
Users Online
· Members Online: 0
· Total Members: 232
· Newest Member: Zarfdrilhor
Forum Threads
Latest Articles
Articles Hierarchy
Hadoop Tutorial: Master BigData
What is Sqoop? What is FLUME - Hadoop Tutorial
Before we learn more about Flume and Sqoop , lets study
Issues with Data Load into Hadoop
Analytical processing using Hadoop requires loading of huge amounts of data from diverse sources into Hadoop clusters.
This process of bulk data load into Hadoop, from heterogeneous sources and then processing it, comes with certain set of challenges.
Maintaining and ensuring data consistency and ensuring efficient utilization of resources, are some factors to consider before selecting right approach for data load.
Major Issues:
1. Data load using Scripts
Traditional approach of using scripts to load data, is not suitable for bulk data load into Hadoop; this approach is inefficient and very time consuming.
2. Direct access to external data via Map-Reduce application
Providing direct access to the data residing at external systems(without loading into Hadopp) for map reduce applications complicates these applications. So, this approach is not feasible.
3.In addition to having ability to work with enormous data, Hadoop can work with data in several different forms. So, to load such heterogeneous data into Hadoop, different tools have been developed. Sqoop and Flume are two such data loading tools.
What is SQOOP in Hadoop?
Apache Sqoop (SQL-to-Hadoop) is designed to support bulk import of data into HDFS from structured data stores such as relational databases, enterprise data warehouses, and NoSQL systems. Sqoop is based upon a connector architecture which supports plugins to provide connectivity to new external systems.
An example use case of Sqoop, is an enterprise that runs a nightly Sqoop import to load the day's data from a production transactional RDBMS into a Hive data warehouse for further analysis.
Sqoop Connectors
All the existing Database Management Systems are designed with SQL standard in mind. However, each DBMS differs with respect to dialect to some extent. So, this difference poses challenges when it comes to data transfers across the systems. Sqoop Connectors are components which help overcome these challenges.
Data transfer between Sqoop and external storage system is made possible with the help of Sqoop's connectors.
Sqoop has connectors for working with a range of popular relational databases, including MySQL, PostgreSQL, Oracle, SQL Server, and DB2. Each of these connectors knows how to interact with its associated DBMS. There is also a generic JDBC connector for connecting to any database that supports Java's JDBC protocol. In addition, Sqoop provides optimized MySQL and PostgreSQL connectors that use database-specific APIs to perform bulk transfers efficiently.

In addition to this, Sqoop has various third party connectors for data stores,
ranging from enterprise data warehouses (including Netezza, Teradata, and Oracle) to NoSQL stores (such as Couchbase). However, these connectors do not come with Sqoop bundle ;those need to be downloaded separately and can be added easily to an existing Sqoop installation.
What is FLUME in Hadoop?
Apache Flume is a system used for moving massive quantities of streaming data into HDFS. Collecting log data present in log files from web servers and aggregating it in HDFS for analysis, is one common example use case of Flume.
Flume supports multiple sources like –
-
'tail' (which pipes data from local file and write into HDFS via Flume, similar to Unix command 'tail')
-
System logs
-
Apache log4j (enable Java applications to write events to files in HDFS via Flume).
Data Flow in Flume
A Flume agent is a JVM process which has 3 components -Flume Source, Flume Channel and Flume Sink- through which events propagate after initiated at an external source .
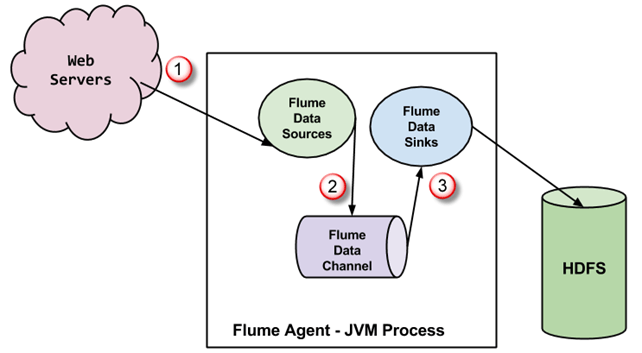
-
In above diagram, the events generated by external source (WebServer) are consumed by Flume Data Source. The external source sends events to Flume source in a format that is recognized by the target source.
-
Flume Source receives an event and stores it into one or more channels. The channel acts as a store which keeps the event until it is consumed by the flume sink. This channel may use local file system in order to store these events.
-
Flume sink removes the event from channel and stores it into an external repository like e.g., HDFS. There could be multiple flume agents, in which case flume sink forwards the event to the flume source of next flume agent in the flow.
Some Important features of FLUME
-
Flume has flexible design based upon streaming data flows. It is fault tolerant and robust with multiple failover and recovery mechanisms. Flume has different levels of reliability to offer which includes 'best-effort delivery' and an 'end-to-end delivery'. Best-effort delivery does not tolerate any Flume node failure whereas 'end-to-end delivery' mode guarantees delivery even in the event of multiple node failures.
-
Flume carries data between sources and sinks. This gathering of data can either be scheduled or event driven. Flume has its own query processing engine which makes it easy to transform each new batch of data before it is moved to the intended sink.
-
Possible Flume sinks include HDFS and Hbase. Flume can also be used to transport event data including but not limited to network traffic data, data generated by social-media websites and email messages.
