference between HDFS and NAS?
HDFS data blocks are distributed across local drives of all machines in a cluster while NAS data is stored on dedicated hardware.
53) Mention how Hadoop is different from other data processing tools?
In Hadoop, you can increase or decrease the number of mappers without worrying about the volume of data to be processed.
54) Mention what job does the conf class do?
Job conf class separate different jobs running on the same cluster. It does the job level settings such as declaring a job in a real environment.
55) Mention what is the Hadoop MapReduce APIs contract for a key and value class?
For a key and value class, there are two Hadoop MapReduce APIs contract
56) Mention what are the three modes in which Hadoop can be run?
The three modes in which Hadoop can be run are
57) Mention what does the text input format do?
The text input format will create a line object that is an hexadecimal number. The value is considered as a whole line text while the key is considered as a line object. The mapper will receive the value as ‘text’ parameter while key as ‘longwriteable’ parameter.
58) Mention how many InputSplits is made by a Hadoop Framework?
Hadoop will make 5 splits
59) Mention what is distributed cache in Hadoop?
Distributed cache in Hadoop is a facility provided by MapReduce framework. At the time of execution of the job, it is used to cache file. The Framework copies the necessary files to the slave node before the execution of any task at that node.
60) Explain how does Hadoop Classpath plays a vital role in stopping or starting in Hadoop daemons?
Classpath will consist of a list of directories containing jar files to stop or start daemons.

